




**TL;DR**
If you’re comparing Playwright and Puppeteer for web scraping, here’s the deal. They both let you control browsers with code and scrape what’s on the page, but they’re not quite the same under the hood.Puppeteer is simpler. It runs on Node.js, works great with Chrome, and is honestly perfect if you’re not dealing with anything too wild. Want to scrape some pages that don’t go crazy with JavaScript? Puppeteer will get you there quickly.
Playwright is more flexible. It supports multiple browsers, works in other languages like Python, and handles trickier stuff better, like CAPTCHAs, login flows, or pages that load content after five scrolls and a button click. It’s heavier, but more powerful.
We use both at PromptCloud, depending on what our clients need scraped. If it’s high-volume, dynamic, and not playing nice? Nine times out of ten, we reach for Playwright.
Why Web Scraping Needs the Right Tools
Scraping the modern web isn’t what it used to be. A few years ago, you could get away with sending a few HTTP requests, parsing some HTML, and calling it a day. Now? Not so much.
Websites today are built with JavaScript-heavy frameworks. Data loads on scroll. Pages change after user actions. You’ve got CAPTCHAs, login walls, rate limits, and sometimes full-blown SPAs (Single Page Applications) standing between you and the content you need.
Some sites just don’t give up their data easily. You can forget about old-school scrapers that just fetch raw HTML. That kind of thing breaks fast when the site uses JavaScript to load content after the initial page load. These days, you need something that can behave more like a real browser. That’s where tools like Playwright and Puppeteer come in. They spin up an actual browser behind the scenes, so you can load the page, let all the scripts run, click through a few things if needed, and only then pull the data, once it’s actually visible. For a lot of modern websites, this is the only practical way to get anything usable without running into a wall.
But here’s the thing: while Playwright and Puppeteer do a lot of the same things, they’re not interchangeable. They have different strengths, different limitations, and choosing the right one can save you hours of debugging, or cost you if you choose wrong.
This article breaks it all down. If you’re building your own scrapers, leading a data team, or thinking about working with a partner like PromptCloud for web scraping solutions, knowing how these two tools stack up will help you make a smarter call.
What Is Puppeteer? The Lightweight Web Scraping Tool from Google
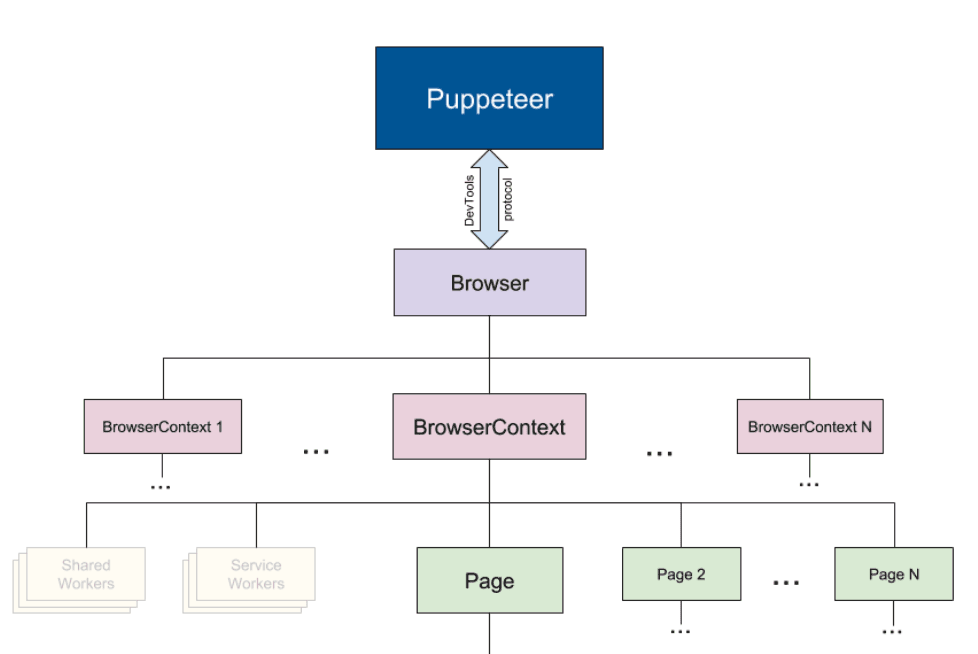
Image Source: Aymen-Loukil
Puppeteer came out of Google’s dev team as a way to control Chrome using JavaScript. That’s it. It spins up a headless browser, lets you interact with the page, and gives you back the rendered content. It’s built for automation, but a lot of developers started using it for web scraping—and for good reason.
If you’re already in Node.js, you can just install Puppeteer and be messing with a browser in five minutes. It’s basically: open page, wait a sec, pull the stuff you need. That’s it. For sites that don’t throw up too many obstacles—no login walls, no weird dynamic content—Puppeteer just works.
A lot of devs like it because it’s not bloated. You’re only working with Chromium, which keeps things predictable. It’s also backed by the same people building Chrome, so support is tight. For small projects or scrapers running on a schedule, this simplicity is a strength.
Where it starts to fall short is when you’re scraping sites that don’t behave nicely. Things like CAPTCHAs, pages that load content after a click, or sites that block automation tools—Puppeteer can struggle. You can work around some of this, but it takes effort. And if you’re working at scale, those workarounds don’t always hold up.
Still, for a lot of use cases—price tracking, static page scraping, dashboards behind basic auth—Puppeteer is more than enough. It’s reliable, it’s lightweight, and it does one job really well: controlling Chrome through JavaScript.
What Is Playwright? Microsoft’s Answer to Advanced Web Automation
Image Source: Lambdatest
Playwright was built by a few engineers who originally worked on Puppeteer. When they moved to Microsoft, they took everything they’d learned and built something more flexible, more robust, and honestly, better suited for today’s web.
At its core, Playwright does what Puppeteer does—it controls a browser in code. But it goes further. It doesn’t just work with Chrome. It supports Firefox, WebKit (the engine behind Safari), and yes, still Chromium. And it doesn’t lock you into Node.js either. You can use Python, Java, or C#, depending on what your team’s already working with.
Where Playwright really shines is in handling the messier parts of web scraping.
Got a page that loads content after five seconds, two button clicks, and an AJAX call? Playwright can deal with that. Need to scrape behind a login wall or solve a CAPTCHA? You’ve got more options. It behaves more like an actual person using the site. You can wait for things to load properly, catch network calls as they happen, and dig into responses without needing extra hacks.
It’s heavier than Puppeteer. No doubt. There’s more overhead, and your setup might take a bit longer. But you’re trading that for control, especially on websites that aren’t built to play nice with bots.
If you’re running high-volume scrapers, dealing with modern frontend frameworks like React or Angular, or need scraping to work when things get weird, Playwright is built for that. And it holds up well under load, which is why teams building serious web scraping solutions often pick it over Puppeteer.
Playwright vs Puppeteer: A Feature-by-Feature Breakdown That Actually Matters
If you’re choosing between Playwright and Puppeteer, don’t waste time comparing things that sound good on paper but won’t help you in real scraping scenarios. Here’s what actually counts when you’re building something that needs to pull data from the wild.
Browsers
Puppeteer’s locked to Chromium. That works most of the time, but some sites behave differently in Firefox or Safari. If you ever need to debug something browser-specific, you’ll hit a wall.
Playwright handles Chromium, Firefox, and WebKit. That’s a plus if you care about how a site renders outside of Chrome, or if you’re testing edge cases.
Programming Language
Puppeteer is JavaScript only. If you’re already working in Node.js, great. But if your stack is Python or something else, using Puppeteer means building a bridge just to run your scrapers.
Playwright works with JavaScript, Python, Java, and .NET. So if your team already lives in Python—which a lot of data teams do—you’re not stuck trying to duct tape Node.js into your pipeline.
JavaScript-Heavy Pages
Sites built on React, Vue, or Angular don’t just serve static HTML. They load content after the page shows up, and sometimes only after user actions. Puppeteer can deal with this, but you’ll need to write logic to wait for elements or manually trigger things.
Playwright handles this better. It’s got smarter defaults when it comes to waiting for content, and fewer “why is this element still null” moments. It’s not magic, but it feels smoother when the page gets complicated.
Logins, CAPTCHAs, and Nonsense
Neither tool “solves” CAPTCHAs, but Playwright gives you more ways to mimic a real user. You can switch user agents, spoof devices, run multiple sessions cleanly, and better control browser behavior.
If you’re trying to log into a site and pull data from behind a wall, Playwright is less of a fight. Puppeteer can do it too—it just feels more brittle.
Scraping at Scale
You can scale both tools, but Puppeteer takes more effort. You’ll be juggling browser instances, trying not to leak memory, and dealing with more orchestration work.
Playwright handles scale better out of the box. You can spin up multiple contexts in a single browser instance without everything stepping on each other. For scraping lots of pages at once, that matters.
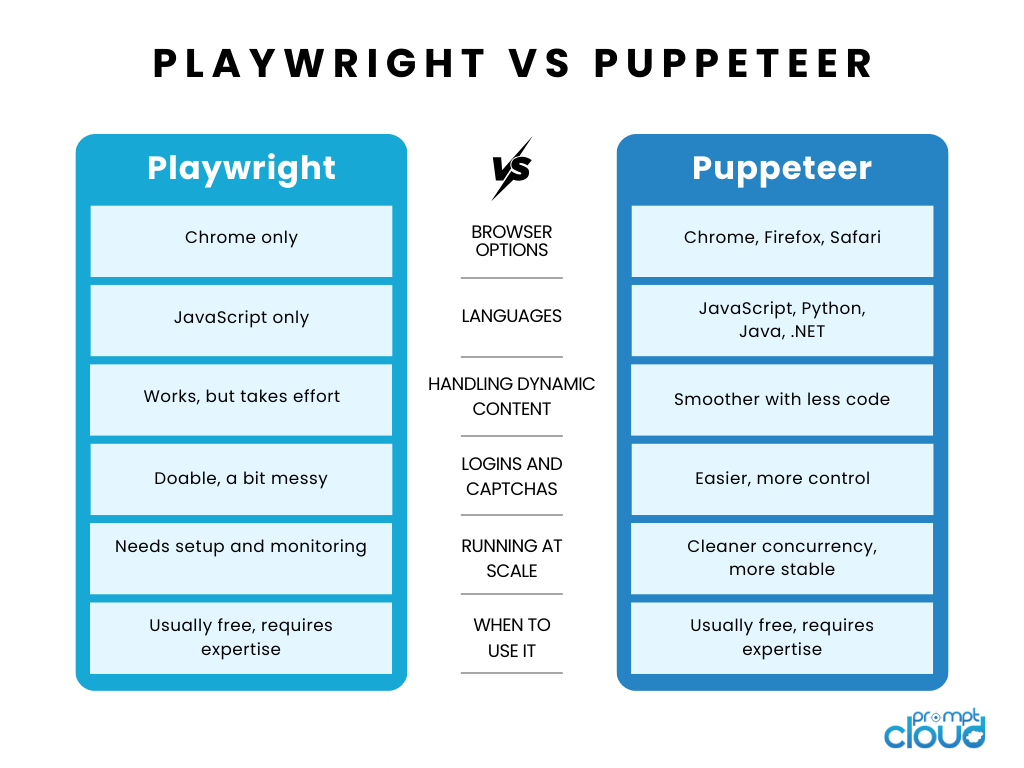
Performance Benchmarks: What the Numbers Actually Tell You
Let’s be real, performance numbers can be twisted to say anything. But when it comes to web scraping, there are a few metrics that actually matter:
- Page load time
- Success rate under load
- Memory usage over time
- How many tabs can you run before things fall apart
We’ve run both Playwright and Puppeteer in real scraping pipelines—over tens of thousands of pages—and here’s what it looks like when you’re not benchmarking in a vacuum.
Page Load Speed
Puppeteer is usually faster per page. It’s lighter, and because it only supports Chromium, you’re dealing with less overhead. If you’re scraping a bunch of simple pages, this adds up. A basic page might load in 1.2 seconds with Puppeteer and 1.5–1.7 seconds with Playwright.
But here’s the tradeoff: with complex pages, Puppeteer might load faster but fail to get the actual data, because it fired too early or missed the final render. So the “speed” is only useful if the content’s actually there.
Stability at Scale
This is where Playwright starts to pull ahead. With Puppeteer, spinning up 100+ concurrent tabs gets sketchy. You start hitting memory leaks or crashing headless sessions. There are ways around it, but they require more orchestration, like running clusters or queue-based architectures.
Playwright is just more stable under load. You can isolate browser contexts without spinning up new browser instances. That saves memory, and you can go bigger before things choke.
CPU & Memory
On paper, Playwright uses more memory. It’s a bigger tool. But ironically, that extra bulk helps it hold up better when you’re doing thousands of page visits.
Puppeteer can run leaner if you’re doing small jobs. But once you’re juggling sessions, switching IPs, or working with login flows, memory use climbs fast, and you start running into session bleed or inconsistent scraping results.
Real-World Scenario: Scraping a JS-Heavy eCommerce Site
We ran a head-to-head scrape on a real product catalog site—fully JavaScript-rendered, prices behind pop-ups, lazy-loaded images.
- Puppeteer: 75% success rate before failures started creeping in after about 500 pages. Some pages returned incomplete data.
- Playwright: 96% success rate across 1,000+ pages. Slightly slower per page, but way more consistent. Didn’t choke under parallel loads.
When to Choose Playwright Over Puppeteer (And Vice Versa)
If you’re here, you’re probably not looking for a generic pros and cons list. You want to know when to use which, because your time, infrastructure, and data reliability actually matter.
Here’s how we think about it internally at PromptCloud when deciding what to use for a project.
Use Puppeteer when:
You’re scraping simple, predictable pages. Stuff like news articles, static listings, product pages without login gates, or public data portals that don’t mess around with JS too much. You don’t need fancy browser tricks—you just need the page to load, and you want it fast.
Also, if your team already works in Node.js, Puppeteer gets you up and running with minimal friction. No need to bring in Python wrappers or deal with cross-language headaches.
But keep this in mind: the minute you run into edge cases—like pages that load in chunks or ask for a login mid-flow—you’ll start writing more workarounds than scraper logic.
Use Playwright when:
The site isn’t built for bots. Maybe it requires a login. Maybe it doesn’t load any real content until a user scrolls or clicks something. Maybe it throws a CAPTCHA at every 20th visit. Or maybe you need to pull data from a few different browsers because of how the content is rendered.
This is where Playwright makes life easier. You’ve got more control over context and user behavior. You can switch devices, rotate user agents, and segment sessions cleanly. It also lets you scale faster without constantly restarting browser instances.
Playwright is also our go-to when the stack isn’t locked to JavaScript. If the client already runs Python or Java apps, Playwright fits right in without needing Node.js glue code.
Real-world filter: What’s the cost of failure?
If you’re scraping a few hundred pages a day and can afford to retry failed requests, Puppeteer might be enough. But if you’re pulling 10,000+ pages where each failure means missed revenue or lost insights—Playwright’s stability is worth it.
The Right Tool Depends on the Job
There’s no universal answer to the Playwright vs Puppeteer debate. If the site you’re working with is pretty basic—think static pages, no login, minimal JavaScript—you can just stick with Puppeteer. It’s quick to set up, gets out of your way, and runs smoothly if you’re already using Node. You won’t need much more than a browser instance, a few selectors, and a loop.
But once you start dealing with pages that change as you scroll, hide stuff behind buttons, or ask you to log in before you see anything useful, that’s when Playwright starts to make more sense. It’s a bit heavier to run, yeah, but you get better tools for scripting those flows without things breaking every other day.
At PromptCloud, we don’t chase tool preferences—we chase reliability. We care about whether the scraper runs cleanly, delivers accurate data, and doesn’t need constant patching. Sometimes that means Puppeteer. Other times, it means Playwright. Most clients never even need to know which one we used.
So if you’re trying to decide which to use, ask yourself this: How messy is the site, and how important is getting it right the first time? That’ll give you your answer.
How PromptCloud Delivers Web Scraping Solutions with Both Tools
We don’t believe in one-size-fits-all scraping. Never have. Every site is different. Some are simple and stable, some are hostile and unpredictable. That’s why we don’t lock ourselves or our clients into a single tool.
We don’t pick one tool and stick to it blindly. Sometimes it’s Puppeteer, sometimes it’s Playwright. Depends on what the site looks like and what the client actually needs scraped.
If we’re dealing with something stable—like a bunch of job posts, real estate listings, or product pages that just render normally without doing anything fancy—we’ll usually go with Puppeteer. It gets the job done and doesn’t add extra overhead. No point overengineering a scraper that only needs to click once and grab the content. It’s quick to deploy, fast, and lightweight. For scheduled scraping that doesn’t require deep browser automation, it’s more than enough.
But for anything dynamic or high-volume, Playwright tends to win.
We’ve used Playwright to scrape ecommerce sites that load prices and stock info through JavaScript after login. We’ve used it to handle multi-step form submissions, navigate through user dashboards, and pull data that only appears after scrolling through several chunks of content. It holds up better when the site isn’t built to make scraping easy, which is most of the web these days.
More importantly, we abstract the complexity away from our clients. Our clients usually don’t ask what tool we’re using—and honestly, they shouldn’t have to. Sometimes it’s Puppeteer because it gets the job done faster. Other times, Playwright handles the weird edge cases better. Either way, we just make sure the scraper runs without breaking and the data shows up clean. Schedule a demo now!
FAQs
1. Is Playwright better than Puppeteer?
Not really. It depends on the site. If the pages are static or don’t do anything weird with JavaScript, Puppeteer is totally fine. But if you’re scraping something modern—like a React frontend that hides everything until you scroll or click something—Playwright handles that kind of stuff with less effort. We use both, depending on what the site throws at us.
2. Can Playwright deal with login pages or CAPTCHAs?
Yeah, it can. You still have to script the flow, but Playwright gives you better tools for doing it cleanly. Stuff like storing cookies, managing separate sessions, or controlling timing makes things a lot easier. As for CAPTCHAs, you’ll still need to plug in a solving service or figure out a workaround. Playwright doesn’t “solve” them out of the box, but it gives you room to handle them without duct tape.
3. What if I just want the faster option?
If speed’s your only concern and the site is basic, Puppeteer is usually faster per page. It’s lightweight and doesn’t try to do too much. But when things get complex, Puppeteer might load the page quickly, but fail to grab the data. In those cases, Playwright might be slower, but it actually works. So it’s kind of a trade: fast and brittle vs. slightly slower but reliable.
4. We’re scraping thousands of pages a day. Which one holds up better?
Playwright. You can spin up multiple browser contexts inside the same session, which makes managing parallel scrapers cleaner. Puppeteer can do it too, but you’ll probably spend more time managing memory and keeping sessions from crashing. If scale is part of your day-to-day, Playwright is less of a pain.
5. Do I have to pick one, or can I switch between them?
You can totally switch. We do. Some scrapers run better on Puppeteer because they’re small and low-maintenance. Others start with Puppeteer and move to Playwright later when the site gets more dynamic or unstable. At PromptCloud, we don’t stick to one tool—we use whatever works. That flexibility saves time and makes our scrapers more durable in the long run.















