




**TL;DR**
Retrieval Augmented Generation (RAG) is gaining traction as a powerful way to make Large Language Models (LLMs) more accurate and context-aware. But one piece often gets ignored in the rush to build smarter systems: where your model gets its external information.
RAG depends heavily on fresh, reliable, and well-structured content from the web. Yet most teams don’t have a scalable method to gather this kind of data. This is where a web scraping service provider makes all the difference. Without it, even the best AI stack risks pulling in stale or irrelevant content.
At PromptCloud, we’ve seen firsthand how timely and tailored data can improve the real-world performance of AI systems. If you’re serious about deploying RAG in production, your pipeline needs more than great retrieval; it needs a strong, scalable data source behind it.
Why RAG Needs More Than Just a Smart Model
There’s been a lot of energy around Retrieval Augmented Generation (RAG) lately—and for good reason. It gives language models the ability to look beyond their pre-trained knowledge, reaching out to external sources for up-to-date, relevant information. That’s a big leap forward.
Naturally, most of the attention has gone toward model selection and retrieval architecture. Engineers are refining how documents are fetched. Teams are testing vector databases and comparing embedding models. The technical depth here is rich, and the progress is exciting.
But here’s the catch, while these parts of the stack get all the love, the quality of the data being retrieved is often treated like an afterthought.
And that’s risky.
Even the most advanced retriever can only work with what it’s given. If the information in your knowledge base is out of date, poorly structured, or irrelevant to the queries your users are asking, then the model’s output will suffer. It might sound fluent, but it won’t be helpful—or worse, it’ll be confidently wrong.
This is where a deeper question starts to matter: Where is this external data coming from, and how reliable is the process behind it?
That’s the part many teams miss. They focus on the retrieval mechanism but overlook the source of truth it’s pulling from. And in real-world deployments, that gap becomes painfully obvious.
A RAG pipeline is only as strong as the data it retrieves. So if you’re not feeding it timely, trustworthy, domain-specific information, you’re limiting its full potential. That’s why we believe a scalable web scraping service provider isn’t just a nice-to-have—it’s the missing link in many RAG stacks today.
What is Retrieval Augmented Generation and Why It Matters for Modern AI
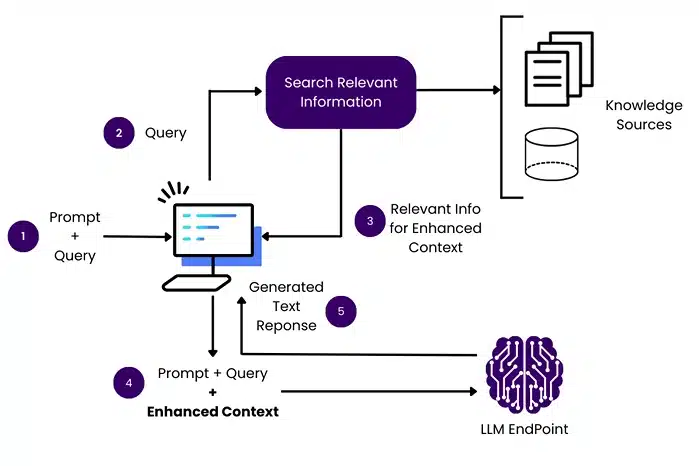
Image Source: acorn.io
Anyone working with large language models knows they have a blind spot: they stop learning the moment their training ends. No matter how advanced the model is, it can’t access anything that happened after its last update. That makes it tricky for applications that rely on current, ever-changing information.
That’s where Retrieval Augmented Generation (RAG) steps in.
In most setups, a language model can only answer questions using what it already knows, basically, whatever it learned during training. But a RAG system does things a little differently. When a question comes in, it looks outside the model’s brain, so to speak. It pulls in helpful information from other sources, whether that’s a set of company documents, a live website, or some internal archive. When you throw in fresh info, the model gets a little extra background to work with, so it can give you a reply that fits the question better.
Picture it like slipping the model a speedy set of flashcards right before it starts talking, basically a little mini cheat sheet loaded with the key stuff it should remember right then.
This design makes RAG incredibly valuable in fields where accuracy and timeliness matter. In healthcare, for instance, clinical assistants are using RAG to combine real-time research updates with patient history. In law, firms are applying it to sort through thousands of rulings and match them with case notes. Retailers are embedding RAG into chatbots to help customers navigate fast-changing product catalogs.
But here’s the catch: A RAG setup can’t outperform the quality of the data it brings in. If the material it pulls from is old, off-topic, or just too thin, then even the most carefully built pipeline won’t deliver the results you want. That’s why, beyond the tech stack and model tuning, you need to pay attention to where your data is coming from and how often it’s refreshed.
So yes, the model matters. So does the retriever. But in the end, the information being retrieved might be the single most important factor in how well the system performs.
The Role of Fresh, Domain-Specific Data in a RAG Pipeline
Good Retrieval with Bad Data Still Fails
Here’s a hard truth many teams discover too late: you can have a well-designed retrieval system, and still end up with poor results. The reason? Your model is only as good as the material it retrieves.
This happens more often than you’d think. A team spends weeks refining embeddings and tuning the retriever. They run tests, tweak parameters, and get things technically sound. But when they put it in front of users, something feels off. Answers are generic. Sometimes, even incorrect.
And it’s not because the model can’t reason—it’s because it’s working with the wrong content.
Your Data Has to Keep Up
Take a look at the kind of data your system is using right now. How recent is it? In some industries, a few weeks of lag can make a difference. In others, even a day can throw things off.
Let’s say you’re running a RAG pipeline for an investment research tool. If it’s not pulling in the latest filings, news, or market activity, users will catch that quickly. The model might still sound confident, but that’s not the same as being correct.
Outdated data is one of the most common reasons users lose trust in AI systems. Once that trust drops, even solid technical performance doesn’t matter much.
Off-the-Shelf Sources Often Miss the Point
Another common pitfall is leaning on generic data. There’s nothing wrong with scraping popular public sites to start, but they don’t go deep enough.
Imagine you’re building a product advisor for specialty electronics. Sure, you can pull product specs from manufacturer sites. But if your customers are asking nuanced questions about compatibility, repair history, or firmware quirks, you’ll need much more detailed information—likely from community forums, support threads, or independent reviews. And those aren’t always easy to access.
General sources tend to skim the surface. They give you breadth, but not the depth real-world use cases demand.
You Can’t Fix This Later
Some teams assume they can go back and improve their data later. First, they focus on the model; then they’ll worry about sourcing better documents. The problem is, that approach turns the data layer into a bottleneck. And it’s not a quick fix.
If your system started out packed with flimsy content, you’re most likely going to have to rebuild parts of it to fit better, stronger, and more specialized info. That equals more cash out of your pocket, longer timelines, and a lot of work that ends up feeling pointless.
In our experience, the best RAG setups are the ones that treat data quality as a core part of the design, not just something you plug in afterward.
Why Web Scraping is the Backbone of AI-Driven Retrieval
Getting the Right Data Isn’t as Simple as It Sounds
It’s one thing to say your RAG pipeline needs fresh, domain-specific data. It’s another thing to get that data consistently.
Most of the information teams need lives on the open web, scattered across thousands of sources. It’s unstructured, messy, and constantly changing. You’ve got price updates, shifting product specs, new articles, edited documentation, forum threads, social reviews—the list goes on.
Some of it updates daily. Some of it disappears without warning. And most of it doesn’t come in neat formats that fit into your knowledge base.
This is where web scraping starts to matter—not as an afterthought, but as the engine behind your entire retrieval pipeline.
Scraping Feeds the System with What the Model Can’t Learn on Its Own
Large language models (LLMs) are trained on static data. They don’t see what’s happening right now. Scraping, when done well, fills that gap. It lets your system pull in content the model would never “know” otherwise, because it didn’t exist during training.
Let’s say you’re building a shopping assistant that compares real-time prices across retailers. You can’t rely on old product feeds or months-old data dumps. You need to track what’s actually in stock, what’s changed, and what competitors are offering—right now.
That information doesn’t live in a neat API. It’s on websites, tucked inside JavaScript-rendered pages, updated minute by minute. Scraping is how you reach it.
Doing It In-House Is Harder Than Most Teams Expect
Some engineering teams try to handle scraping on their own. In theory, it sounds straightforward. Write a crawler. Fetch some HTML. Parse what you need.
But at scale, it gets complicated quickly. Websites use rate limits. Some hide their content behind logins or dynamic rendering. Others change their layouts constantly, breaking your scripts without warning.
Then there’s the question of volume. Can your internal tools handle thousands of URLs per day, with reliable uptime and smart failure handling? Can they adapt if a site adds CAPTCHA or blocks known crawler behavior?
Most teams find out the hard way that scraping isn’t just about code—it’s about infrastructure, monitoring, maintenance, and compliance.
Scraping Powers Retrieval; But Only if It’s Done Right
If your retrieval system is meant to surface useful content, the quality of your scraped data matters. Scraping isn’t just about collecting raw text. You need structured, usable content: clean metadata, clearly labeled sections, and consistent formatting. Otherwise, your retriever won’t be able to find the right chunks—or worse, it’ll return noise.
A well-designed scraping layer acts like a real-time, ever-expanding data supply. It fills your knowledge base with current, relevant information that your retriever can index and your model can reason over. Without it, you’re left with stale data or patchy coverage.
That’s why in RAG pipelines that perform in production, scraping isn’t optional; it’s foundational.
The Missing Link? Scalable Web Scraping Service Providers
You Can Build It Yourself. But Should You?
Some teams, especially at early stages, consider building their web scraping stack. It’s tempting. There are libraries, tutorials, and tools that make it look pretty manageable at first. And for small-scale tasks—grabbing a few pages here and there—it might be enough.
But things start to fall apart when you try to do this at scale.
When you’re dealing with hundreds or even thousands of websites, you’re not just managing scrapers. You’re dealing with rotating proxies, headless browsers, dynamic content rendering, frequent layout changes, geolocation restrictions, and anti-bot defenses. It quickly turns into a full-time job, or worse, a job you didn’t hire for.
Add to that compliance, logging, QA, retry logic, and data formatting, and you’re no longer running a few scripts. You’re maintaining an entire infrastructure layer.
This is where the value of a web scraping service provider becomes clear—not as a vendor, but as a core operational partner.
Scale, Speed, and Specialization Matter
RAG models aren’t slow-moving research projects. Once they’re live, they often support real-time applications. Users expect fast, accurate, and current responses. That means the backend needs to be both scalable and dependable.
A good scraping provider doesn’t just “get the data”—they help you get the right data, in the format you need, at the speed your application requires.
And when your needs evolve—maybe you start tracking more regions, new data types, or additional websites—you shouldn’t have to rebuild everything from scratch. The provider should be able to scale with you, without disrupting your workflow.
There’s also something to be said for specialization. Providers who do nothing but data extraction bring hard-won knowledge to the table. They know how to handle anti-scraping defenses, how to structure unstructured content, and how to keep the whole pipeline running smoothly day after day.
Trying to replicate that in-house means pulling time and talent away from your core product. And for most teams, that tradeoff just doesn’t make sense.
Closing the Gap Between Ambition and Execution
A lot of AI teams today are building ambitious RAG-based tools. They’re designing smart pipelines, exploring new architectures, and pushing boundaries on what LLMs can do.
But many of those same teams are limited by something simple: they don’t have access to the data their system needs to shine.
A scalable web scraping provider closes that gap. It removes the operational headaches of data sourcing and gives your team the fuel it needs to make the AI perform, not just in demos, but in the hands of real users.
If your RAG pipeline isn’t delivering what it should, the problem might not be your model. It might be your data. And the fastest way to fix that is to work with someone who can get you the right content, fast, and at scale.
How PromptCloud Fits Into the RAG Ecosystem
Not Just Scraping: A Full Data Pipeline That Works at Scale
When it comes to supporting Retrieval Augmented Generation, scraping isn’t just about pulling pages from websites. You need a consistent, reliable pipeline that fetches, cleans, and delivers structured content your retrieval layer can actually use. That’s the space where PromptCloud operates—not just as a scraping vendor, but as a data delivery partner for real-world AI systems.
We work with teams building everything from customer-facing chatbots to complex enterprise tools powered by LLMs. What they have in common is the need for timely, accurate, domain-specific content—and a dependable way to keep that content fresh over time.
PromptCloud handles the heavy lifting so your team can stay focused on the model, not the data plumbing.
Custom Workflows for Every Domain and Use Case
Not all projects need the same kind of data. A legal research assistant might need summaries from court databases. A travel recommender might rely on scraped reviews, hotel descriptions, and weather updates. A fintech assistant might need pricing data, earnings reports, and SEC filings.
We don’t believe in one-size-fits-all solutions. With PromptCloud, every project is treated as a unique workflow. We tailor our crawlers and pipelines to match your domain, your structure, and your update frequency—whether that’s once a day or every fifteen minutes.
Our systems are built to support high-volume, real-time data acquisition, with full logging, QA, and retry handling baked in. You define what you need. We deliver it clean, structured, and ready for retrieval.
Seamless Integration with Your Retrieval Layer
One of the challenges we often hear from AI teams is that scraping services don’t always think in terms of machine learning workflows. We do.
That’s why PromptCloud’s output can be aligned with the needs of your RAG stack from day one. We help you shape the data not just for human readability, but for retrievability—cleaned chunks, metadata tagging, timestamping, and consistent formatting so your vector store can ingest it without extra steps.
And because we’re API-first, the integration is straightforward. We fit into your existing tooling without making you redesign your stack just to get access to the data.
Your AI Is Only as Good as the Data Behind It
At the end of the day, we know what matters most is performance. Users don’t care how clever your retrieval system is—they care whether it answers their question with clarity and confidence.
The only way to make that happen is with reliable, relevant, up-to-date content. That’s what PromptCloud brings to the table.
If you’re building with RAG and you’re serious about scale, you don’t just need data. You need infrastructure for web data that never stops evolving. That’s where we come in.
The Business Case – Web Scraping for AI Training Data & Retrieval
There’s a growing assumption that once you’ve set up a RAG pipeline, you’re automatically getting smarter answers. That’s not always true. Retrieval is only as valuable as the data sitting behind it. And too often, teams forget to ask where that data is coming from—or whether it’s actually good enough.
When the content is weak, the model has nothing solid to work with. And when the model starts serving vague or outdated responses, users begin to tune out. It’s hard to recover from that kind of trust gap.
Investing in quality data isn’t just about technical completeness. It’s about real-world impact. It’s about how your AI behaves when the stakes are high and expectations are even higher.
Better Data Means Better Results And Faster Time to Value
Think about how much effort goes into getting an LLM product ready for production. From model evaluation to retrieval tuning, prompt testing to latency optimization—it adds up fast. But even with all that effort, if your source content is unreliable, you’ll keep running into edge cases and failure modes that drag everything down.
High-quality, domain-specific data gives your team fewer bugs to chase, fewer hallucinations to explain, and fewer guardrails to hack together. It gets you to real performance, faster.
For enterprise teams, this translates to faster pilot launches, more meaningful POCs, and fewer disappointing demos. It also improves ongoing feedback loops. When your AI tool gives consistently relevant answers, user engagement grows. And with more engagement comes more data, creating a virtuous cycle of improvement.
Training Data and Live Retrieval: Both Benefit From Scraping
Web scraping isn’t just useful for the retrieval side. Many teams working with LLMs also need curated datasets to fine-tune models or evaluate prompts. In both cases, scraping can provide exactly the right material, especially when you need to supplement underrepresented domains.
For example, a startup building a legal AI might collect recent court decisions for retrieval, but also use them as supervised examples to refine model behaviour. A chatbot built for airlines could first study piles of copied FAQs, then go out online to grab the latest info and handle policy questions as they pop up.
Pick a solid data partner, and scraping feeds the model practice info and real answers at the same time, so the training and the live world end up speaking the same language.
The ROI Is Clear and Often Immediate
Once teams switch from generic datasets to curated, scraped content, the difference is noticeable almost immediately. Answers become sharper. Fewer fallbacks are needed. Systems feel more intelligent—not because the model changed, but because the data got better.
Deploying large-scale scraping frameworks involves upfront resource allocation, yet the returns materialize rapidly. This is particularly critical for operationalizing AI models, where marginal enhancements in dataset quality translate directly to significant financial benefits. These benefits manifest in diminished human quality assurance, compressed development timelines, and decreased maintenance and operational support.
Given the substantial investments required to design, train, and iterate on AI systems, the argument for superior, continuously refreshed training data effectively justifies itself.
Don’t Let Bad Data Hold Back a Great Model
There’s a lot of energy going into Retrieval Augmented Generation right now—and for good reason. It opens the door to smarter, more adaptive AI applications. But even the most advanced RAG stack can’t deliver its full potential if it’s being held back by poor data.
Think about how much effort goes into crafting a high-performance AI system. You’ve got model selection, retriever optimization, infrastructure tuning, and latency considerations. All of that can be undermined if the system is retrieving stale, shallow, or irrelevant information.
What powers a RAG model is the data it draws from. That’s why more and more engineering and product teams are realizing they can’t treat web data as an afterthought. They need to source it well, maintain it at scale, and ensure it reflects the reality their users live in.
And that’s exactly where a web scraping service provider makes the difference.
With PromptCloud, you don’t just get a scraper. You get a partner who understands how critical data is in AI workflows. We specialize in sourcing structured, domain-specific, real-time content delivered in formats that plug straight into your retrieval layer or training pipeline.
When the model is sound, avoid permitting suboptimal data to compromise its potential. Whether introducing a nascent retrieval-augmented generation pipeline or expanding a mature implementation, a critical inquiry endures: is the corpus beneath the system aligned with its caliber?
Ultimately, even the most advanced architecture requires a knowledge base capable of sustaining its intellectual reach.
FAQs:
1. What is Retrieval Augmented Generation in AI?
It’s a way to make large language models smarter without retraining them every time new information comes out. Instead of relying only on what the model already “knows,” RAG lets it look things up from outside sources—kind of like how we Google something before answering. It grabs useful content first, then uses that to help form a more accurate reply. That makes it more flexible and much better at keeping up with current stuff.
2. How does web scraping support LLMs and RAG pipelines?
Most of the valuable content on the internet isn’t just sitting there waiting in a clean dataset. It’s tucked away inside websites, scattered across different formats and platforms. Scraping is how you go and collect all that information in a structured way. For RAG, this matters a lot—because if your system can’t fetch the right info when it needs it, the model’s going to end up answering based on old or incomplete knowledge.
3. Why is real-time data important for AI applications?
Because things change, sometimes fast. Let’s say you’re building a financial assistant or a tool that tracks policy updates. If your AI is working with data from last quarter, it’s probably going to miss something important. Even in retail or support, product availability or return policies can shift week to week. If you want the answers to feel reliable and relevant, the data behind them has to be current.
4. What are the challenges in building an in-house web scraping system?
It usually starts simple maybe one or two sites, a basic crawler. But then pages start breaking, sites throttle your traffic, and suddenly you’re spending time on proxy management, error handling, and keeping scripts from falling apart every time a layout changes. It’s not that teams can’t do it, it’s just a constant maintenance job. Most don’t realize how much effort it takes until they’re buried in it.
5. How can PromptCloud help with AI training and retrieval data?
We take care of the messy, behind-the-scenes work of getting you high-quality, structured web data on your schedule, in your format, and from the sources that actually matter to you. Whether it’s for training your model or feeding a live RAG pipeline, we help you keep your data fresh and relevant without your team needing to build or maintain a full scraping setup. Basically, we handle the plumbing so you can focus on the product.















