




In today’s data-driven world, the ability to efficiently extract information from PDF documents is a necessity for many businesses and researchers. PDFs are one of the most common formats for distributing and sharing documents, but their structured presentation often makes extracting data challenging. This blog post delves into the fundamentals of data extraction from PDFs, exploring both the tools and techniques that can streamline this process.
Why Extract Data from PDFs?

Source: https://www.docsumo.com/blog/extract-data-from-pdf
In the vast expanse of the digital age, PDF documents stand as a testament to the blend of consistency, reliability, and universal accessibility. Introduced by Adobe in the 1990s, the Portable Document Format (PDF) quickly became the standard for distributing digital documents that retain their formatting regardless of the device or software used to view them. Today, PDFs are ubiquitous, serving as the vessel for everything from academic papers and legal contracts to technical manuals and financial reports. Yet, beneath their static and polished surface lies a wealth of data often locked away from easy access. This brings us to the crucial question: Why is extracting data from PDFs so vital?
At the heart of digital transformation is data – data that informs, data that guides, and data that solves. In our relentless pursuit of efficiency, understanding, and innovation, the extraction of data from PDFs serves as a bridge from the static to the dynamic, from information to insight. Whether it’s analyzing market trends from research reports, digitizing historical records for archival purposes, or processing invoices for financial reconciliation, extract data from PDFs enables businesses and researchers to convert static information into actionable insights.
Challenges in PDF Data Extraction
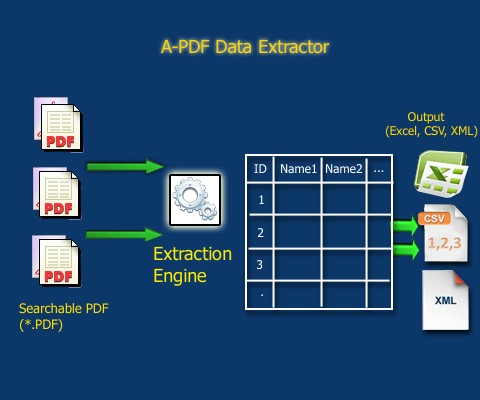
Source: https://www.a-pdf.com/data-extractor/index.htm
Extract data from PDF documents presents a unique set of challenges that can complicate the process for businesses, researchers, and developers alike. Despite the widespread use of PDFs for digital documentation, their inherent properties and diverse formats add layers of complexity to data extraction efforts. Here, we delve into some of the key challenges encountered in PDF data extraction, offering insights into why what seems like a straightforward task can often become a complex endeavor.
Inherent PDF Structure Complexity
PDFs are designed primarily for presentation, not data storage or manipulation. They often lack a consistent structure, which can make automated extraction difficult. Unlike HTML or XML, where tags and elements define structure and hierarchy, PDFs position elements in fixed layouts. This means that understanding the logical structure of information, such as distinguishing between titles, paragraphs, and data tables, requires sophisticated interpretation.
Variability in Document Quality
PDF documents can vary significantly in quality, especially when dealing with scanned documents. Scans can introduce noise, distortions, and inconsistencies in the text, making OCR (Optical Character Recognition) processes less accurate. Factors like the resolution of the scan, the condition of the physical document, and the presence of marks or annotations can further complicate data extraction.
Text and Image Mix
Many PDFs contain a mix of text and images, and in some cases, crucial information is embedded within images. This requires the use of OCR technology to extract text from images, which can be challenging, especially with complex layouts, varied fonts, and mixed quality of the images. Furthermore, OCR accuracy can significantly impact the quality of the extracted data.
Complex Layouts and Formats
PDFs often feature complex layouts, including tables, multi-column text, footnotes, and sidebars. These elements can disrupt straightforward text extraction, leading to data loss or misinterpretation. Extracting data from tables, for example, is particularly challenging because the spatial relationship between elements (rather than a logical or hierarchical structure) defines the data organization.
Encrypted or Secured PDFs
Some PDFs are encrypted or secured to protect copyright or sensitive information, restricting actions such as copying, printing, or editing. Extracting data from these PDFs requires decryption, for which permission or the appropriate decryption key is necessary. This adds an additional layer of complexity and legal considerations to the extraction process.
Diverse Encoding and Compression
PDF files can use a variety of text encodings and image compression techniques, some of which may not be straightforward to interpret or decode. This diversity requires flexible and robust parsing tools capable of handling different encodings and decompressing content as needed for data extraction.
Tools and Techniques for Effective Data Extraction
PDF Parsing Libraries
- Python Libraries: Python offers several libraries for PDF data extraction, including PyPDF2 and PDFMiner for text-based PDFs, and PyMuPDF for more complex documents.
- Apache PDFBox: A Java tool that allows creation and manipulation of PDF documents, including text extraction.
OCR Tools
When dealing with scanned PDFs or image-based documents, OCR tools are essential. Tesseract, an open-source OCR engine, is widely used for converting images in PDFs into editable text formats.
Commercial PDF Extraction Software
Several commercial tools offer advanced features like AI-based learning algorithms to handle complex data extraction tasks with higher accuracy. Examples include Adobe Acrobat DC and ABBYY FineReader.
Additional Resources
While many tools offer solutions for extracting data from PDFs, those looking to not just extract but also edit or modify PDFs need additional resources. For simple and intuitive adjustments such as adding text, images, or even altering the layout without compromising document integrity, you may want to experiment with a PDF editor online. This tool can significantly simplify the process for anyone who deals with PDF on a regular basis.
Best Practices for PDF Data Extraction
- Pre-process PDFs: Cleaning up documents before extraction (e.g., removing unnecessary images or blank pages) can significantly improve accuracy.
- Custom Scripts for Automation: For large-scale extraction tasks, consider writing custom scripts that use PDF parsing libraries. This allows for automation and customization according to specific needs.
- Validation and Quality Checks: Always incorporate a step to validate the extracted data. This can be automated to some extent but often requires human oversight.
Real-world Applications
- Financial Sector: Banks and financial institutions extract data from PDFs for credit analysis, risk assessment, and compliance reporting.
- Healthcare: Patient records, research articles, and clinical trial data are often stored in PDF format and require extraction for analysis and reporting.
- Academic Research: Researchers extract data from scholarly articles and academic papers for literature reviews and meta-analyses.
Conclusion
The extraction of data from PDF documents, while challenging, is essential for data analysis, reporting, and decision-making across various industries. By leveraging the right tools and techniques, organizations can overcome the inherent difficulties of PDF data extraction and unlock valuable insights contained within their documents. As technology advances, we can expect continued improvements in extraction tools, making the process more accessible and efficient.
At PromptCloud, we understand the importance of accurate and efficient data extraction. Our customized solutions are designed to meet the specific needs of our clients, ensuring that they can make the most of the information contained within their PDF documents. Whether you’re looking to extract data from a handful of documents or automate the extraction process across thousands, we’re here to help.
Embrace the power of data with PromptCloud. Reach out today to discover how we can transform your PDF data extraction process. Get in touch at sales@promptcloud.com
Frequently Asked Questions
How do I extract specific data from a PDF?
Extracting specific data from a PDF requires a combination of tools and techniques, tailored to the nature of the PDF file (text-based or scanned/image-based) and the specific data you’re looking to extract. Here’s a step-by-step guide to help you extract specific data from PDFs:
For Text-based PDFs:
- Use Python Libraries like PyPDF2 or PDFMiner:
These libraries can help you extract text from PDFs that contain selectable text layers.
- PyPDF2: Useful for simple text extraction and PDF manipulation (like merging PDFs).
import PyPDF2
# Open the PDF file
with open(‘your_file.pdf’, ‘rb’) as file:
reader = PyPDF2.PdfReader(file)
# Extract text from the first page
page = reader.pages[0]
text = page.extract_text()
print(text)
PDFMiner: More sophisticated, suitable for extracting text from complex layouts.
from pdfminer.high_level import extract_text
text = extract_text(‘your_file.pdf’)
print(text)
2. Extract and Process the Text:
Once you have the text, you may need to process it to find and extract the specific data you’re interested in. This can involve:
- Searching for keywords or patterns using regular expressions.
- Splitting the text into lines or paragraphs for context-aware extraction.
For Scanned/Image-based PDFs:
1. Use OCR (Optical Character Recognition) Tools:
For PDFs that are essentially images of text (e.g., scanned documents), you’ll need to use OCR software to convert the images into selectable text. Tesseract is a popular, open-source OCR engine.
- Pytesseract: A Python wrapper for Tesseract. You’ll also need to convert PDF pages to images, which can be done using pdf2image.
from pdf2image import convert_from_path
import pytesseract
# Convert PDF to a list of images
images = convert_from_path(‘your_scanned_file.pdf’)
# Use pytesseract to do OCR on the image
for i, image in enumerate(images):
text = pytesseract.image_to_string(image)
print(f”Page {i+1} Text:”, text)
2. Process the Extracted Text:
After OCR, the text will likely need cleaning and processing to extract the specific data points you need. This can include removing artifacts introduced by OCR, parsing the text for structure, and applying regular expressions to find patterns.
How do I extract form data from a PDF?
Extracting form data from a PDF, especially if the form is filled out and saved, involves specific methods that can parse the PDF structure and extract the data embedded in form fields. There are several tools and libraries across different programming languages that can accomplish this task, but Python remains one of the most accessible and popular options due to libraries like PyPDF2 and PDFMiner for text-based PDFs, and PyMuPDF (also known as Fitz) for more complex tasks. Here’s how you can extract form data from a PDF using Python:
Using PyMuPDF (Fitz)
PyMuPDF is a Python binding for MuPDF – a lightweight PDF, XPS, and E-book viewer. It offers extensive features for working with PDFs, including extracting text, images, and form data.
Installation
First, ensure you have PyMuPDF installed:
pip install pymupdf
Extracting Form Data
import fitz # PyMuPDF
def extract_form_data(pdf_path):
# Open the PDF
doc = fitz.open(pdf_path)
form_data = {}
for page in doc:
# Extract annotations (form fields are a type of annotation)
annots = page.annots()
if annots:
for annot in annots:
info = annot.info
field_type = info.get(“subject”)
field_name = info.get(“title”)
field_value = info.get(“content”)
if field_name and field_value:
# Populate the dictionary with field names and values
form_data[field_name] = (field_value, field_type)
return form_data
# Replace ‘your_form.pdf’ with the path to your PDF form
form_data = extract_form_data(“your_form.pdf”)
for field in form_data:
print(f”Field: {field}, Value: {form_data[field][0]}, Type: {form_data[field][1]}”)
This script opens a PDF and iterates through each page, checking for annotations (where PDF form fields are categorized). For each annotation, it extracts the field name, value, and type, storing them in a dictionary.
Using PyPDF2
PyPDF2 is another popular library for working with PDFs in Python. It can also handle form data extraction, although it might not be as comprehensive as PyMuPDF for complex PDFs.
Installation
Ensure PyPDF2 is installed:
pip install pypdf2
Extracting Form Data
import PyPDF2
def extract_form_data_py2(pdf_path):
with open(pdf_path, ‘rb’) as file:
reader = PyPDF2.PdfReader(file)
form_data = {}
# Access the form data from the reader
fields = reader.get_fields()
for field in fields:
form_data[field] = fields[field].get(‘/V’, None)
return form_data
# Replace ‘your_form.pdf’ with the path to your PDF form
form_data = extract_form_data_py2(“your_form.pdf”)
for field in form_data:
print(f”Field: {field}, Value: {form_data[field]}”)
This function utilizes PyPDF2 to open a PDF file and access its form fields directly. It iterates through the fields, extracting the name and value of each, and storing them in a dictionary.
Can you scrape data from a PDF?
Yes, you can scrape data from a PDF, but the approach and tools you’ll need depend on the type of PDF and the nature of the data you want to extract. PDFs can be broadly categorized into two types: text-based and scanned/image-based. Each type requires different techniques for effective data extraction.
Text-based PDFs
These PDFs contain selectable text. You can highlight, copy, and paste this text into another document. Text-based PDFs are generally easier to work with when it comes to data scraping.
Tools and Libraries:
- PyPDF2 and PDFMiner in Python are popular for extracting text from these PDFs. PyPDF2 is straightforward and useful for basic text extraction and PDF manipulation, while PDFMiner offers more granular control over layout and formatting, making it suitable for complex extraction needs.
- Apache PDFBox, a Java library, can also extract text from PDFs and is used in enterprise-level applications.
Scanned/Image-based PDFs
These PDFs are essentially images of text. Since the text is part of an image, it cannot be directly selected or copied. Extracting data from these PDFs requires Optical Character Recognition (OCR) to convert the images of text into actual text.
Tools and Libraries:
- Tesseract OCR is one of the most powerful and widely used OCR engines. It can be used directly or through wrappers like Pytesseract in Python.
- Adobe Acrobat Pro offers built-in OCR capabilities and can convert scanned PDFs into selectable and searchable text documents.
How do I automatically extract data from a PDF?
Automatically extracting data from a PDF involves using software tools that can interpret the contents of the PDF and convert them into a structured format. The process differs depending on whether the PDF is text-based or image-based (scanned). Here’s how to approach automatic data extraction from both types of PDFs:
For Text-based PDFs
1. Using Python Libraries:
- PyPDF2 or PDFMiner are popular Python libraries for extracting text from text-based PDFs. PyPDF2 is suitable for simple text extraction tasks, while PDFMiner is more powerful for complex layouts and encoding.
- Example with PyPDF2:
import PyPDF2
with open(‘example.pdf’, ‘rb’) as file:
reader = PyPDF2.PdfReader(file)
text = ”
for page in reader.pages:
text += page.extract_text()
print(text)
- Tabula or Camelot: If your goal is to extract table data from PDFs, these libraries are specifically designed for this purpose, with Camelot providing more control over the extraction process.
2. Using Command Line Tools:
- pdftotext is part of the Xpdf toolset and can be used to convert PDF documents into plain text directly from the command line, making it suitable for batch processing.
For Scanned/Image-based PDFs
Scanned PDFs require Optical Character Recognition (OCR) to convert images of text back into selectable and searchable text.
1. Using Tesseract OCR:
- Tesseract is an open-source OCR engine. Pytesseract, a Python wrapper for Tesseract, allows you to integrate OCR capabilities into your scripts.
- Example with Pytesseract:
from PIL import Image
import pytesseract
from pdf2image import convert_from_path
images = convert_from_path(‘scanned_example.pdf’)
text = ”
for image in images:
text += pytesseract.image_to_string(image)
print(text)
2. Using OCR Services:
- Adobe Acrobat Pro offers built-in OCR capabilities that can automatically recognize text in scanned documents.
- Online OCR services: Various online platforms provide OCR services that can process PDFs in bulk. However, be mindful of privacy and security when uploading sensitive documents.















