




**TL;DR**
Most teams sit on more data than they can use. The trick isn’t collecting more; it’s mining what you already have to surface patterns you can act on. In plain language, this guide explains core data mining techniques clustering, classification, association rules, regression, anomaly detection and where each one shines. You’ll see how techniques work together in a simple pipeline, how to pick the right method for the job, and how companies apply them in the real world: retail, finance, manufacturing, healthcare, and marketing.
We’ll also cover the last mile (turning insights into decisions), common pitfalls (data quality, drift, compliance), and what’s changing as AI agents automate more of the grunt work. If you’ve felt stuck between busy dashboards and slow decisions, this is your map from noise to next step. You’ll find practical examples, clean transitions, and zero academic fluff just the parts that matter when the goal is a better decision by Friday.
How Data Mining Techniques Turn Raw Information into Business Intelligence
Picture everything your business touches in a week. Orders. Returns. Chat transcripts. Review snippets. Supplier feed updates. Now imagine those signals arranged like a city seen from above streets, neighborhoods, shortcuts. Data mining is the helicopter view. It reveals the paths people take, the corners where friction lives, and the routes you should open next.
A few years ago, most teams ran monthly reports and argued from opinion. Today, the edge comes from recognizing repeatable patterns inside messy behavioral data and getting those patterns in front of the people who make the call category managers, fraud teams, planners, marketers. The math sits in the background. The outcome is simple: know sooner, act sooner.
In this guide, we’ll keep it practical. We’ll cover the building blocks (clustering, classification, association, regression, anomalies), how those methods work together in a tidy pipeline, the main types of mining (descriptive, diagnostic, predictive, prescriptive), and where they pay off. We’ll close with the hard parts activation, measurement, ethics and what’s next as AI turns mining into a more adaptive, always-on system.
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema.
The Building Blocks of Data Mining: The Techniques You’ll Actually Use
Let’s keep the cast list short and useful. These are the methods you’ll reach for most days.
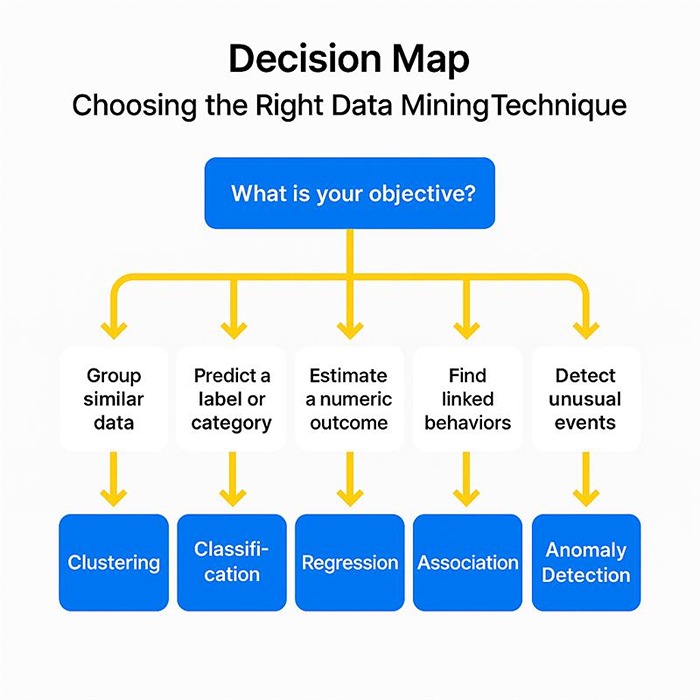
Figure 2: Decision Map – a simple flowchart showing how to choose the right data mining technique based on business objectives, from grouping data to detecting anomalies.
Clustering
Unlabeled data, natural groupings. You let the algorithm find “people who behave alike.” Retailers segment shoppers beyond demographics; ops teams cluster locations with similar demand patterns; product teams spot feature usage tribes. It’s the “show me the hidden neighborhoods” tool.
Classification
Labeled data, known categories. You train on examples, then predict new cases: approve or decline, spam or not, churn risk high or low. Banks, content filters, and customer success teams rely on it. The mental model: past judgments, learned and repeated at scale.
Association rules
What tends to occur together. The classic market-basket example still holds, but the idea travels—features used in the same session, errors that co-occur, claims that arrive in pairs. It powers cross-sell, bundling, and layout decisions.
Regression and predictive modeling
Numbers into forecasts. You estimate a continuous outcome: next week’s units, expected time to failure, the lift from a promotion. When combined with seasonality, events, or competitor data, it becomes a quiet workhorse for plan-versus-actual.
Anomaly detection
Find the weird thing early. Outliers aren’t always bad; they’re just different. In payments, it’s fraud. In production lines, it’s a fault. In marketing, it’s a sudden spike worth learning from. The value is the alert that lands before someone notices by hand.
A quick at-a-glance:
| Technique | What it answers | Typical move |
| Clustering | “Who behaves alike?” | Segment, prioritize, localize |
| Classification | “Which bucket?” | Automate a decision, triage |
| Association | “What co-occurs?” | Cross-sell, bundle, arrange |
| Regression | “How much / when?” | Forecast, plan, simulate |
| Anomalies | “What’s odd?” | Investigate, prevent, learn |
If you want the broader landscape in one place, this comprehensive overview of data mining techniques from DATAVERSITY is a handy reference point.
And when your raw material comes from the public web, getting the extraction right at scale matters this breakdown of large-scale web scraping challenges shows what typically breaks and how to keep feeds clean and steady.
How the Pieces Fit: A Simple Pipeline That Doesn’t Waste Anyone’s Time
Mining isn’t a hero model; it’s a flow. Keep the flow sane and everything downstream gets easier.
1) Collect and prepare
Most data doesn’t arrive in a neat table. It shows up late, missing fields, or in five formats. You deduplicate, standardize units, fix dates, and flag gaps. If you depend on external signals competitor prices, availability, reviews make sure your collection layer doesn’t crumble the moment a site changes. Managed pipelines or AI web scraping agents help here.
2) Explore and discover patterns
Start with clustering to see the shape of the crowd. Layer association rules to reveal natural pairings. This is where you ask better questions and stop modeling blindly.
3) Build and validate models
Split train/test, keep a clean holdout, and measure with metrics the business understands. Precision/recall matters, sure but tie it to “false positives per 10k orders” or “missed fraud per month.” Humans decide; speak human.
4) Explain and visualize
A crisp chart beats a wall of coefficients. Cluster maps that name the segments. Threshold plots that show where risk spikes. A small number of views placed in the tools teams already use.
5) Operate and learn
Schedule refresh, monitor drift, log every decision the model helps make. When the world shifts season, policy, competitor move you want the pipeline to adapt, not wait for a quarterly re-train. This is also where GenAI and scraping quietly help: rapid schema discovery, quick enrichment from public pages, and faster documentation for non-technical readers.
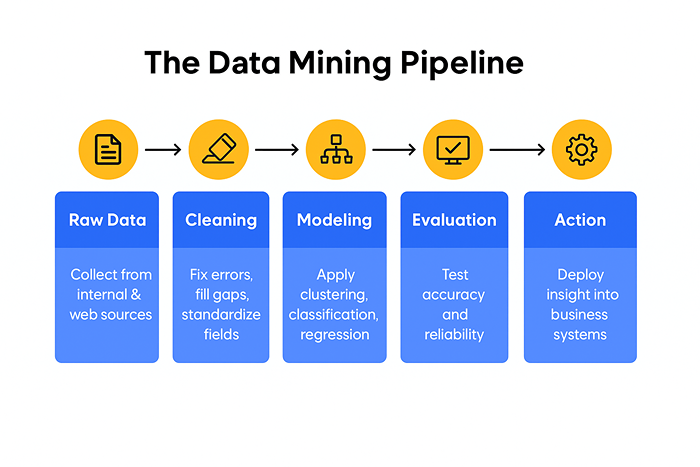
Figure 1: The Data Mining Pipeline – a five-stage visual summarizing how raw data is collected, cleaned, modeled, evaluated, and finally transformed into business action.
The Main Types of Data Mining and When Each One Earns Its Keep
You don’t need every type in every project. Pick for the job at hand.
Descriptive
“Show me what’s going on.” Summaries, clusters, frequent pairs. Great for new markets, messy catalogs, unknown traffic sources. You exit with a clearer map.
Diagnostic
“Tell me why that happened.” You chase root causes with correlation analysis, controlled comparisons, and enriched context. A spike in returns? Maybe the spike is a single SKU with a mislabeled size chart.
Predictive
“What’s likely next if we do nothing?” Forecast units, risk, or propensity. Feed retention plays, capacity plans, and promised SLAs. The trick is frequent refresh; stale predictions are worse than no predictions.
Prescriptive
“What should we do about it?” You simulate and optimize—pricing bands, routing choices, promotion timing. This is where business rules and model outputs meet.
Outlier-focused
“What doesn’t belong?” Fraud screens, defect alerts, sudden surges. The gold is in catching it early and learning whether it’s a problem… or a pattern worth scaling.
Midway reality check: you’ll rarely run these in isolation. A day-to-day workflow might look like cluster → explain → predict → prescribe, with anomaly alerts watching the edges.
Where the Value Shows Up: Five Clear Applications
We’ll keep it concrete. Short scene, clear payoff.
Retail and ecommerce
Clustering carves out behavior-based segments; association rules drive bundles; predictive modeling protects you from the out-of-stock weekend. Teams that pull competitor shelf data from the web in near real time react faster on price and placement—no guesswork, just live context.
Finance and banking
Classification and anomalies are the backbone: underwriting, transaction screening, early churn flags. The human part doesn’t disappear; it just focuses on edge cases instead of rubber-stamping the obvious.
Manufacturing and supply
Regression forecasts output. Anomalies catch quality issues before the line stops. Predictive maintenance feels like magic when the “fix it Tuesday” alert prevents a week of pain. External signals—component availability, competitor SKUs—round out the plan.
Healthcare
Cluster patients by symptom patterns. Classify likely outcomes to triage. Predict readmission risk and intervene. The ethics matter here: review bias, explain choices, keep humans in the loop. Speed helps, but trust keeps programs alive.
Marketing and media
Sentiment + classification gives you a live pulse on topics, tone, and channels. When reviews move, messaging moves. If you need a primer on scaling this with structured review data, this brief lays out the basics in plain English: Across all five, the thread is the same: the win isn’t the model; it’s the faster, calmer decision your team can make on a Tuesday afternoon.
From Insight to Action: Make the Output Change the Work
Most mining projects die in a dashboard. Let’s not.
Translate insight to context
“Region A churn risk is up” is noise until someone explains the why. Slower response times? A competitor undercut? Pair outputs with a short human note: what it likely means, who should act, what to check first.
Build decision loops, not reports
Wire outputs into tools that do things: approvals, pricing, routing, inventory. If a threshold trips, the system nudges orders or opens a ticket. Awareness is nice; automation pays the bills.
Blend internal and external data
CRM tells you who. The public web tells you what’s changing around them. Real lift appears when you combine both competitor promos layered over your cart data, review themes matched to returns, local stock mapped against your ad spend.
Measure the change
Tie each model to one metric and review it on cadence. “This segment program should raise the repeat rate by 3 points.” “This fraud rule should cut false positives by 20%.” Keep score. If it doesn’t move, fix it or stop it.
For teams building AI training and test sets, synthetic datasets can speed iteration while avoiding privacy landmines. Here’s a practical take on where they fit with scraping.
The Hard Parts (and How to Keep Moving)
A few bumps everyone hits and how to navigate them without drama.
Data quality
Bad IDs, messy units, partial events. Solve locally (validation, contracts, schema tests) and upstream (clean extraction). If external sources power your pipeline, stabilize the collection first so your models aren’t riding a roller coaster.
Model drift
The world shifts, slowly or all at once. Watch performance over time, not just at launch. Retrain triggers help. So does a simple playbook: when to fall back to rules, when to raise thresholds, who gets paged.
Compliance and trust
Read the rules. Document your sources. For public web data, treat robots, terms, and rate limits as table stakes. Keep explanations ready for regulated decisions; if a customer asks “why was I denied,” you need an answer a human can say out loud.
People and adoption
If the output doesn’t fit the way teams already work, it won’t stick. The craft is less “perfect model” and more “useful nudge inside the tool they open every morning.”
What’s Next: Quicker Loops, Calmer Decisions
We’re leaving the era of monthly refresh. AI agents adapt to site changes, scrapers run when events fire, and models retrain with less hand-holding. The goal isn’t flashier charts; it’s quieter wins—fewer stock-outs, smoother approvals, promotions that hit the moment the context is right.
If there’s a north star here, it’s decision intelligence: mining, AI, and automation stitched into one reflex. You ask a practical question. The system answers with evidence, options, and a suggested move. You confirm, adjust, and watch the outcome. Then it learns.
That’s the loop. That’s the edge.
From Information to Impact: The Real Win in Data Mining
Data mining isn’t about collecting more. It’s about seeing sooner and then doing the obvious next thing with less debate. Over the past few years, we’ve watched teams go from slow status meetings to steady, almost boring improvements: price changes that land on time, fraud caught before it hurts, demand plans that don’t swing like a pendulum.
You don’t need to chase every technique. You need a small set that you trust, a pipeline that doesn’t wobble, and a culture that asks, “what changed after we acted?” Keep the flow tight. Keep the questions plain. Let the data do the heavy lifting in the background while your people make the call in front.
Human-in-the-Loop Data Mining: Why the Future Isn’t Fully Automated Yet
Automation gets all the spotlight. Everyone’s chasing “hands-off intelligence,” pipelines that retrain themselves, and dashboards that whisper the next move. But here’s the quiet truth—data mining still works best when humans stay in the loop.
Even the smartest models have blind spots, and the cost of a wrong assumption at scale can be huge. A mislabeled data feed can distort pricing across hundreds of SKUs. A drifted classifier can reject good loan applications or misflag legitimate transactions. Machines don’t feel when something’s off; people do.
1. Pattern Recognition vs. Pattern Understanding
Algorithms recognize patterns. People understand them. Clustering might show that a group of customers suddenly shifted from budget to premium purchases. But is that trend permanent, or just the effect of a holiday discount?
A model can’t tell the difference between genuine behavior change and short-term noise unless a human checks the context promotion calendar, competitor activity, even the weather. That’s why the most resilient data mining setups include an explicit review layer: analysts who validate anomalies, flag false positives, and retrain models with feedback that algorithms alone can’t infer.
2. The Feedback Loop That Teaches Machines to Judge Better
“Human-in-the-loop” isn’t about replacing automation. It’s about teaching it judgment. When analysts label new data, override model decisions, or provide reasons for exceptions, those signals become training material. Over time, systems learn when to trust themselves and when to defer.
Picture a fraud detection engine that flags suspicious refunds. In the first month, half of them are noise. Analysts mark the false alarms. By month three, the model has internalized those corrections and stopped wasting time on them. That’s machine learning growing under human supervision not raw automation, but guided evolution.
3. The Role of Explainability and Trust
In high-stakes fields finance, healthcare, hiring transparency isn’t optional. Executives don’t approve model outputs they can’t explain to regulators or customers. This is where explainable AI (XAI) meets data mining. Techniques like SHAP values and LIME highlight which features influenced a prediction.
Still, someone needs to interpret those visuals in human language: “Age contributed 30% to the churn prediction because older customers prefer call-center support.”
Explainability builds confidence. It’s easier to act on an insight when you understand why it’s true.
4. Why Domain Expertise Still Wins
The most underrated skill in data mining isn’t SQL – its domain intuition. A retail analyst knows which seasonal patterns are real. A supply-chain planner knows when anomalies signal a vendor issue instead of a data glitch. And a marketing strategist can tell when sentiment spikes because of a campaign not because the product suddenly got better overnight.
These micro-judgments feed back into model design: feature selection, weighting, thresholds. Without that human texture, models often look “mathematically correct but strategically useless.”
5. The Middle Ground: Semi-Automated Decision Systems
The next wave isn’t full automation, it’s semi-autonomous loops. Systems that run continuously but invite human approval when confidence drops below a threshold. Imagine a predictive model that automatically adjusts ad bids unless the variance exceeds 20%, at which point it pings a manager for review. You get speed and control a balance between responsiveness and oversight.
These hybrid setups are where PromptCloud’s real-time data feeds shine. When web data updates dynamically, say, new competitor prices or changing stock statuses the model reacts automatically, but humans decide when the deviation justifies an intervention.
6. Why This Matters Now
As compliance rules tighten and AI systems touch more decisions, organizations are rediscovering a basic truth: you don’t remove humans from the loop, you redesign their role. Tomorrow’s analysts won’t be spreadsheet jockeys; they’ll be data editors curators of context who keep automation honest.
That’s the paradox of progress in data mining: the smarter the system becomes, the more valuable human judgment gets. Machines scale precision; people protect meaning. Together, they make decisions worth trusting.
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema.
FAQs
1) What’s the fastest way to pick a technique without overthinking it?
Start with the question. Grouping or segmentation? Try clustering. A yes/no decision? Classification. A number to forecast? Regression. A weird blip? Anomaly detection. Keep it this simple at the start.
2) We already have dashboards. Why add data mining?
Dashboards describe. Mining explains, predicts, and prescribes. It moves you from “what happened” to “what to do next,” which is the piece most teams are missing.
3) How much data do we need to see value?
Less than you think. A few months of clean transactions or sessions can power early segmentation, forecasts, and risk screens. More data helps, but clarity beats volume.
4) What usually stalls projects after a good proof-of-concept?
The handoff. Insights stuck in a slide deck, no automation, no owner, no metric. Decide the action and the owner before you train the model.
5) Where does PromptCloud fit in this picture?
If external web data matters prices, stock, reviews, specs we handle the heavy lift: compliant collection, self-healing extraction, validation, and delivery to your warehouse or lake. Your team focuses on the signal, not the scraping.















