




How to Scrape Yelp Data Using Python
Founded in 2004, more than 15 years ago, Yelp is a popular American website (also an app) for customer reviews. Local businesses such as service centers, and food businesses are all listed on Yelp’s app. It also allows companies to buy advertising space on their website to reach more customers.
Businesses have options to respond to comments made by customers, both publicly and privately. One can scrape Yelp data, to understand how their competitors are doing, how the shops on a specific road are faring, and more.
We will be using our web scraper today to extract data from restaurants (mainly) that are listed on Yelp.
Where is The Code to Scrape Yelp Data?
You will be needing Python3.7 or higher on your system along with the BeautifulSoup library so that you can run this code. Having an IDE or a text editor like Atom is imperative for you to be able to edit the code, make changes to it, and run it.
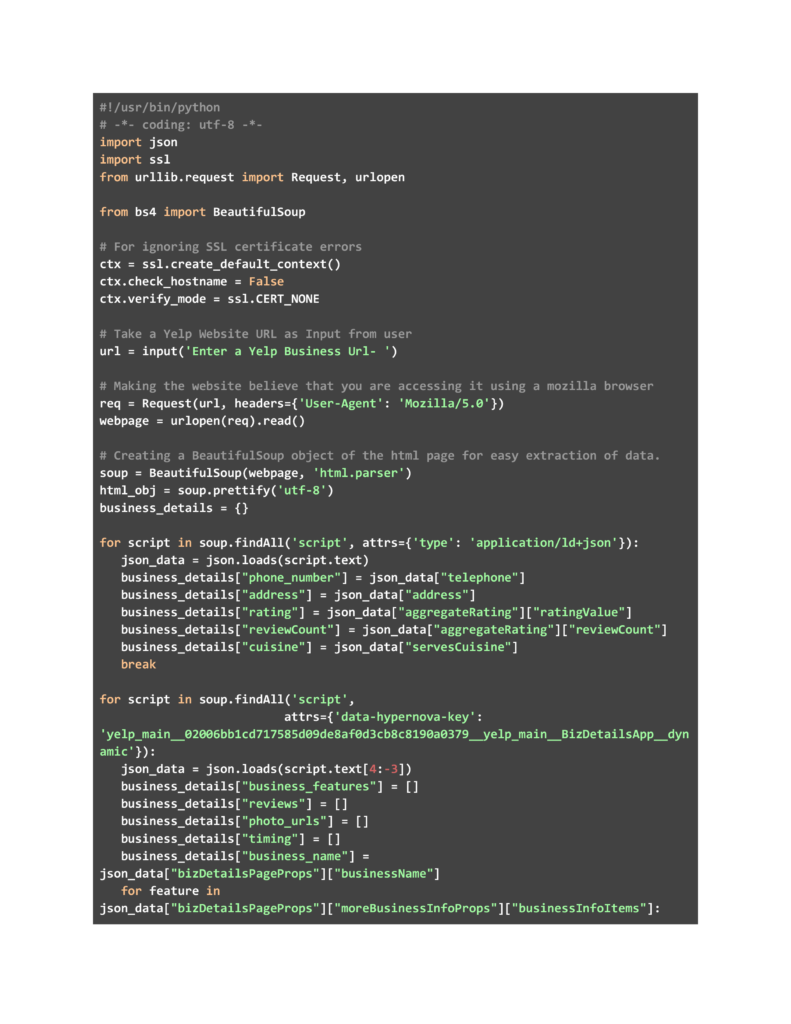
Jumping right into the code, we start with the usual — getting the imports that we need and the few lines needed for ignoring SSL certificate errors. Then we will be taking a Yelp business URL as input. For testing, we used the URL shown below.

Once you enter the business URL, we will be making an HTTP call and adding Mozilla as the user agent in our header to avoid being blocked by the website. We will be extracting the HTML content and converting it to a BeautifulSoup object for easier parsing. We have extracted the first script tag with the attribute ‘type’ having the value ‘application/ld+json’.
Then we remove the text from it and are able to get multiple data points like phone number, ratings, and address from this data blob. We also extract another script tag with attribute ‘data-hypernova-key’ with value ‘yelp_main__02006bb1cd717585d09de8af0d3cb8c8190a0379__yelp_main__BizDetailsApp__dynamic’.
The second blob gives us many more data points like user reviews, images, timings, and special features of the business. It is important to note that one needs to manually analyze the HTML page for a single business, to understand which tags need to be extracted and what data points they contain. It is only after that analysis that we understood which BeautifulSoup tags to use.
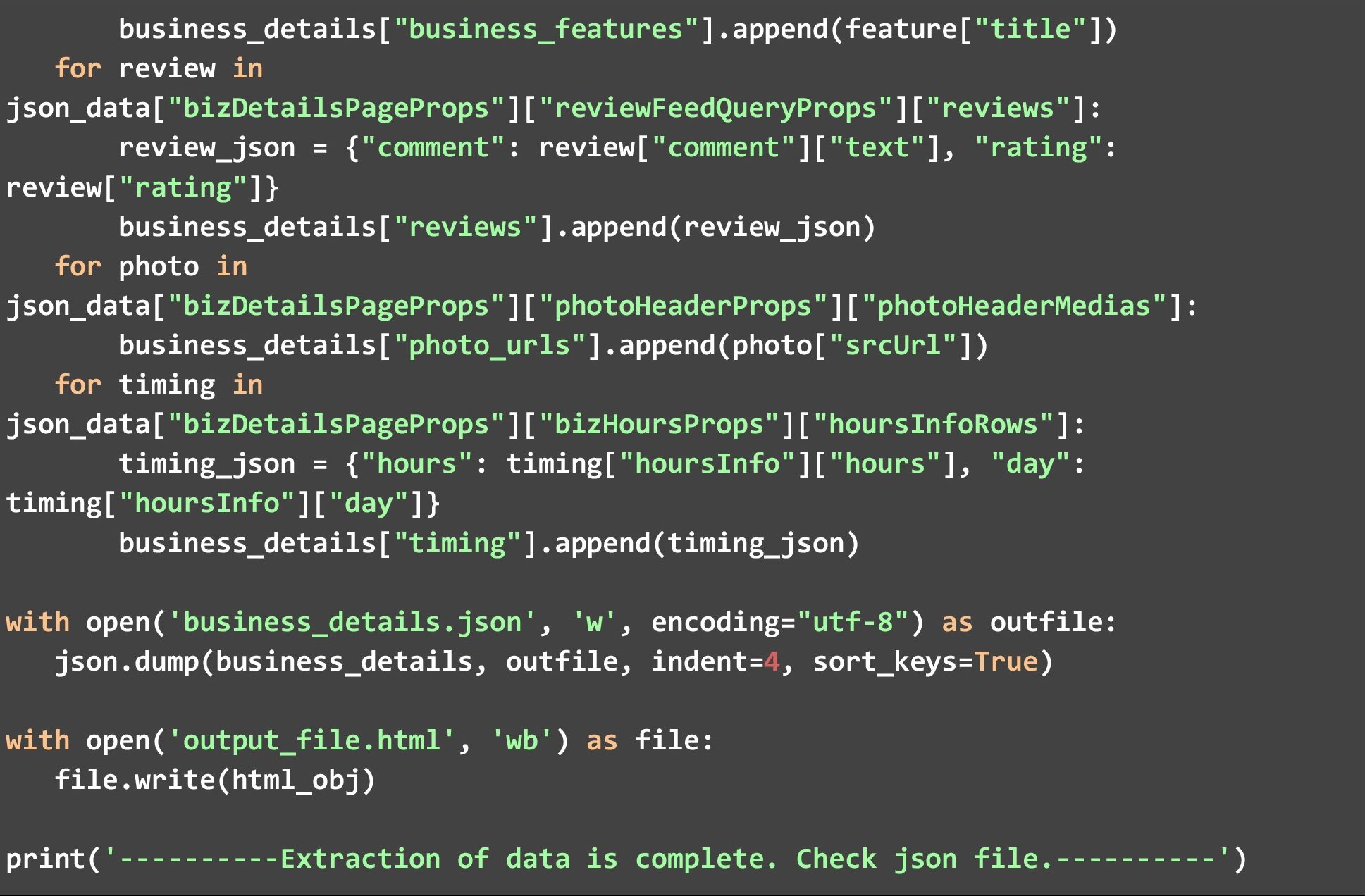
Once all the data points have been extracted from the two blobs, we save the final dict in a JSON file with the name “business_details.json”. You can also run this code on multiple Yelp webpages but you will need to create a looping mechanism for that and also append the data for each to an array.
Understanding The Output
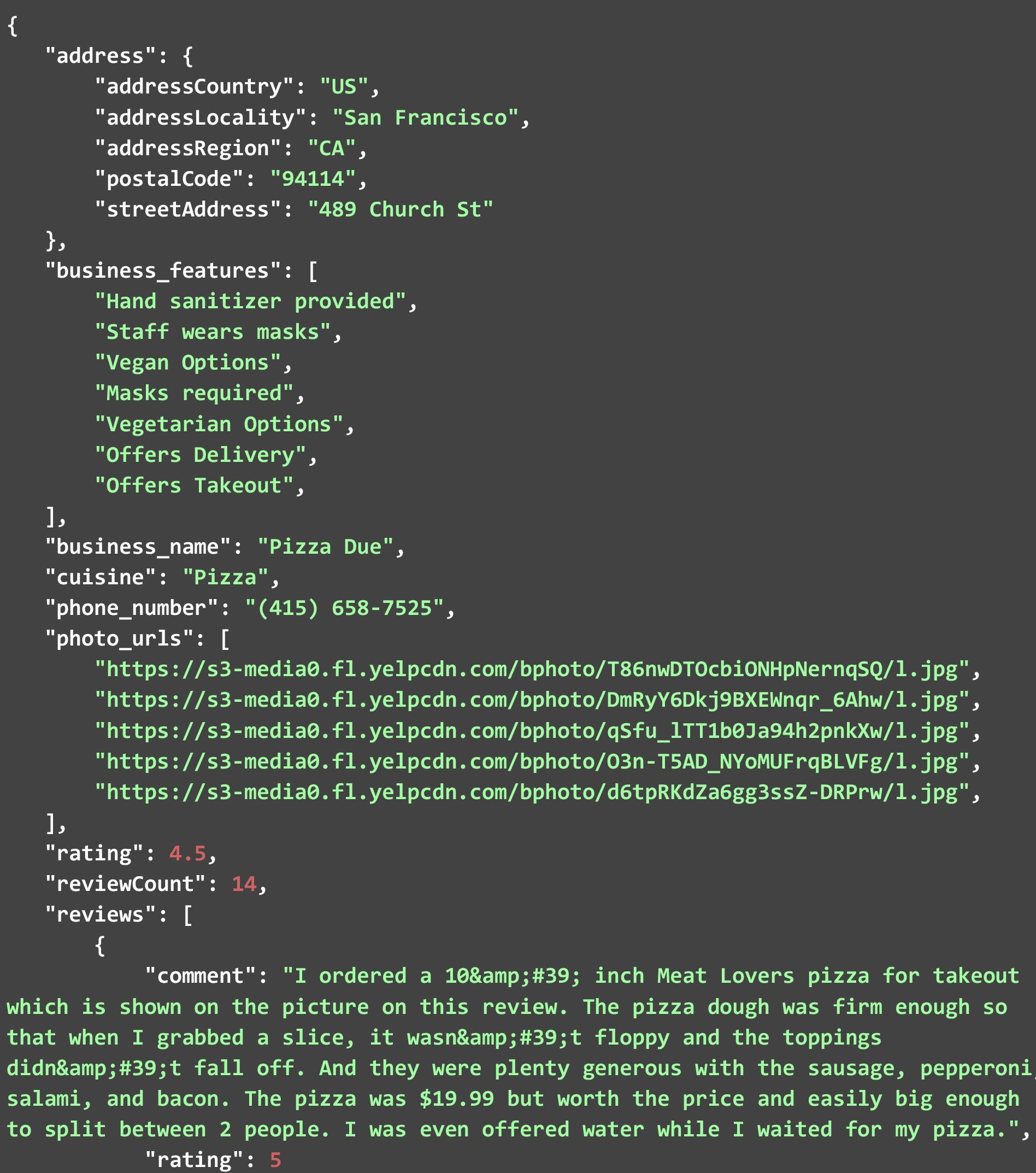
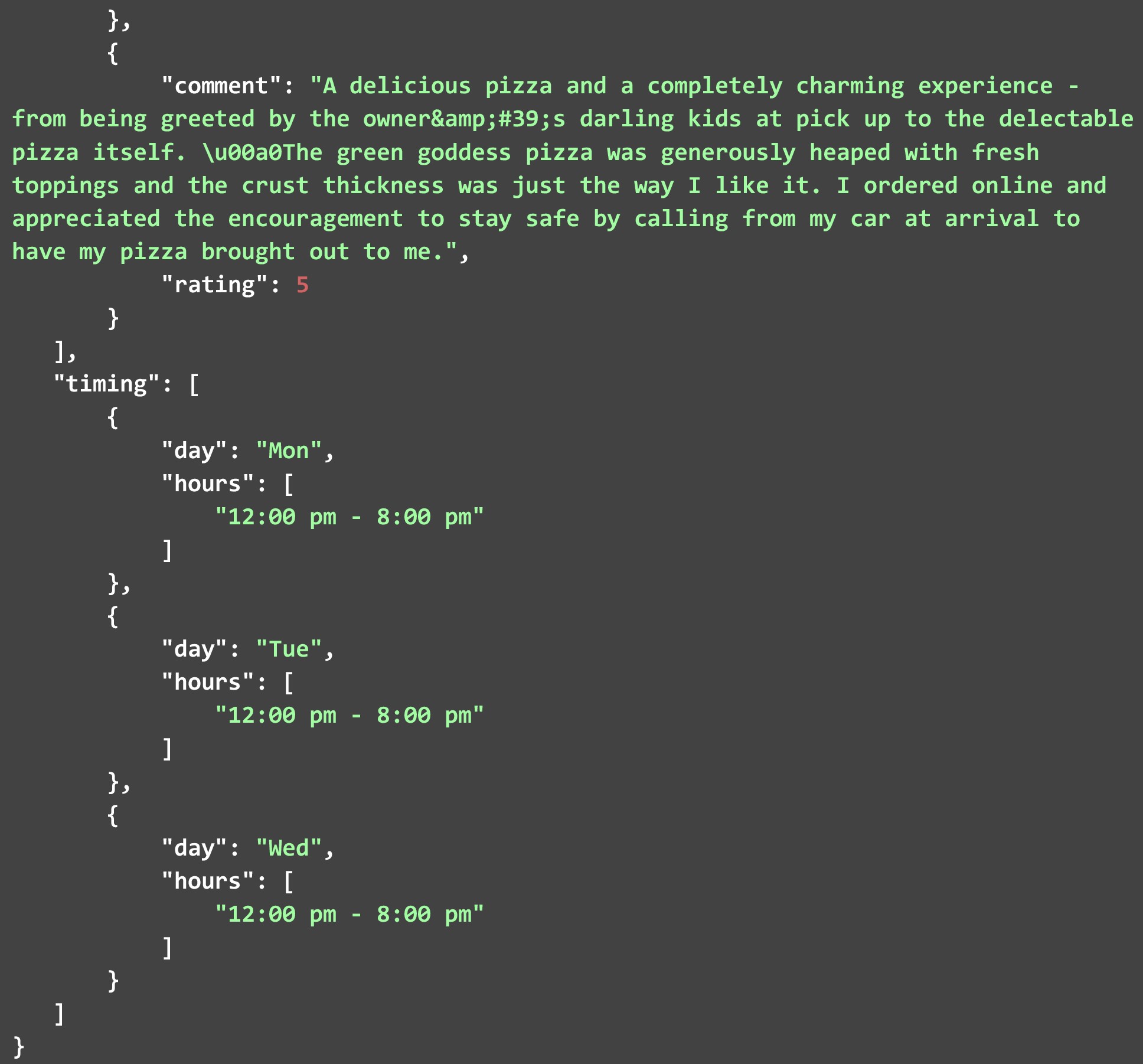
The JSON file given below is the one that was generated when we ran the code and gave the link that we showed initially. One thing to note is that we trimmed the actual JSON that got generated to fit it in this document. We removed some “business_features”, “photo_urls”, and “reviews” and retained timings only for Monday, Tuesday, and Wednesday. You can run the code on your local system to view the entire JSON file generated.
You can see that we have the following data points at our disposal.
- Address
- Business Features
- Business Name
- Cuisine
- Phone Number
- URLs for Photos
- Reviews
- Number of Reviews
- Ratings
- Timings
The address block has multiple data points within itself, such as:
- Country
- Locality
- Region
- Postal Code
- Street Address
The timing part is a little different since it contains an array with multiple dicts, where each dict contains the day of the week and the timings for it. Each review contains the comment made by the reviewer as well as the rating that he or she provided.
With so many data points at hand, you can easily indulge in all types of analysis. You can conduct sentiment analysis on the reviews. Or get the mean and median ratings for restaurants at a location and more.
The Limitations of Scraping Yelp Data In-house
Almost all DIY code has some limitations, and so does this. You cannot expect this code to scrape any webpage. It is likely to work only in restaurants. Instances, where data points may be missing for some webpages, may break this code if you do not add proper exception handling wherever data has been accessed from the two blobs. In the comments section (especially), the text may contain some characters not converted from HTML to UTF. Handling these is also an issue that you can face on a large scale when scraping multiple webpages.
Since businesses face all these and more hassles when trying to scrape data on their own and engrave data-driven decisions into business models, our team at PromptCloud offers data as a service. No hassle, only data.















