




Try building anything meaningful with a large language model these days — a chatbot that remembers context, a smart search tool, a recommendation engine — and pretty soon, you’ll run into one roadblock: where and how to store.
This is exactly where vector databases come in. They’re not just some backend upgrade or database trend-of-the-month. They solve a real and growing problem in AI: how to store and search high-dimensional data that represents concepts, intent, and relationships, not just rows in a table.
Traditional databases weren’t built for this. They’re great when you need to retrieve a customer record or calculate totals, but they fall apart when you ask, “What’s similar to this paragraph?” or “Which of these resumes is most like this job description?” LLMs operate in vectors, dense numerical representations of meaning, and if you want to work with that data properly, you need a system that speaks the same language.
That’s why vector databases for AI are suddenly everywhere. They power semantic search, retrieval-augmented generation (RAG), and contextual memory in chatbots, among other applications. If you care about speed, scale, or relevance in your AI output, they’re no longer optional.
We’re going to dig into exactly why that is, what makes vector databases different, and how they’re quietly becoming a core part of AI infrastructure. No fluff, no buzzwords for the sake of it. Just the stuff that matters.
What Are Vector Databases and Why Do They Matter for AI?
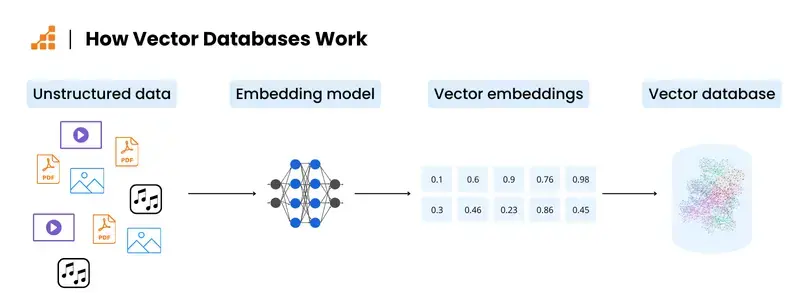
Image Source: Scalablepath
Let’s start with the basics — not just the definition, but why any of this matters when you’re building with AI.
Vector databases are purpose-built systems that store and retrieve vectors — dense numerical representations of data, like words, images, documents, or audio. In the world of AI, especially LLMs, everything gets turned into a vector. It’s how machines understand meaning, similarity, and context. Two vectors that are “close” to each other mathematically are assumed to be similar in meaning.
For example, let’s say your model is asked, “What’s a good alternative to Python for data science?” To give a smart answer, it needs to find information that isn’t a direct keyword match, but semantically relevant. Maybe it needs to surface something about R, Julia, or even SQL in certain contexts. That kind of fuzzy, concept-based matching is impossible with traditional databases — they don’t understand similarity, just exact matches or basic filters.
That’s where vector databases shine.
They allow you to index and search embeddings — those high-dimensional vectors generated by LLMs, computer vision models, or audio models. Instead of matching words or tags, they retrieve data based on proximity in vector space. This is critical for:
- Semantic search: Finding meaningfully similar documents or queries, not just keyword overlaps.
- Recommendations: Suggesting similar products, articles, or jobs based on previous preferences or behaviors.
- Context-aware retrieval: Powering RAG systems, where your LLM looks up relevant info before generating a response.
And they do all this fast, even when you’re dealing with millions (or billions) of vectors.
So when people ask, “What’s the main difference between vector databases and traditional databases?”, it’s this: traditional databases store structured data you retrieve with precision; vector databases store unstructured data you retrieve based on meaning.
And in the age of AI, meaning is everything.
How Vector Databases Power LLMs and Retrieval-Augmented Generation (RAG)
If you’ve worked with large language models long enough, you already know this: they forget. They hallucinate. They guess when they shouldn’t. And no matter how many parameters you throw at them, they’re still limited by the data they were trained on, which could be outdated, incomplete, or just plain wrong for your use case.
That’s where retrieval-augmented generation, or RAG, comes in. And vector databases are what make RAG possible.
Here’s the idea: instead of relying solely on what the LLM knows from training, you give it access to an external knowledge source. Something dynamic. Something you can update. When a user asks a question, your system searches that external database — using vectors to find semantically relevant content — and feeds that information into the prompt before the LLM generates a response.
Let’s say someone asks your AI assistant, “What’s PromptCloud’s approach to web scraping compliance?” If you’ve embedded your company’s documentation and stored those embeddings in a vector database, the system can instantly retrieve the relevant policy and pass it to the LLM as context. The result? A response that’s accurate, specific, and grounded in your data, not the LLM’s best guess.
Without vector databases, this flow breaks.
You can’t retrieve relevant context fast enough. You can’t search by meaning. And your system ends up either hallucinating or returning generic results.
This is exactly why vector databases for LLMs have become foundational. They act like long-term memory for AI — storing everything from internal documents and knowledge bases to support tickets, product manuals, or scraped datasets — and letting your model tap into that information in real time.
For companies building AI-powered search, knowledge assistants, or any domain-specific chatbot, this approach isn’t a nice-to-have anymore. It’s table stakes.
Real-World Use Cases of Vector Databases in AI Applications
Now that we’ve covered what vector databases are and how they support LLMs, let’s look at where they’re being used in the real world. These aren’t theoretical examples — these are the kinds of problems vector databases are solving right now, across industries.

Image Source: Scalablebpath
AI-Powered Semantic Search
Regular search engines basically scan for the exact words you type, so the user has to guess the right keywords. But people don’t always get the phrasing right, or they ramble on in a full sentence and still come up empty-handed.
That gap is where semantic search jumps in. It turns the query’s meaning into a short list of numbers, sticks those numbers into a special vector database, and lines them up with the same kind of numbers hidden inside every document. Suddenly, the engine can haul back files about car repair, even if someone asked about fixing an engine, emails about temp jobs, or 3-year-old support chats that barely match the search bar text.
This is already being used by customer support platforms, internal knowledge bases, legal tech companies, and academic research tools.
Recommendation Engines
From e-commerce platforms suggesting “you might also like” to streaming apps recommending the next show, recommendation systems depend on understanding what’s similar. Not just in product tags, but in user behavior, preferences, and context.
With vector databases, companies can build smarter recommendation engines that don’t rely on rigid rules. Instead, they can compare embeddings — say, of product descriptions, user history, or past purchases — and suggest semantically close items. This leads to better personalization and higher engagement.
Retrieval-Augmented Chatbots and Virtual Assistants
Most chatbots are either overly scripted or too generic. But when you combine an LLM with a vector database, the assistant gains the ability to pull in real-time, relevant information from your own data.
We’ve seen companies use this setup to build:
- HR bots that answer policy questions using embedded company documents
- Customer service agents trained on past interactions
- Sales assistants who surface product specs or feature comparisons
And behind the scenes? A vector database storing all that knowledge and powering fast, meaningful retrieval.
Similarity Search in Unstructured Data
Use cases aren’t limited to text. Companies also use vector databases to run similarity searches across:
- Images: Find visuals that look alike, even if they’re not tagged the same way
- Audio: Identify similar speech patterns or sound bites
- Code: Match functions or logic patterns in software repositories
This kind of cross-modal search — especially when powered by embeddings from models like CLIP or Whisper — is unlocking new ways to mine insights from unstructured data.
PromptCloud’s Role: High-Quality Datasets for Vector Search
All of this works only as well as the data you feed into the system. That’s where PromptCloud comes in. Our web scraping service delivers clean, structured, and domain-specific datasets — whether it’s product listings, job postings, news content, or financial data — ready for embedding into your AI pipelines.
If you’re building vector databases for AI models and need fresh, relevant content to feed your LLM, we help you get it — at scale, and without the noise.
Why Traditional Databases Don’t Cut It Anymore in the AI Era
It’s easy to assume that if you already have a reliable relational database — MySQL, PostgreSQL, or even a powerful data warehouse — you’re covered. But when it comes to powering AI systems, especially those involving semantic search or generative models, traditional databases just aren’t built for the job.
Let’s break down why.
Structured vs. Unstructured Data
Image Source: Kensho
Conventional databases perform well when the data resembles tidy rows and columns. Picture customer names aligned next to purchase dates, all neatly labeled within a predefined schema. That orderly arrangement is precisely where relational systems shine.
Large-language models, by contrast, are built for free-form text. They digest full-length articles, product reviews, email chains, and any snippet of language you can throw at them. Such material is inherently unstructured and defies the boxlike confines of a spreadsheet.
You can crank out extra SQL constraints to squeeze prose into tables, yet the effort quickly becomes a bureaucratic chore. In most cases, it’s far easier to let the text stay loose and let the model parse the mess on its own.
Keyword Search vs. Semantic Understanding
Relational databases can help you filter or search based on keywords or exact matches, but they can’t understand meaning. They don’t know that “software engineer” and “developer” might mean the same thing. They can’t tell you if two user reviews are saying similar things in different words. And they definitely can’t help an LLM find the most relevant chunk of context for a query.
That’s the key difference. Vector databases work on proximity in meaning, not just matching characters or rows.
Scale and Speed for High-Dimensional Search
AI models generate embeddings with hundreds or even thousands of dimensions. Searching through millions of these vectors efficiently is a completely different challenge from scanning a few indexed rows in a table.
Vector databases are optimized for this, with things like Approximate Nearest Neighbor (ANN) algorithms, GPU acceleration, and high-performance indexing. They’re designed to serve real-time search queries over large volumes of vectorized content, which just isn’t feasible with traditional tech.
Schema Flexibility and Iteration
AI systems evolve fast. You might start with one embedding model and switch to another. Your use case might expand from documents to images. You’ll want to experiment, iterate, and update fast.
Rigid schemas slow you down. Vector databases, on the other hand, are designed for flexibility, letting you plug in new vector types, change models, or re-embed content without breaking your data infrastructure.
Choosing the Right Vector Database for Your AI Stack
There’s no shortage of vector database options out there today — and that’s both a good and bad thing. Good, because you’ve got a choice. Bad, because not all vector databases are built the same, and picking the wrong one can bottleneck your entire AI workflow.
Let’s walk through what actually matters when selecting a vector database for LLMs or other AI applications.
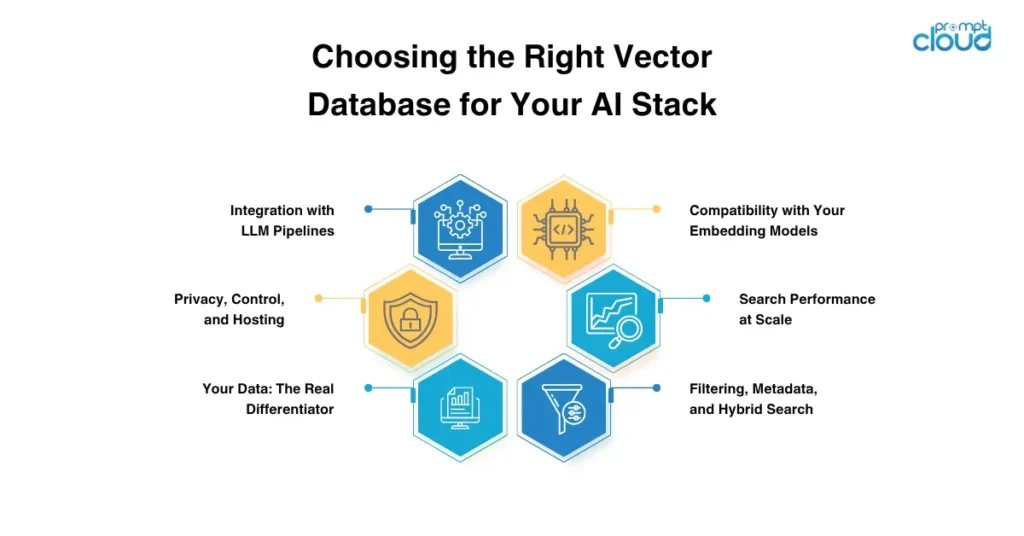
Compatibility with Your Embedding Models
This one’s foundational. The vector database you choose should easily accept embeddings from the models you use — whether it’s OpenAI’s text-embedding-3-small, Sentence Transformers, Cohere, or custom in-house models.
Even better? Support for mixed modal data — text, image, audio — if your use case demands it.
Look for systems that make it simple to push and index those vectors, without excessive pre-processing or rigid schemas.
Search Performance at Scale
Semantic search can get expensive fast, especially once you’re working with millions (or billions) of vectors. You want a database that supports approximate nearest neighbor (ANN) search and is optimized for speed without sacrificing too much accuracy.
Milvus, Weaviate, Pinecone, and Qdrant are some of the big names here, each with its own tradeoffs. Some are better for cloud-native deployments; others shine in high-throughput, self-hosted environments.
Filtering, Metadata, and Hybrid Search
In real-world applications, you often need more than just “find the most similar document.” You might want to search vectors within a certain time range, only for a specific customer segment, or filtered by product category.
Look for a system that supports metadata filtering alongside vector similarity, which is often called hybrid search. This becomes essential for use cases like e-commerce, finance, and enterprise knowledge retrieval.
Integration with LLM Pipelines
If you’re building a RAG system, vector storage is just one piece. You’ll also need to embed, store, retrieve, and feed context back to your model, often with multiple components working together.
Choose a vector database that plays well with your AI stack. That could mean:
- A clean Python SDK
- Native integrations with LangChain or LlamaIndex
- REST or gRPC APIs that are easy to call from your backend
- Streamlined support for updating, deleting, or re-embedding data
The smoother the integration, the faster you can prototype and scale.
Privacy, Control, and Hosting
Some vector-database solutions now sit on the market. Some are offered as fully managed services, while others ship as open-source software that you run on your own servers. The decision often hinges on how tightly you want to grip your underlying hardware.
Corporate users in regulated industries frequently lean toward self-hosted choices such as Milvus or Qdrant; each lets administrators dictate where data resides and who can reach it. Developers in the prototyping phase sometimes pick a managed option like Pinecone, since it spares them the overhead of rack space and network configuration.
Your Data: The Real Differentiator
Regardless of which system you pick, remember: your vectors are only as good as the data behind them.
That’s why companies building AI search or recommendation engines rely on PromptCloud’s web scraping service. We help you gather clean, reliable, domain-specific datasets — product listings, job posts, real estate data, travel inventories, and more, which you can embed and feed into your vector database for high-accuracy retrieval.
Clean data + a solid vector database = a fast, relevant, and scalable AI system.
Vector Databases Are the Quiet Engine Behind Smarter AI
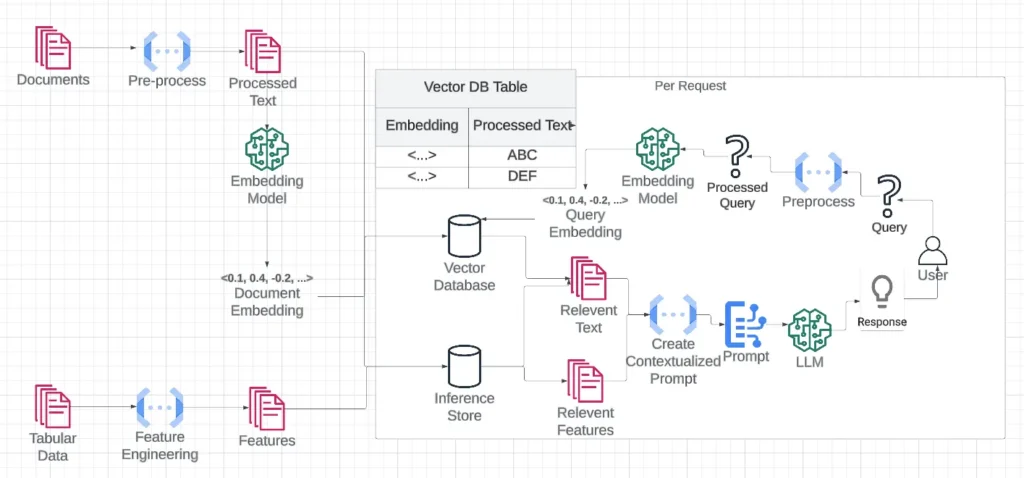
Image Source: Featureform
Building with AI today isn’t just about picking the right model. It’s about everything around it — how you manage context, how you retrieve the right data at the right moment, and how you scale without losing relevance.
That’s where vector databases show their value. They’ve gone from “nice-to-have” to essential — especially if you’re serious about LLMs that don’t hallucinate, chatbots that remember, or recommendations that make sense.
At their core, vector databases solve a simple but critical problem: how to search by meaning, not just keywords. And once you start thinking in those terms — once you’ve seen what they unlock — it’s hard to go back to anything else.
Of course, great infrastructure is only as good as the data flowing through it. That’s why a lot of teams use PromptCloud to get clean, structured, and reliable web data — the kind of content that feeds directly into vector databases and makes your AI smarter from day one.
FAQs
What are vector databases in simple terms?
Think of them as databases that store meaning instead of just words. They hold numeric versions of your data — called vectors — that represent things like text, images, or audio. These vectors let you search for “what feels similar” instead of exact matches.
Why do AI models need vector databases?
Because traditional databases don’t speak the same language as AI. LLMs think in vectors — high-dimensional math representations of words and concepts. A vector database gives them a way to store and retrieve that kind of data in a way that makes sense to the model.
What is the main difference between vector databases and traditional databases?
Traditional databases are built for clean, structured data, like spreadsheets. They’re great when you want exact matches. Vector databases, on the other hand, are built for messy, unstructured data and let you search by meaning or similarity. It’s a completely different way of thinking.
How are vector databases used in large language models (LLMs)?
In LLM setups, vector databases are often used in something called RAG (retrieval-augmented generation). When a user asks a question, the system uses the vector database to fetch the most relevant context—like documents, FAQs, or notes, and gives that to the LLM before it responds.
What are some examples of vector databases for AI applications?
Some of the popular ones right now are Pinecone, Weaviate, Milvus, Qdrant, and FAISS. Each one handles things a little differently — some are easier to use, some are faster, some are open-source. It depends on what your project needs.
Can vector databases be used with data from web scraping?
Yes, and that’s one of the best uses, honestly. Let’s say you scrape product descriptions or job listings from different websites — you can turn that data into vectors and store it in a vector DB. Then your AI can search through it semantically, not just by keyword. PromptCloud helps with this kind of data prep all the time.
Are vector databases only useful for text data?
Not at all. You can use them for images, audio, code — anything that can be turned into an embedding. Some systems even handle multiple types of data at once. If you can embed it, you can store and search it in a vector database.
How do I choose the right vector database for my AI project?
Start by asking what kind of data you’re working with and how fast or scalable the system needs to be. If you need a plug-and-play cloud service, Pinecone might be a good fit. If you want full control and don’t mind managing infrastructure, maybe Qdrant or Milvus. It also depends on whether you want hybrid search, metadata filtering, or tight integration with your LLM stack.
Do vector databases scale well for enterprise use?
Yes, the better ones do. They’re built with performance in mind, especially when you start dealing with millions of records. Just make sure you pick one that supports things like approximate search (ANN), sharding, or GPU acceleration if you’re expecting a heavy load.
How does PromptCloud fit into all this?
Most of the time, people get stuck because they don’t have enough high-quality data to start with. That’s where PromptCloud helps — we handle the messy work of collecting and cleaning large-scale web data. You bring the AI stack; we bring the data that feeds into your vector database and actually makes it useful.















