




Let’s skip the buzzwords and get to the question you’re probably already wrestling with: Should we build our own data acquisition system, or should we outsource it?
Every company that’s using data runs into this decision. You need web data—product prices, competitor listings, reviews, job postings, news updates, you name it—and you need it in a way that’s fast, scalable, and doesn’t break every time a website changes something minor.
But here’s the catch: the way you go about acquiring that data isn’t just a technical decision. It’s a strategic one. Choosing between building your own scrapers and infrastructure versus partnering with a web scraping provider will affect cost, time-to-market, in-house expertise, maintenance load, and even your agility as a business.
This article breaks down the build vs buy dilemma in the most practical terms possible. No tech jargon, no hand-wavy arguments—just straight talk on what each path involves, what to expect, and how to decide which one fits your business needs.
We’ll walk through:
- What data acquisition means in 2025 (and why it’s not just an IT problem anymore)
- What building an in-house system takes, beyond the hopeful idea
- Why outsourcing web scraping isn’t “cutting corners” but a way to move faster
- What factors should drive your final decision: cost, control, scalability, and more
Whether you’re a business leader, a data manager, or the IT decision-maker caught between two options, this is the guide you want before committing budget or headcount.
Let’s start by getting clear on what data acquisition really involves—and why it matters more than ever.
What Building Your Own Data Acquisition System Takes
The idea of building your own data acquisition system sounds great on paper. More control. More customization. Your data, your infrastructure, your rules.
But here’s the truth: building isn’t the hard part; maintaining it is.
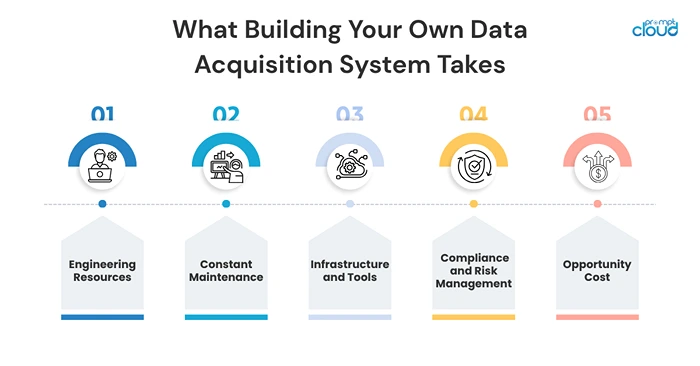
Let’s break it down. If you go the in-house route, here’s what you’re signing up for:
1. Engineering Resources (More Than You Think)
You’ll need developers who not only know how to write scrapers but who understand how to build scalable data pipelines. That includes setting up proxy management, handling IP rotation, parsing complex HTML structures, bypassing bot detection systems, and building retry logic when sites fail (because they will). And that’s just the scraper part.
You also need DevOps support to manage infrastructure, cloud costs, storage, scheduling, monitoring, logging, and alerts—the entire backend. This quickly becomes a full-time responsibility.
2. Constant Maintenance
Websites change. Selectors break. Anti-bot systems evolve. What worked last week might silently fail today. That means your team needs to monitor scraper health constantly, debug failed runs, update scripts, and keep data pipelines stable across every target site.
3. Infrastructure and Tools
Building means provisioning servers or cloud instances, managing load, scaling crawlers, setting up databases or data lakes, and making sure nothing hits rate limits or gets your IPs banned. And when you scale up? Costs scale, too. Not linearly. Rapidly.
4. Compliance and Risk Management
If your team is collecting data at scale, you also need to stay on top of legal and ethical concerns. Things like complying with site terms, respecting robots.txt, managing PII, and keeping up with evolving data laws (GDPR, CCPA, etc.)—that’s on you.
5. Opportunity Cost
This one’s harder to quantify, but important: Every hour your team spends building and fixing a scraping pipeline is an hour they’re not spending on your actual product, strategy, or analytics. Do you want your best engineers solving parsing bugs or building features that impact revenue?
Now, does that mean building is always the wrong move? Not necessarily. If you’re a large company with deep technical talent, a stable set of data sources, and very specific customization needs, building might make sense.
But for most businesses, especially those moving fast or operating with lean teams, building quickly turns into a costly distraction.
Why More Businesses Are Buying Their Data Acquisition Infrastructure Instead
When companies hit the wall with internal scrapers—or see the first real maintenance bill—many start looking at the alternative: outsourcing data acquisition to a web scraping service provider.
And no, this doesn’t mean handing over control or settling for “one-size-fits-all” data. Quite the opposite. Specialized providers have spent years building tools, infrastructure, and expertise for one single purpose: acquiring large-scale, accurate, ready-to-use web data, so you don’t have to.
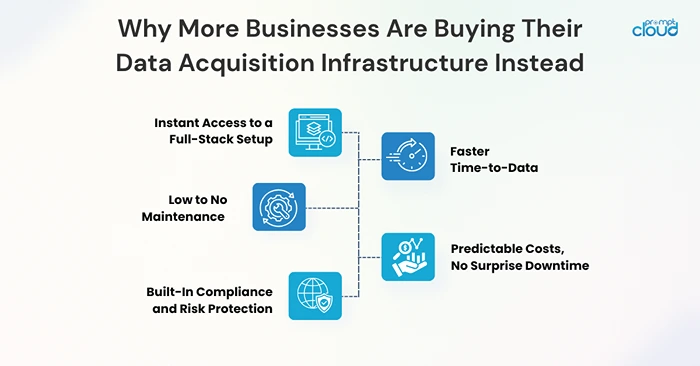
Here’s what that actually looks like:
1. Instant Access to a Full-Stack Setup
Instead of building everything from scratch—scrapers, proxy rotation, monitoring, data pipelines—you plug into an existing infrastructure that already works at scale. Providers like PromptCloud have already solved the hard parts, from handling dynamic sites to maintaining data accuracy across hundreds of sources.
You skip the trial-and-error. You skip the 3 AM alert that your crawler broke. You just get clean, structured data in the format you need—delivered where you need it.
2. Faster Time-to-Data
Getting an in-house setup off the ground can take weeks or months. Buying? You could have fresh data in your dashboard by next week. That time savings matters when your competitors are adjusting prices, launching features, or responding to market shifts in real time.
Speed isn’t a luxury here—it’s leverage.
3. Low to No Maintenance
This is a big one. When you outsource, you’re not on the hook for fixing broken scripts, updating HTML selectors, or scaling infrastructure when traffic spikes. The provider handles all of that. You focus on using the data, not constantly fixing the plumbing behind it.
4. Predictable Costs, No Surprise Downtime
Building in-house might feel “free” at first—until engineering time, cloud costs, and firefighting hours start piling up. With a data-as-a-service model, you know exactly what you’re paying, and what you’re getting. No spiraling dev costs. No guesswork.
5. Built-In Compliance and Risk Protection
Top-tier providers stay up to date with the legal side of acquiring data. That includes respecting site policies, filtering out PII, complying with relevant data privacy laws, and maintaining ethical scraping practices. You don’t need to hire a lawyer to interpret a robots.txt file.
This is why so many high-growth teams, product leaders, and data managers now lean toward buying. It removes friction. It removes risk. And it gets you what you actually need: reliable data that doesn’t slow you down.
But of course, there’s no one-size-fits-all. So let’s bring it all together in the next section: how do you actually decide whether to build or buy?
What trade-offs should drive your decision?
Build vs Buy for Data Acquisition: How to Make the Right Call
You’ve got two paths in front of you. Build your own system, or buy from a provider who’s done it before. So, how do you decide?
This isn’t about flipping a coin or defaulting to what your competitors are doing. It comes down to a handful of core factors—and how they line up with your business goals, team capabilities, and timeline.
Let’s break down the ones that matter most.
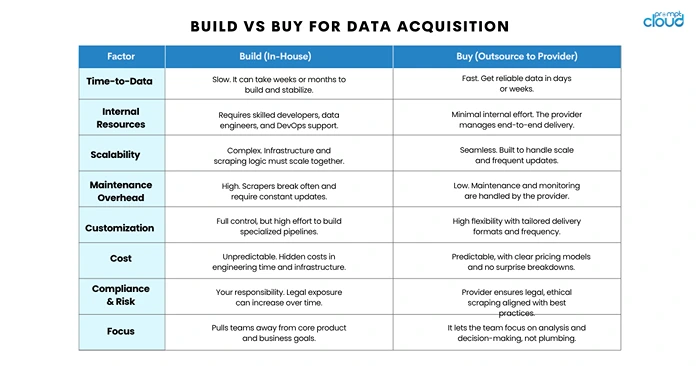
1. Time-to-Data
If speed is critical—say, you’re launching in a new market or need live data to feed pricing models—you probably don’t have months to build, test, and stabilize an in-house system. Outsourcing lets you move faster. Providers already have infrastructure, frameworks, and team muscle memory to get your data pipelines running within days or weeks.
If you’re in a slower industry or still in R&D mode, building might be feasible. But ask yourself: how much are delays costing you?
2. Internal Expertise and Bandwidth
Do you have engineers on hand who’ve built large-scale scrapers before? Not interns with Python scripts—people who can handle IP rotation, deal with captchas, manage proxy pools, and build resilient pipelines.
If the answer is no, and you don’t want your existing team pulled away from core product work, buying starts to look a lot more attractive. You get access to years of scraping expertise without having to build it from scratch.
3. Scalability and Maintenance
Building something that works once is easy. Keeping it working across 50+ target sites, with daily changes, across time zones, traffic spikes, and layout shifts? That’s another story.
Ask yourself: Do you want to be in the business of monitoring scrapers, or using the data?
If you expect your data acquisition needs to grow fast—or get more complex—outsourcing gives you the flexibility to scale without bottlenecks.
4. Cost and ROI
Let’s be honest: building often feels cheaper upfront. But it rarely is. Between developer time, infrastructure costs, data engineering, legal reviews, and opportunity cost, the total cost of ownership usually creeps far past the original budget.
Buying, on the other hand, gives you a predictable spend model. You know what you’re paying, and you get measurable ROI—clean, ready-to-use data, without delays or breakdowns.
5. Customization and Control
This is often the one area where building wins. If you need something hyper-specific—custom workflows, niche data enrichment, or integration with a legacy system—then building in-house gives you full control.
That said, many modern scraping providers (like PromptCloud) offer customized data pipelines, not just off-the-shelf feeds. So before assuming you’ll lose flexibility, ask what’s actually possible.
The Bottom Line?
If your core business is something other than building and maintaining scrapers—and you want to move fast, stay lean, and scale without the headache—buying is often the smarter play. It’s not about “cutting corners.” It’s about focusing your resources where they matter most.
In the next section, we’ll recap the core benefits of choosing a specialized web scraping provider and what that partnership can unlock for your business.
Why Choose Web Scraping Services Over Building In-House
So, let’s say you’ve looked at the build vs buy comparison and you’re leaning toward outsourcing. Good. But if you’re still wondering whether that means giving up control or settling for “cookie-cutter” solutions, you’re not alone.
The reality? That’s not what modern web scraping services look like anymore.
Here’s what partnering with the right provider really offers:
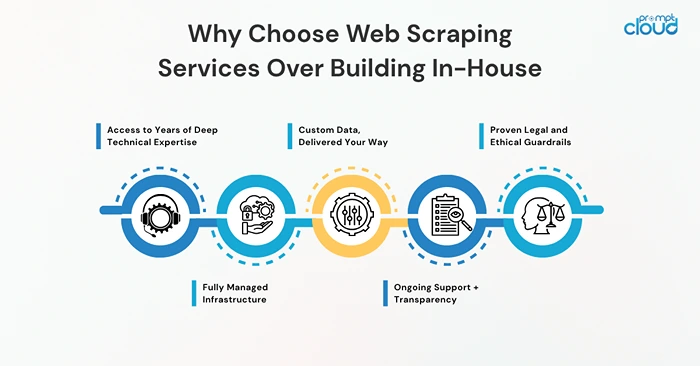
1. Access to Years of Deep Technical Expertise
Web scraping isn’t just about pulling HTML. It’s about working around anti-bot systems, structuring messy data, handling rate limits, rotating IPs, solving captchas, managing thousands of concurrent requests, and delivering clean, usable output—all without breaking anything.
Scraping providers like PromptCloud have spent years perfecting this. That expertise doesn’t live in most in-house teams, and frankly, it doesn’t need to.
2. Fully Managed Infrastructure
When you buy a scraping service, you’re not just buying data—you’re buying an invisible tech stack that scales automatically. No server provisioning. No container orchestration. No panic when a website changes its layout overnight.
You tell them what data you need, where it should be delivered, and how often—and it just shows up, ready to use.
3. Custom Data, Delivered Your Way
This isn’t a marketplace full of pre-crawled data dumps. You can define the exact sources, fields, and frequency. Want daily prices from 50 e-commerce sites? Sure. Need weekly job postings from a curated list of job boards across three countries? Done.
The point is: buying doesn’t mean compromising. If anything, it means getting exactly what you want, without having to build and babysit the system yourself.
4. Ongoing Support + Transparency
A good provider doesn’t just deliver data. They partner with you. That means transparent SLAs, clear communication, regular monitoring reports, and flexibility to scale up (or down) as your needs evolve.
If something breaks, you’re not opening a Jira ticket and hoping someone gets to it eventually. You have a team that’s already watching the pipeline, often fixing issues before you even notice.
5. Proven Legal and Ethical Guardrails
Navigating the legal side of scraping is no joke. Site terms, consent rules, data privacy laws—they evolve constantly, and mistakes can be costly.
Established scraping providers have legal frameworks, audit logs, consent mechanisms, and filtering logic built in. You’re not just avoiding legal headaches—you’re outsourcing that risk entirely.
In short? If your business relies on data—but not on scraping as a core competency—then buying web scraping services isn’t a shortcut. It’s just smart business.
You’ll move faster. Burn fewer resources. Get cleaner data. And free your internal team to work on what they were actually hired to do.
Build vs Buy Isn’t Just Technical. It’s Strategic.
At the surface, “build vs buy” sounds like a tech question. Hire developers or hire a vendor? Spin up a scraper or plug into a platform?
But if you’ve read this far, you know it goes deeper than that.
This decision is about how your business moves.
It’s about where you focus your time, where you invest your talent, and how quickly you can respond to the market. It’s about whether your data acquisition strategy is setting you up to grow or quietly holding you back.
Here’s what it comes down to:
- If you have the technical talent, time, and patience to build and maintain your own system, and if that system is core to your product or advantage, building might be right.
- But if you need scale, speed, reliability, and the ability to move fast without drowning in maintenance, buying from a specialized data acquisition provider is almost always the smarter bet.
This isn’t just about scraping data—it’s about enabling your team to spend less time on infrastructure and more time on impact.
At PromptCloud, we’ve helped startups, enterprises, and global brands simplify their data acquisition needs with fully managed, tailored web scraping solutions. And here’s the thing: once they make the shift, they rarely look back.
Because once you stop worrying about how the data gets there, you can focus on what to do with it. Schedule a demo with our experts today!
FAQs
1. What is data acquisition in business?
Data acquisition refers to the process of collecting, extracting, and preparing data from different sources—such as websites, APIs, or databases—for use in analytics, decision-making, or automation. For most modern businesses, acquiring data at scale is essential for market intelligence, pricing strategies, and customer insights.
2. What’s the difference between building and buying a data acquisition system?
Building means developing your own scrapers, pipelines, and infrastructure internally. Buying means outsourcing the process to a web scraping service or data provider that handles everything, from collection to delivery. The trade-off is between control and convenience, but more importantly, between maintenance burden and operational speed.
3. Is it cheaper to build a data acquisition system in-house?
Not always. While building might appear cheaper at first, long-term costs add up fast, including developer hours, infrastructure, maintenance, monitoring, and compliance risks. Many companies underestimate the true cost of acquiring data internally, especially at scale.
4. When does it make sense to build your own data acquisition system?
If data acquisition is central to your core product, or if you have highly custom needs and a team with deep scraping and infrastructure experience, building might make sense. But it’s rare. Most teams end up building something fragile, slow to scale, and expensive to maintain.
5. How does outsourcing data acquisition work?
You define the data you need—sources, fields, frequency, and delivery format—and the provider handles the rest. A good web scraping service will manage everything from crawling and parsing to infrastructure and legal compliance, delivering ready-to-use data via API, cloud storage, or direct integrations.
6. Will I lose control of the data if I outsource it?
Not at all. You still define the data requirements and own the output. In fact, many providers offer custom configurations that let you choose sources, formats, scheduling, and filtering. It’s your data, just without the operational headaches.
7. How do web scraping services handle compliance and legal risks?
Top-tier data providers follow ethical scraping practices, honor robots.txt directives where necessary, avoid scraping personal data (PII), and align with data privacy laws like GDPR or CCPA. They also advise clients on how to stay on the right side of the terms of service.
8. What happens if a target website changes its structure?
If you’ve built in-house, your scrapers will likely break and need to be fixed manually. With a managed web scraping service, the provider usually detects changes automatically and updates the crawling logic without interrupting your data feed.
9. Can I scale data acquisition quickly if I outsource it?
Yes. One of the biggest advantages of buying is scalability. Need data from 10 sites today and 200 next month? A reliable provider will scale infrastructure and resources instantly, with zero impact on your internal team
10. How do I know if I’m ready to switch from in-house to a web scraping service?
If you’re struggling with scraper maintenance, your data isn’t consistent, your team is stretched, or you’re not getting the data fast enough to act on it, that’s your signal. Outsourcing lets you get back to focusing on what you do best—using the data, not collecting it.















