




**TL;DR**
In digital-first markets, brand reputation moves fast.
What this article covers:
- How reputation scraping unifies reviews, social chatter, blogs, and news into one source of truth.
- How sentiment pipelines and alerting convert raw text into clear priorities.
- Where teams trip up (noise, false positives, privacy) and how to build guardrails.
- Practical playbooks for PR, CX, Legal, and Product to respond with confidence.
Takeaways:
- Real-time scraping expands visibility beyond social listening tools.
- Scored mentions focus teams on what truly needs action now.
- Governance, QA, and compliance make the difference between noise and signal.
Quick scene. Monday, 9:12 a.m.
A frustrated customer vents on a niche forum. A local blog picks it up. Someone screenshots it on X. By the time it hits your PR team’s inbox, it’s already gathering steam. Not catastrophic, but costly. And avoidable.
Now imagine the opposite. Your monitoring stack flags the first mention instantly. Sentiment is negative, reach potential is rising, and the alert lands with context: what was said, where, by whom, and how similar threads have played out before. Your team replies with facts, offers support, and closes the loop in public. The thread fizzles. Trust stays intact.
That’s the promise of web scraping for online reputation. Enterprises are moving from passive “listening” to active reputation engineering: scanning reviews, forums, social posts, blogs, and news to spot pattern breaks early: a product defect cluster, a recurring service gripe, an off-note headline that needs a quick correction.
In the pages ahead, we’ll map what reputation scraping really looks like in practice, how to architect a reliable pipeline, how to cut through noise without missing the spark that matters, and how to turn signals into decisions for PR, Legal, CX, and Product. Clear, practical, usable.
What Reputation Scraping Really Means (and Why It’s More Than Reviews)
Most teams still think “online reputation” begins and ends with star ratings on review sites. That’s only the visible tip. The real story lives in the long tail—comments, forum threads, news pieces, Reddit discussions, TikTok captions, even job-site feedback. Each mention shapes perception before your comms team can react.
Reputation scraping is the process of continuously collecting those scattered fragments—across the open web—and turning them into structured, analyzable data. It’s not about vanity metrics. It’s about building a system that watches how people actually talk about your brand in the wild.
A retail brand, for example, doesn’t just monitor Trustpilot reviews anymore. It scrapes YouTube video descriptions mentioning its product line, scans Twitter for brand tags tied to negative keywords (“refund,” “broken,” “late”), and captures product Q&A data from marketplaces. In parallel, a hotel chain tracks new Google Maps reviews, complaint threads on travel forums, and sentiment shifts in influencer posts.
When all this data streams into one place, patterns emerge. You can see which issues recur, which markets trend negative, and which touchpoints (customer service, packaging, price) drive most frustration. It’s how companies replace gut feeling with early warning systems.
And unlike manual review collection, scraping doesn’t wait for someone to tag your handle. It finds implicit mentions—brand nicknames, misspellings, competitor comparisons—that your typical listening tools miss.
In short:
- Review scraping shows what customers say to you.
- Reputation scraping shows what they say about you—everywhere else.
How Enterprises Architect a Reputation Monitoring Pipeline
Let’s break down what actually happens behind the scenes when enterprises deploy web scraping for online reputation. Forget the image of a few Python scripts pinging review sites. Modern setups look more like streaming data infrastructures than marketing dashboards — built for scale, speed, and safety.
At the simplest level, there are four moving parts in any serious reputation monitoring stack:

Figure 1: The three pillars of reliable reputation scraping—ensuring compliant sources, validated data, and consistent context across brand mentions.
1. The Source Map
It starts with the question: where does conversation happen for our brand? For some, that means Yelp and Google Reviews. For others, it’s Reddit, Glassdoor, niche blogs, or trade forums. Large enterprises maintain an evolving source registry — hundreds of domains organized by type:
- Owned: official store, app reviews, support forums.
- Earned: media coverage, influencer posts, blogs.
- Public: marketplaces, directories, Reddit, Quora, and discussion boards.
Each domain carries a different signal quality. A single negative headline in a national paper may outweigh fifty minor product complaints.
2. The Scraping Layer
This is where PromptCloud-like architecture comes in. Enterprises deploy managed scraping pipelines with proxy rotation, dynamic rendering, and JavaScript handling to capture every data point without breaking ToS or hitting rate limits.
Each record: review, post, headline — arrives with contextual metadata:
- URL, timestamp, and domain authority.
- Language, location, and sentiment probability.
- Entity tags (brand, product, competitor, campaign).
When that data is normalized, it becomes usable fuel for analytics tools.
3. The Processing & Scoring Engine
Teams also apply context rules; excluding old posts, duplicates, or irrelevant chatter. This is where data validation and QA monitoring keep the pipeline clean. For deeper modeling, enterprises enrich scraped data with internal context: customer region, product line, ad spend, or campaign tags. That’s how they link public perception to business performance.
Note: Enterprise-grade pipelines also prioritize data security in enterprise web scraping pipelines, ensuring reputation data is gathered ethically and remains compliant with regional privacy laws.
4. The Alert & Visualization Layer
The last mile is what teams actually see. Dashboards stream reputation scores, trending topics, and crisis indicators. Alerts trigger when sentiment crosses thresholds — for example, when negative mentions spike 40% in 24 hours in a specific geography.
Instead of manually scanning posts, brand managers get:
- Real-time alerts for emerging crises.
- Trend visualizations for long-term perception shifts.
- Automated reports to share with PR, CX, and executive teams.
Here’s the quiet advantage; when everyone sees the same live feed, PR isn’t chasing Marketing, and Legal isn’t guessing.
Need a real-time pipeline that captures brand mentions before they turn into crises?
PromptCloud provides AI-ready data pipelines built on publicly accessible sources, with compliance<br>documentation, source provenance, and usage controls baked in.
From Mentions to Meaning: Turning Scraped Data into Actionable Insights
Collecting data is the easy part. The real challenge is separating noise from narrative. Every brand mentioned has context — who said it, how influential they are, and whether it signals a one-off complaint or the start of a trend. That’s where the intelligence layer comes in.
Enterprises don’t just scrape text; they score, cluster, and correlate it. This is how they make sense of the chaos.
Step 1: Sentiment, Emotion, and Intent
Once text data is scraped, NLP models step in to classify tone. But the good ones go beyond “positive” or “negative.” They capture intent: is the post sarcastic, urgent, or frustrated? A simple “great job fixing the last mess” reads positive on the surface but carries a cautionary undertone.
Enterprises blend multiple classifiers to reach contextual accuracy — one for polarity, another for emotion, another for purchase intent or churn risk. This multi-layered sentiment tagging helps them spot patterns invisible in a simple five-star rating system.
Step 2: Topic Clustering
After sentiment comes clustering. Machine learning models group mentions by theme: product quality, service, delivery, price, or employee experience. This helps teams see which areas drive sentiment shifts.
For example, a telecom company might find 70% of negative mentions aren’t about price — they’re about delayed customer support callbacks. That single insight redirects millions in resource allocation faster than any survey ever could.
Step 3: Influence and Reach Scoring
Every mention doesn’t deserve equal attention.bA Reddit post with 12 upvotes isn’t the same as a tweet from a journalist with 2M followers. Enterprises use influence scoring — a metric that combines author reach, engagement rate, and source credibility.
Mentions are ranked by potential impact:
- Tier 1: High-authority media, verified influencers, viral threads.
- Tier 2: Community forums, recurring reviewers, niche blogs.
- Tier 3: Individual comments and minor chatter.
This tiering ensures teams respond proportionally — prioritizing influence over volume.
Note: Just like the AI-driven sentiment models trained on scraped data used for model training at scale, reputation monitoring systems rely on high-quality text datasets to detect tone, emotion, and context accurately.
Step 4: Contextual Correlation
Finally, scraped sentiment is linked to real-world variables: sales performance, campaign timing, customer churn, or support ticket volume. When plotted together, they show why reputation fluctuates, not just that it does.
A beauty brand might notice sentiment dips each time a new influencer campaign launches — a signal that creative messaging isn’t resonating. A SaaS provider might see spikes in negative tone right after a product update. Without scraped data, these links stay invisible.
The beauty of this approach is that it closes the loop. Web scraping doesn’t just monitor reputation; it translates perception into operational insight.
Crisis Detection and Early Warning Systems
Reputation crises rarely start big. They start small — one tweet, one forum post, one poorly worded email — and spiral before anyone at HQ even notices. That’s why large enterprises rely on web scraping pipelines designed for early detection rather than post-mortem reporting.
The rule is simple: the faster you detect, the smaller the fallout.
Note: These real-time systems often resemble real-time aggregation models similar to financial news scraping, capable of tracking breaking sentiment shifts in near real time.
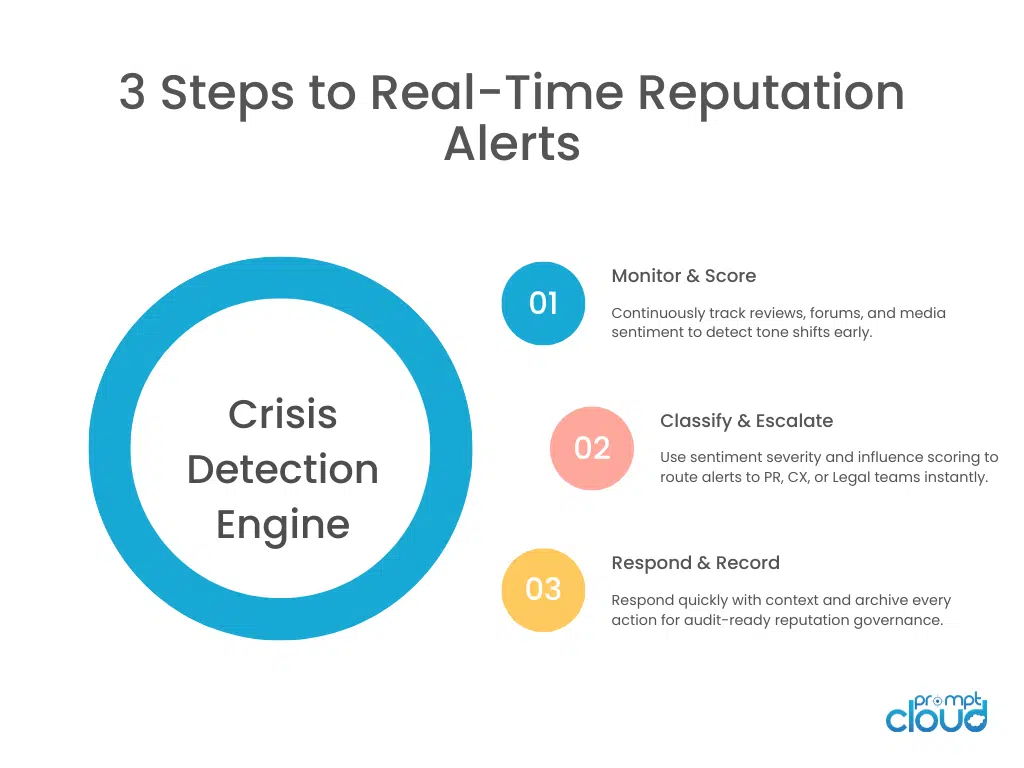
Figure 2: The crisis detection engine that powers real-time reputation alerts—monitoring, classifying, and escalating critical mentions before they become viral events.
The Anatomy of a Reputation Spike
Every brand has a baseline of daily chatter. But when scraping data suddenly shows a surge in negative sentiment — say, a 3x jump in complaint volume or a sudden shift in tone from neutral to angry — the system triggers a flag.
These spikes often precede a PR storm by several hours or even days. Think of it as radar before thunder. For example:
- A fintech app sees “login failure” mentions climbing across Reddit and X.
- A consumer electronics brand notices a sudden burst of “overheating” and “recall” in product reviews.
- A travel platform detects a rise in “refund delay” complaints localized to one geography.
Each of these anomalies signals a brewing issue. Without automated scraping and sentiment tracking, teams usually learn about it from journalists — not dashboards.
Turning Alerts Into Escalation Paths
Good data isn’t enough. There has to be a playbook attached. A mature setup looks like this:
- Detection layer: Scrapers collect and flag anomalies.
- Classification layer: NLP and heuristics confirm the pattern.
- Action layer: Alerts go to the right teams with recommendations.
That pipeline transforms raw web chatter into a living, breathing early warning network.
Why Real-Time Matters
In crisis management, hours make the difference between a contained issue and a trending disaster. Static, batch-processed data (like weekly reports) simply can’t keep up. That’s why enterprises are shifting to event-driven scraping architectures — systems that push updates immediately into Slack, email, or monitoring dashboards.
The same infrastructure that financial firms use for high-frequency market data now powers brand protection. When sentiment drops below a set threshold or a keyword cluster spikes, the signal hits your inbox within minutes.
The ROI of Reputation Radar
Early detection doesn’t just protect image; it saves measurable money. Studies show that companies responding to viral complaints within the first 24 hours cut negative coverage by nearly 40%. Faster responses also preserve ad ROI; fewer crisis-driven pauses or “damage-control” spends.
Put simply, scraping gives enterprises time, and time is what reputation loss burns through fastest.
Integrating Reputation Data with CX and Product Teams
Collecting and classifying sentiment is valuable, but it only changes outcomes when the right teams act on it. In large organizations, that usually means bridging three worlds that rarely speak the same language — PR, Customer Experience, and Product.
A strong web scraping for an online reputation framework doesn’t just deliver dashboards; it connects signals directly into workflows.
1. For Customer Experience (CX) Teams
CX teams thrive on granularity. With review scraping and sentiment scoring, they can see where problems originate — a particular region, store, or channel — and act before support tickets explode.
Integrating scraped reviews into CRM systems also helps personalize responses. For example, when a recurring complaint about delivery timelines surfaces, the support team can immediately reference logistics data to close the loop faster.
A scraping case study for travel platforms demonstrated this perfectly: a travel aggregator identified rising frustration around refund delays during peak season. By mapping mentions from forums, social channels, and blogs, the company restructured its help center flow — cutting complaint resolution time by 40% and restoring trust in under a quarter.
2. For Product and Engineering
Product teams rely on scraped data to track usability issues that never reach official support channels. When a pattern emerges — “app crashes,” “battery drain,” or “checkout lag” — it guides sprint priorities faster than NPS surveys ever could. This constant feedback loop acts like a passive focus group, feeding unfiltered market sentiment into product design decisions. It’s how enterprises bake empathy into engineering.
3. Making It Cross-Functional
The key isn’t more data; it’s shared context. The same mention that triggers a PR alert can also populate a CX case and appear as a pattern in the product backlog. Enterprises that align these loops close the delay between perception and action.
The outcome: fewer surprises, faster fixes, and a brand narrative that feels responsive instead of reactive.
Further reading: A scraping case study for travel platforms shows how customer feedback loops across reviews, social posts, and forums directly shape product roadmaps when the data flows back to operations and support.
Governance, Compliance & Ethical Boundaries in Reputation Scraping
Scraping brand mentions sounds harmless. But once data touches people — names, opinions, profiles — things get complicated. For enterprises doing web scraping for online reputation, governance and compliance aren’t optional; they’re the scaffolding that keeps the system robust, lawful, and defensible.
Here’s how serious teams build guardrails around reputation scraping — and what to keep front of mind.
Understanding the Legal Landscape
First, you have to see where the lines are drawn.
- GDPR in the EU is a big one: any personal data collection must align with legal bases (consent, legitimate interest, etc.), offer transparency, and allow data subject rights.
- In the U.S., the Computer Fraud and Abuse Act (CFAA) and contract law (terms of service) shape what’s allowed. The famous hiQ Labs v. LinkedIn case affirmed that scraping publicly visible data doesn’t necessarily violate the CFAA — but it’s still subject to ToS constraints and other legal nuances.
- Many jurisdictions have data protection or consumer privacy laws (CCPA in California, variants in Canada, etc.).
- Courts are also starting to treat misuse of scraped data (e.g. trade secret misappropriation) as actionable — in one recent case, scraping data from a public site was deemed a trade secret violation.
So: scraping public text isn’t always illegal — but how you do it, what data you capture, and how you use it matter deeply.
Ethical Principles & Best Practices
Even if something is legal, it can still feel wrong. To avoid mistrust, backlash, or long-term brand risk, many enterprise teams codify principles. Some of the guardrails look like:
- Minimal harvest scope: Only scrape what you need. If monitoring brand mentions, avoid pulling deep profile info, contact data, or anything beyond what’s necessary to detect sentiment or context.
- Respect robots.txt / crawling directives: Even though violating robots.txt isn’t always legally grounds for liability, obeying it is considered best practice and signals respect for publisher preferences.
- Rate limiting and load management: Don’t hammer a website. Use delays, throttle aggressiveness, and randomization so you don’t overload servers or get blocked.
- Anonymization / pseudonymization: If content includes names or identifiers, mask or pseudonymize data where possible so scraped records don’t become leak risks.
- Consent & opt-out logic: Where possible, respect opt-out signals or legal requests. Some sites have APIs or license models that align better with commercial usage.
- Auditability & traceability: Log every action: when scraped, from where, by which agent, and how it was processed. These logs help in audits, compliance checks, or legal challenges.
- Human-in-the-loop QA: Let algorithms flag, but humans validate. False positives or misinterpretations (sarcasm, local idioms) are common — especially with reputational content.
Mitigating Risk: Governance in Practice
Let me walk you through what good governance looks like in a real enterprise setting.
- Data classification policies decide which types of scraped content require extra care or review (e.g. mentions of people, legal claims, or medical complaints).
- Access control layers ensure only designated roles (legal, PR, compliance) see raw text, while broader teams see aggregated dashboards.
- Review escalation protocols when an alert hits severity thresholds. Legal, PR, or compliance teams are automatically looped in.
- Periodic audits / third-party reviews of scraped pipelines to check for drift (unintended scraping) or data leakage.
When governance is well-built, your reputation stack becomes not just a listening tool — but an accountable, legally defensible system.
Know more: For a deeper legal breakdown of web scraping legality, see “Is Web Scraping Legal? Key Insights & Guidelines” from ScrapingBee — it covers cross-jurisdiction risk, ToS conflicts, and ethical boundaries.
Pitfalls, Challenges & Mitigations
Even the best-designed reputation monitoring systems run into practical roadblocks. The difference between success and chaos usually lies in how teams handle these five.
1. Data Overload
When you first connect multiple sources — social media, forums, reviews, blogs, and news feeds — the firehose hits hard. Without structured pipelines, teams drown in duplicates, irrelevant chatter, and spam.
Mitigation: Filter aggressively. Define schema-level validation rules (brand name + sentiment + engagement threshold). Automate deduplication at ingestion, not after storage. And keep sampling — human review of 1% of data per week helps validate model accuracy.
2. False Positives & Misclassification
NLP models struggle with sarcasm, cultural slang, and humor. A tweet reading “yeah, great service 🙄” may get tagged as positive. That kind of miss can derail sentiment tracking.
Mitigation: Add multilingual sentiment calibration and retrain models quarterly. Use context windows instead of single-sentence classification. Blend automated scoring with manual spot checks.
3. Inconsistent Source Coverage
Websites change layouts, block scrapers, or move content behind APIs. If the system doesn’t adapt, visibility gaps appear.
Mitigation: Implement continuous validation and automated alerting for failed selectors — a practice core to managed services like PromptCloud. Keep a backup feed strategy: if a site blocks requests, pivot to RSS, APIs, or cached archives.
4. Compliance Drift
What starts as harmless scraping can quietly drift into gray areas — especially if teams begin collecting profile data or sensitive attributes unintentionally.
Mitigation: Run quarterly compliance reviews with Legal. Align to global standards like ISO/IEC 27001 and region-specific privacy laws. Managed data partners (like PromptCloud) already maintain structured compliance layers and SLA-backed audit trails.
5. Alert Fatigue
If every mention becomes an “urgent alert,” teams stop reading them. That’s how real crises slip through.
Mitigation: Tier alerts by sentiment severity and influencer reach. Only push notifications for priority-level events; route the rest to dashboards for periodic review.
Bringing It All Together
Online reputation management used to mean checking reviews once a week. Today, it’s a 24/7 operation powered by real-time scraping pipelines, sentiment engines, and cross-team workflows.
The best enterprises no longer chase bad press — they prevent it. They treat brand sentiment as a live signal, not a lagging indicator. And they back it with governance, automation, and responsible data practices that make their systems trustworthy — not intrusive.
That’s the difference between reacting to noise and shaping narrative.
Want to detect sentiment spikes before they turn into headlines?
PromptCloud provides AI-ready data pipelines built on publicly accessible sources, with compliance<br>documentation, source provenance, and usage controls baked in.
FAQs
1. What is web scraping for online reputation?
Web scraping for online reputation refers to automatically collecting brand mentions, reviews, forum discussions, and social chatter from across the web. The data is then analyzed for sentiment, influence, and reach so enterprises can understand and manage how their brand is perceived in real time.
2. How is web scraping different from social listening tools?
Social listening tools usually cover limited, API-based platforms like X or Facebook. Web scraping expands that scope — capturing blogs, Reddit threads, review sites, and even news mentions. It gives a much broader and earlier view of public sentiment before it hits mainstream channels.
3. Is reputation scraping legal?
Yes, when done ethically. Enterprises can legally scrape publicly available data if they respect robots.txt, avoid gated content, and comply with privacy laws such as GDPR and CCPA. Working with managed partners like PromptCloud ensures all data collection follows security and compliance standards.
4. What kinds of data sources are used for brand monitoring?
Enterprises track everything from review platforms (Google, Trustpilot) and discussion forums (Reddit, Quora) to blogs, digital news sites, and video descriptions. Each source provides a unique layer of brand sentiment and visibility into emerging reputation risks.
5. How fast can web scraping detect a potential PR crisis?
In real-time architectures, alerts can trigger within minutes of a post or headline going live. That speed gives PR, legal, and customer experience teams a critical window to respond, correct, or contain negative narratives before they escalate.
6. How does sentiment scraping help decision-making?
Sentiment scraping quantifies how people feel about your brand — not just what they say. By scoring polarity and emotion, enterprises can see which issues drive dissatisfaction, identify recurring complaints, and measure improvement over time.
7. Why use a managed service like PromptCloud for reputation monitoring?
Because scale, compliance, and accuracy matter. PromptCloud handles proxy rotation, dynamic rendering, data validation, and governance — so your teams can focus on interpreting signals, not fixing scripts or managing infrastructure.















