



Open source Hadoop is a cutting-edge tool for harvesting big data. What Hadoop does is remarkable: it takes the dice-rolling out of retail business and allows the focus to shift to the individual consumer by providing a customized retail experience. The beauty of Hadoop is that there are tangible practical advantages to boast about. No wonder, enterprises are using Hadoop for eCommerce and Retail.

See how enterprises use Big Data here.
MetaScale and Hadoop for eCommerce
MetaScale is one such Hadoop solution which also has Big Data training as a service and helps enterprises accelerate Hadoop implementation. MetaScale’s key impact factor is in solving capacity and cost problems that accompany swelling data demands. With retail, viable storage and efficient processing capabilities are the top demands. Hadoop and NoSQL provide Big Data value to retail enterprises particularly when used to refine analytics along with brand monitoring, product perception, sentiment analysis and inventory management.
Mitigating latency of voluminous data is another aspect where MetaScale outscores other Hadoop solutions. Processing data overnight for real-time application is a great Hadoop property which retailers use. Hadoop’s fundamental characteristic is that instead of tackling the Big Data iceberg head on, it chisels it to smaller packets such that each can be processed and analyzed at the same time!
Nothing troubles retailers more than ETL complexity. Extract, Transform and Load (ETL) refers to a process in database usage. Software cost and management of ETL invariably are so large that projects often fail at launch. Moreover, with conventional ETL techniques it can be weeks before data created is utilized effectively. With modern Big Data tools this latency is cut short to seconds and change the perception towards ETL. Hadoop especially is a genius at transforming ETL processing and reducing burgeoning costs.
MapR and Hadoop for Retail
Then there’s MapR, an enterprise-grade distribution for Hadoop that offers social media analysis, price evaluation and even a customer recommendation engine. Via Hadoop retailers can also push real-time recommendations at the right time—and device, thus providing a personalized customer experience. Examples of recommendation engines LinkedIn and Facebook’s “People You May Know” feature and Amazon’s “Customers Who Bought This Item Also Bought” features.
These recommendation engines are central to the retail industry since personalized assistance triggers the consumer on site to actually finish transactions and not move away to a competitor site. This also works counter-intuitively to record more of consumer’s browsing habits and purchasing behaviors leading to more data to craft an enhanced personalized experience!
DaaS and Hadoop
Data is integral to this process, and the easiest way to get data is by engaging a professional Data-as-a-Service (DaaS) provider. Standalone tools that help you crawl data are limited in their scope when it comes to magnitude of data. Professional website scraping and web crawling service providers are more reliable when it comes to up-times, real-time data gathering, and structuring data.
Market Basket Analysis and Hadoop
Since real-time data intelligence and processing is core to retail data’s success, another great Hadoop use-case is the ‘market basket analysis’. Popularly called MBA (Market Basket Analysis), uses data mining algorithms to find patterns in consumer behavior on-site. This is much like predicting what a consumer will do in a current session bases on historic data patterns.
The metrics here involve ‘support’ and ‘confidence’, which predict degree of interest a consumer has in buying in his, or her, active session. MBA thus is a useful indicator that can be used to devise new promotional initiatives and identifying optimal schemes. The fun part is that the MBA interface can be integrated with other standard business intelligence (BI) tools and can work independently for users as well as disparate data sets! All this through Hadoop which establishes a transparent interaction with BI.
Big Data and Hadoop
Since Hadoop’s prime functional advantage is making Big Data more viable, knowing how to select appropriate hardware is critical. Prima facie, there is no “ideal cluster configuration” that is standard. Hardware specifications are dependent on the balance sought between performance and economy. Distribution of workload vis-à-vis testing and validation is equally important.
Workloads matter because bottlenecks in data recording, reading and processing have to be avoided. This is achieved in two ways: network (or IO-bound job) and data processing (CPU-bound). Indexing, grouping, exporting and transformation constitute IO-bound jobs, whereas clustering, text mining, NLP and extraction make up for CPU-bound functions. Here too DaaS providers prove useful since large sets of unstructured data is cumbersome to sort. PromptCloud’s structured data delivery via REST-API makes an ideal case of importing data easily into the Hadoop cluster.
Software modules to consider while sizing Hadoop infrastructure include gems like Apache HBase, Cloudera Impala, and Cloudera Search.
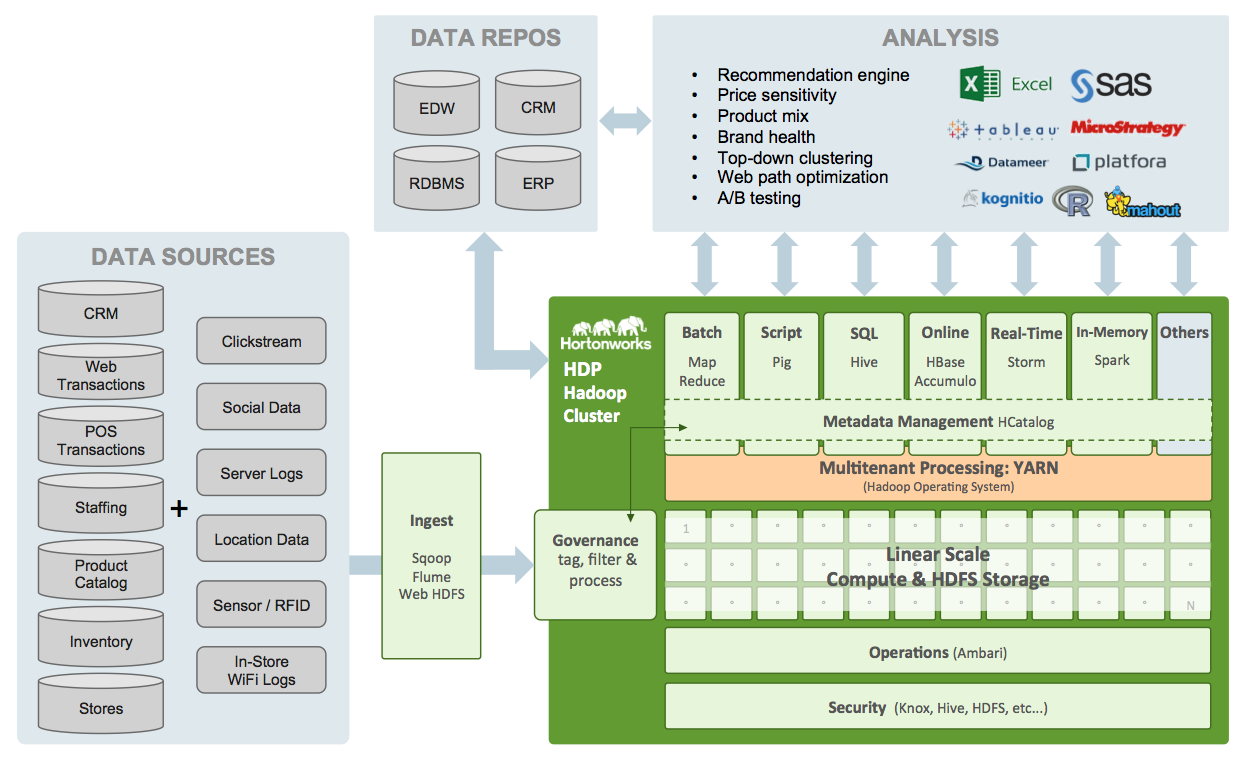
It’s no rocket science to measure workloads and predict where bottlenecks could be meet. A simple data monitoring system in place ensures that the data imminent is levelled out in the Hadoop cluster. These monitors can also check system health and keep tabs on machine performance.
The key to Hadoop is that its ecosystem is finest for parallel processing. Benchmarking Hadoop performance and magnitude is thus important for retailers. The appropriate step would be to ascertain theoretically the use-case and then reverse engineer the processing capacity for optimum use of data.
While Hadoop is the poster-boy for Big Data adoption, there are limitations that enterprises, especially retailers may face with it. One of them has to do with its root: Hadoop is for BIG data. Before deploying Hadoop for business, questions must be asked on the scale that it is going to be used for, like how much data is there, is there a torrent or a trickle of continuous data or perhaps the most pertinent: how much of the data will be used.
Hadoop for eCommerce and Retail
The pros of Hadoop in Retail far outweigh its cons. The above mentioned instances are but a few instances on building, operating and supporting retail big data operations with Hadoop. The future for retail is poised on the increasing use of Hadoop, and one that will transform the way retail business is done.
See the makeover of e-commerce by Big Data here: SlideShare.















