




Web scraping via automated web scraping tools is pivotal for organizations seeking to leverage big data. It enables automated scraping of relevant information from various web sources, which is essential for data-driven analysis.
By extracting current market trends, consumer preferences, and competitive insights, companies can:
- Make informed strategic choices
- Tailor products to customer needs
- Optimize pricing for market competitiveness
- Increase operational efficiency
Furthermore, when merged with analytics tools, scraped data underpins predictive models, enriching decision-making processes. This competitive intelligence propels enterprises to anticipate market shifts and act proactively, maintaining a critical edge in their respective sectors.
11 Key Features in Automated Web Scraping Tools That Enterprises Should Look For
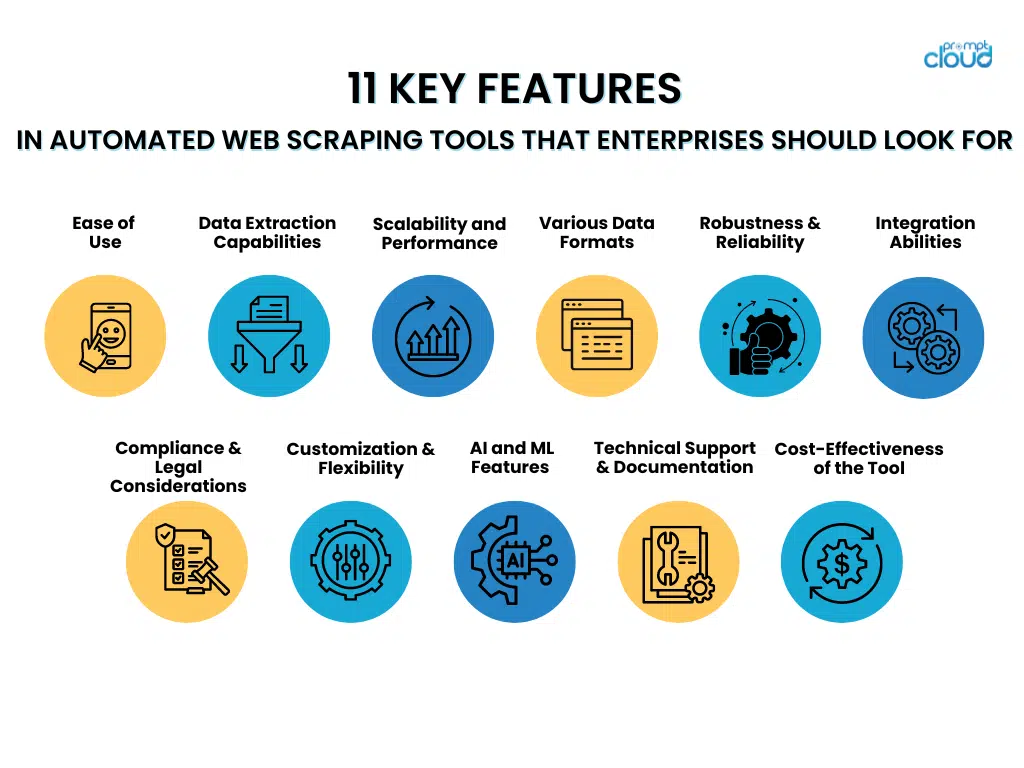
- Ease of Use
When choosing automated web scraping tools, businesses should give preference to those featuring easy-to-use interfaces and effortless setup steps. Tools with intuitive interfaces enable staff to use them efficiently without extensive training, allowing for more focus on data retrieval instead of mastering intricate systems.
On the other hand, uncomplicated setup methods facilitate prompt deployment of these tools, minimizing delays and hastening the journey towards valuable insights.Features that contribute to ease of use include:
- Clear and straightforward navigation menus
- Drag-and-drop functionalities for workflow design
- Pre-built templates for common scraping tasks
- Step-by-step wizards guiding initial configuration
- Comprehensive documentation and tutorials for ease of learning
A user-friendly tool maximizes employee efficiency and helps maintain high levels of productivity.
- Data Extraction Capabilities
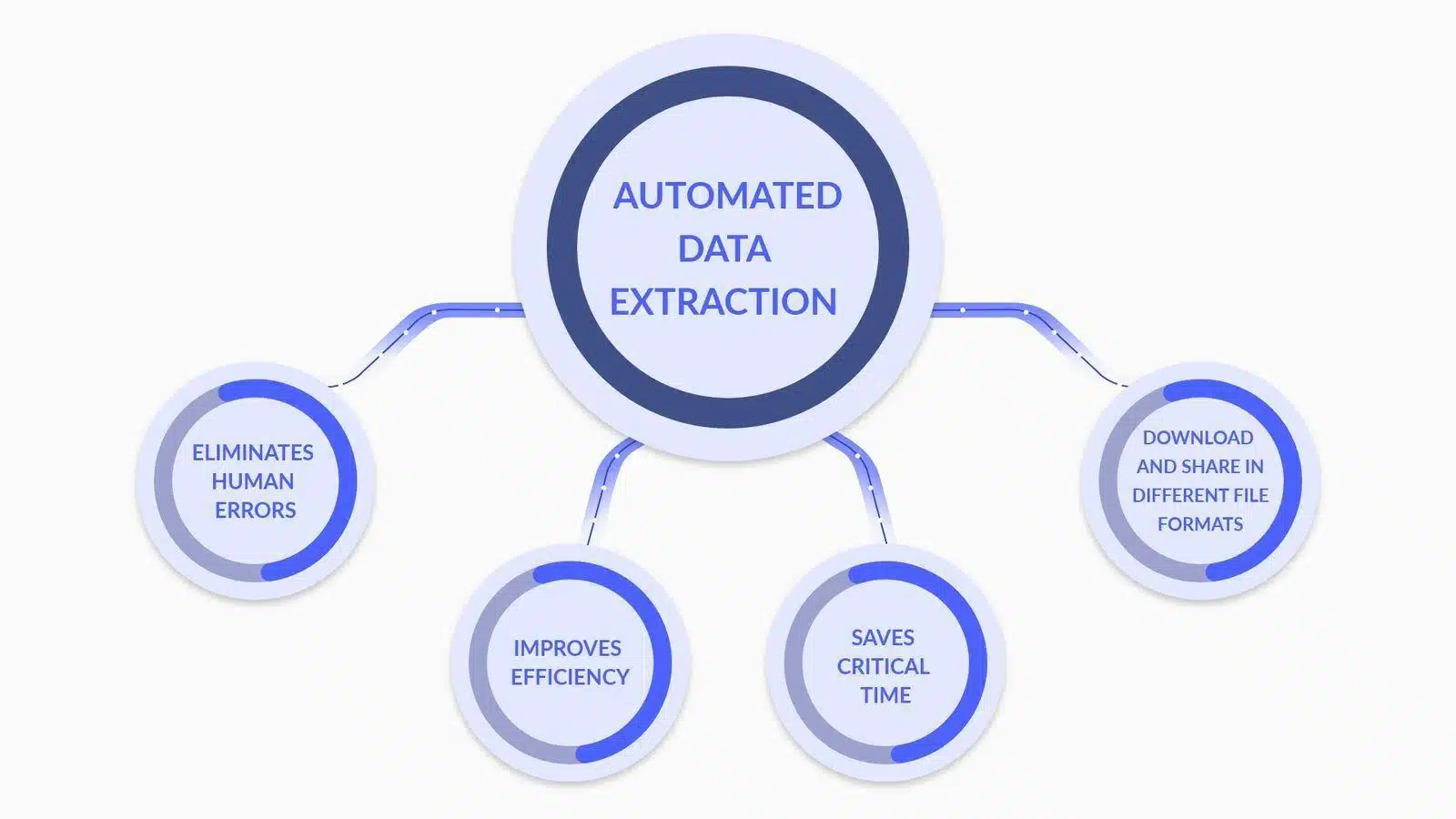
Image Source: What is Data Extraction? Here is What You Need to Know
When evaluating automated web scraping tools, enterprises should prioritize advanced data parsing and transformation features such as:
- Custom Data Parsing: The ability to customize parsers to accurately interpret complex data structures, including nested and dynamic content.
- Data Type Conversion: Tools that automatically convert extracted data into usable formats (e.g., dates, numbers, strings) for more efficient data processing.
- Regular Expression Support: Inclusion of regex capabilities for sophisticated pattern matching, allowing for precise data extraction.
- Conditional Transformation: The ability to apply conditional logic to extracted data, enabling transformation based on specific criteria or data patterns.
- Data Cleansing: Functions that clean and standardize data in the post-extraction phase to ensure data quality and consistency.
- API Integration: Facilities for seamless integration with APIs to further process and analyze the extracted data, enhancing decision-making capabilities.
Each feature contributes to a more robust and accurate data extraction process, pivotal for enterprise-level web scraping endeavors.
- Scalability and Performance
When assessing automated web scraping tools, enterprises should prioritize scalability and performance attributes that support the efficient processing of vast datasets.
An ideal tool can adeptly manage a significant increase in workload without compromising speed or accuracy. Enterprises must look for features such as:
- Multi-threading capabilities allowing concurrent data processing
- Efficient memory management to handle large-scale scraping tasks
- Dynamic allocation of resources based on real-time demands
- Robust infrastructure that can scale horizontally or vertically
- Advanced caching mechanisms to speed up data retrieval
The tool’s ability to maintain performance under load ensures reliable data extraction, even during peak times or when scaling up operations.
- Support for Various Data Formats
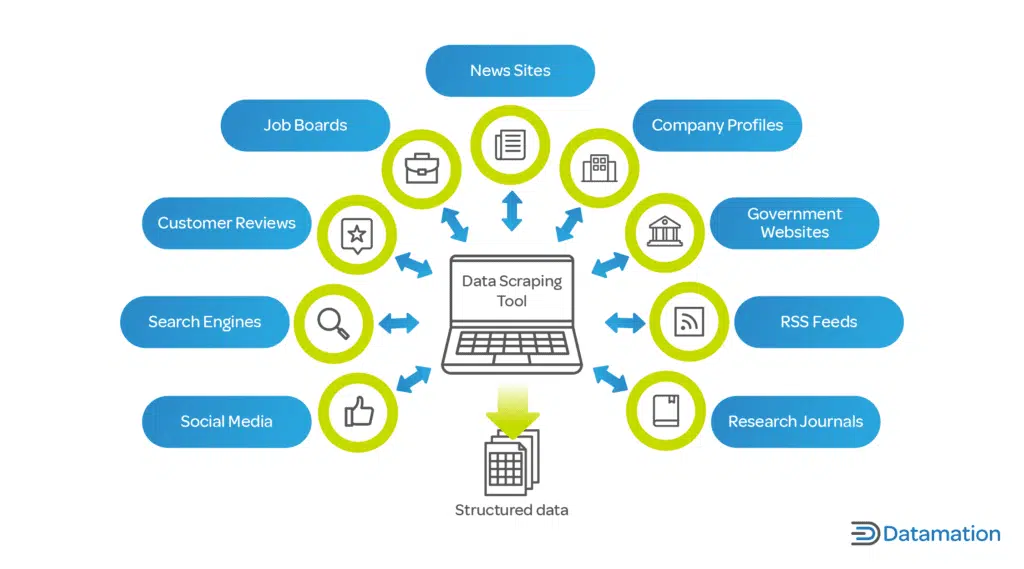
Image Source: What is Data Scraping? Definition & How to Use it
An automated web scraping tool must proficiently handle diverse data formats. Enterprises often work with various data types, and flexibility in data extraction is pivotal:
- JSON: A lightweight data-interchange format that is easy for humans to read and write, and easy for machines to parse and generate.
- CSV: Comma-separated values format is a common, simple file format used for tabular data. Most scraping tools should provide a CSV export option.
- XML: Extensible Markup Language, a more complex format which includes metadata and can be used across a wide range of industries.
The ability to extract and export data in these formats ensures compatibility with different data analysis tools and systems, offering a versatile solution for enterprise requirements.
- Robustness & Reliability
When enterprises choose automated web scraping tools, they must prioritize robustness and reliability. Key features to consider include:
- Comprehensive Error Handling: A superior tool should have the ability to detect and rectify errors automatically. It should log issues and, when possible, retry failed requests without manual intervention.
- Downtime Minimization Strategies: The tool should include failover mechanisms, such as backup servers or alternative data sources, to maintain operations when primary sources fail.
- Continuous Monitoring Systems: Real-time monitoring ensures that any downtime is immediately identified and addressed, minimizing data gaps.
- Predictive Maintenance: Utilizing machine learning to predict potential points of failure can preemptively prevent downtimes, making the system more reliable.
Investing in tools that emphasize these aspects of robustness and reliability can significantly reduce operational risks associated with web scraping.
- Integration Abilities
When assessing automated web scraping tools, enterprises must guarantee their ability to integrate fluidly with current data pipelines. This is essential to maintain data flow continuity and optimize the process. The tool should:
- Offer APIs or connectors compatible with existing databases and analytics platforms.
- Support various data formats for seamless import/export ensuring minimal disruption.
- Provide automation features that can be triggered by events within the data pipeline.
- Facilitate easy scaling without extensive reconfiguration as data needs evolve.
- Compliance and Legal Considerations
When integrating an automated web scraping tool into enterprise operations, it is crucial to ensure that the tool adheres to legal frameworks. Features to consider include:
- Respect for Robots.txt: The tool should automatically acknowledge and comply with the website’s robots.txt file, which outlines scraping permissions.
- Rate Limiting: To avoid a disruptive load on host servers, tools must include adjustable rate limiting to control the frequency of requests.
- Data Privacy Compliance: The tool should be built in alignment with global data protection regulations like GDPR or CCPA, ensuring personal data is handled lawfully.
- Intellectual Property Awareness: The tool should have mechanisms to avoid the infringement of copyrights when scraping copyrighted content.
- User-Agent Transparency: The ability for the scraping tool to accurately and transparently identify itself to target websites, reducing the risk of deceptive practices.
Including these features can help mitigate legal risks and facilitate a responsible scraping strategy that respects both proprietary content and user privacy.
- Customization & Flexibility
To effectively meet their unique data gathering requirements, enterprises must consider an automated web scraping tool’s customization capabilities and flexibility as crucial factors during evaluation. A superior tool should:
- Offer a user-friendly interface for non-technical users to customize data extraction parameters.
- Provide advanced options for developers to write custom scripts or use APIs.
- Allow for easy integration with existing systems and workflows within the enterprise.
- Enable scheduling of scraping activities to run during off-peak hours, reducing the load on servers and avoiding potential website throttling.
- Adapt to different website structures and data types, ensuring a broad range of use cases can be handled.
Customization and flexibility ensure that the tool can evolve with the enterprise’s changing needs, maximizing the value and efficacy of web scraping efforts.
- Advanced AI and Machine Learning Features
When selecting an automated web scraping tool, enterprises must consider the integration of advanced AI and machine learning in improving data accuracy. These features include:
- Contextual Understanding: The application of natural language processing (NLP) enables the tool to discern context, reducing errors in scraped content.
- Pattern Recognition: Machine learning algorithms identify data patterns, facilitating the accurate extraction of information.
- Adaptive Learning: The tool learns from previous scraping tasks to optimize data collection processes for future tasks.
- Anomaly Detection: AI systems can detect and correct outliers or anomalies in the scraped data, ensuring reliability.
- Data Validation: The use of AI to cross-verify scraped data with multiple sources enhances the validity of information.
By harnessing these capabilities, enterprises can substantially diminish inaccuracies in their datasets, leading to more informed decision-making.
- Technical Support and Documentation
It is advisable for businesses to give preference to automated web scraping tools that come with extensive technical assistance and thorough documentation. This is crucial for:
- Minimizing downtime: Quick, professional support ensures any issues are resolved swiftly.
- Ease of use: Well-organized documentation aids in user training and tool mastery.
- Troubleshooting: Accessible guides and resources empower users to troubleshoot common problems independently.
- Updates and upgrades: Consistent support and clear documentation are vital for navigating system updates and new features effectively.
Choosing a tool with robust technical support and clear documentation is essential for seamless operation and efficient problem-solving.
- Evaluating the Cost-Effectiveness of the Tool
Enterprises should take into account both the initial expenses and the possible ROI when assessing automation software for web scraping. Key pricing factors include:
- License fees or subscription costs
- Maintenance and support expenses
- Potential cost savings from automation
- Scalability and adaptability to future needs
A thorough return on investment (ROI) assessment for a tool should take into account its potential to decrease manual work, enhance data precision, and quicken the process of gaining insights. Additionally, businesses ought to evaluate enduring advantages like improved competitiveness resulting from data-based choices. Contrasting these measurements with the tool’s expense will offer a distinct view of its cost-efficiency.
Conclusion
When choosing an automated web scraping tool, businesses should meticulously consider each feature in relation to their specific requirements. Emphasizing aspects such as scalability, data precision, speed, legality, and cost-efficiency is essential. The ideal tool will support company objectives and smoothly integrate with current systems. In the end, an enlightened choice stems from a thorough examination of the tool’s features and a solid comprehension of the business’s future data needs.















