



What Is Web Crawling?
A decade ago, web crawling lived quietly in the background of the internet. A polite robot fetched pages so search engines could index them, and most people never thought about it. Today, web crawling sits at the center of nearly every data driven decision being made online. Pricing engines, AI training pipelines, market intelligence dashboards, fraud detection systems, and the answers your favorite chatbot returns all trace back to one thing: a crawler that visited a page, read it, and brought the information home.
The rules have changed too. In 2026, much of the open web sits behind JavaScript frameworks, anti bot defenses, and authentication walls. Cloudflare blocks unverified AI crawlers by default. Publishers are drafting machine readable access policies. Bot traffic now accounts for more than half of all internet activity, with scrapers alone making up over 10% of global web traffic even after mitigation. The web is still crawlable, but it is no longer freely so.
This guide explains what web crawling is, how a modern web crawler works, the different types you will encounter, where crawling ends and scraping begins, and what it takes to run crawls responsibly at scale. By the end, you will know whether to build your own crawler or buy one as a managed service.
What Is a Web Crawler?
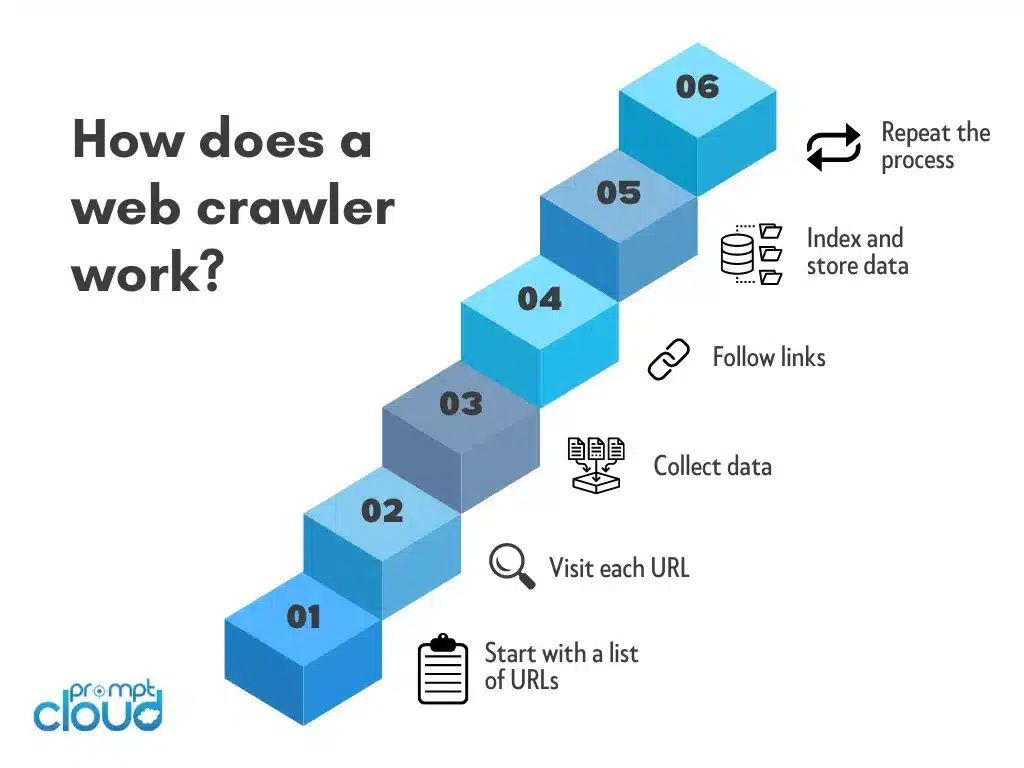
Web crawling, sometimes called spidering, is the process of systematically discovering and downloading pages from the internet. A web crawler is the program that does the work. It starts with a list of seed URLs, fetches each page, parses the HTML, extracts the hyperlinks it finds, and queues those links for the next round. Repeat that loop at scale, and you have mapped a meaningful slice of the public web.
Classic definitions stop there. The 2026 reality is more layered. Modern web crawling is no longer a one shot fetch and parse operation. It includes JavaScript rendering, session management, fingerprint rotation, schema validation, freshness scoring, and compliance logging. A crawler that worked in 2016 would fail on most large websites today because so much content is rendered after the initial page load, gated behind interactions, or protected by behavioral detection systems.
The other big shift is purpose. For most of the web’s history, crawling meant indexing for search. Search engines were the dominant consumers, and the goal was to make pages findable. In 2026, AI training data, real time competitive intelligence, and event driven monitoring are equally important reasons to crawl. The same underlying technique now serves an entirely different set of business outcomes. Web crawling is no longer just plumbing for search. It is operational infrastructure for the data economy.
Spending more time managing crawlers than using the data they collect?
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema.
• No contracts. • No credit card required. • No scraping infrastructure to maintain.
How a Web Crawler Actually Works
Strip away the marketing and a crawler is a simple state machine with a difficult job. It manages a frontier of URLs to visit, a fetcher that retrieves them, a parser that extracts content and new links, and a storage layer that holds everything for downstream use. The complexity comes from doing this politely, reliably, and at speed across millions of pages.
Here are the core stages every modern web crawler moves through:
- Seed and discovery: The crawler begins with a list of starting URLs from a sitemap, RSS feed, or curated list. Every link on a fetched page becomes a candidate for the next cycle.
- Politeness and scheduling: Before any request, the crawler checks robots.txt and applies a delay between requests to the same host, with a separate queue per server.
- Fetching: The crawler issues HTTP requests through rotating proxies. For JavaScript heavy sites, it spins up a headless browser like Playwright or Puppeteer to render the page as a real user would.
- Parsing and extraction: HTML, JSON, and rendered DOM are parsed. Text, structured data, metadata, and outbound links are extracted. AI assisted parsers increasingly recover content when selectors break after a redesign.
- Deduplication and normalization: URLs are canonicalized so the crawler does not fetch the same page twice under different query strings. Content is hashed to detect near duplicates.
- Storage and indexing: Clean records flow into a database, data lake, or message queue, then feed search indexes, machine learning pipelines, or customer facing products.
- Revisit logic: The crawler tracks how often each URL changes and revisits accordingly. News pages might be re-crawled every few minutes, archival pages monthly.
The shift in 2026 is that many of these stages are now event driven rather than scheduled. Instead of running every six hours regardless of whether anything has changed, modern crawlers listen for signals (a webhook, a feed update, a database change) and fetch only what is new.
The Main Types of Web Crawlers
Not every web crawler is built for the same job. Choosing the right type, or stitching together a few of them, has a bigger impact on cost and data quality than most teams realize. Here is a quick reference for the categories you will encounter in 2026.
| Crawler Type | Primary Purpose | Typical Use Case |
|---|---|---|
| General purpose | Index the open web at scale | Search engines like Google, Bing, and emerging AI search platforms |
| Focused | Crawl a narrow topic or vertical | Industry research, niche aggregators, academic projects |
| Incremental | Revisit pages on a schedule to capture updates | News feeds, price monitoring, freshness sensitive datasets |
| Distributed | Split work across many machines or regions | Enterprise data programs handling millions of pages daily |
| Vertical | Crawl one industry deeply | Real estate, travel inventory, job listings, retail catalogs |
| Event driven | Wake only when content changes | Real time pricing, breaking news, inventory shifts in 2026 |
| AI training | Build large corpora for model training | LLM pretraining, fine tuning, retrieval augmented generation |
General purpose crawlers like the ones Google operates remain the gold standard for breadth, but they are not designed to deliver structured business data. For commercial intelligence, focused and vertical crawlers do far more useful work. Event driven crawlers are the fastest growing category, particularly in retail and travel where prices and inventory move by the minute. Teams comparing managed crawling providers often start their research by looking at a Bright Data alternative to understand how different platforms handle scale, compliance, and data delivery.
AI training crawlers are the newest addition to this list. They have very different priorities from search crawlers. They want diverse, high quality text and structured data, often with rich metadata about source, freshness, and licensing. Many publishers now distinguish between search bots, which they welcome, and AI training bots, which they want to license or block. Building a single crawler that can serve both purposes is harder than it sounds.
Need This at Enterprise Scale?
While a DIY crawler works for small use cases, enterprise data programs introduce proxy management, parser maintenance, and compliance overhead that compounds fast.
Web Crawling vs Web Scraping: What Is the Real Difference?
People use the terms interchangeably, and that confusion costs teams real money when they buy the wrong tool. The distinction is straightforward once you separate the verbs from the goals.
Web crawling is about discovery. The job is to find and download pages, often without caring deeply about what is on them. The output of a crawl is a corpus of fetched documents and the graph of links between them. Search engines crawl because they need to know what exists.
Web scraping is about extraction. The job is to pull specific fields out of pages you have already found. The output is a structured dataset: product names, prices, ratings, addresses, job titles, whatever the use case requires. Scrapers crawl because they need the pages, but the crawling is a means to an end.
In practice, every commercial data project does both. You crawl to discover the pages that matter, then you scrape to extract structured records from them. The architecture you choose depends on which side of the workflow is harder. If you are tracking a few hundred URLs that rarely change, scraping is the bottleneck. If you are mapping a marketplace with millions of constantly shifting listings, crawling is the harder problem. Teams evaluating providers often look at a Zyte alternative specifically because they want one platform that handles both layers cleanly without forcing them to stitch together separate tools.
Why Web Crawling Matters More Than Ever
Three forces have pushed web crawling from a back office utility to a strategic capability: the rise of AI, the maturation of compliance frameworks, and the emergence of what industry analysts now call the permission economy.
AI’s appetite for fresh data
Large language models are only as useful as the data they are trained on, and that data goes stale fast. A model trained on a snapshot from last year cannot answer reliable questions about today’s prices or product launches. Retrieval augmented generation has shifted the bottleneck from training to inference time data, and the pipelines feeding those systems are almost entirely powered by web crawlers.
Compliance has finally arrived
For most of its history, web crawling operated in a grey zone. That ambiguity is closing. The EU AI Act, expanded interpretations of the CFAA in the United States, and national data protection laws have made one thing clear: how you crawl matters as much as what you crawl. Identifying your bot, respecting robots.txt, throttling responsibly, and honoring removal requests are no longer optional.
The permission economy
Cloudflare now blocks unverified AI crawlers by default for sites that opt in. Marketplaces like TollBit let publishers charge bots for access. Major news organizations have signed licensing deals that explicitly cover crawler access. The open web is not closing, but it is becoming a permission based environment where structured agreements replace silent assumptions. Teams building serious data programs increasingly compare an Oxylabs alternative specifically on how their compliance posture and transparency stack up.
The Hidden Costs of Web Crawling at Scale
On paper, a web crawler looks cheap. Write a Python script, host it on a small server, let it run. Anyone who has operated a crawl at scale knows that the real costs show up later, and they grow faster than most leaders expect.
Infrastructure is the first surprise. Rotating proxies, residential IPs, headless browser farms, and anti bot evasion services each carry monthly bills that can easily exceed the salaries of the engineers running them. A single misconfigured retry loop can double a bandwidth invoice overnight, and storage adds up fast when you crawl a million product pages a day.
Maintenance is the second surprise, and it is the one that quietly kills internal projects. Websites change, selectors break, JavaScript frameworks get upgraded, and new anti bot rules ship without warning. Someone has to monitor crawl health, patch parsers, and redeploy. The first few sites are manageable. The hundredth site is a full time role.
Data quality is the third and most underestimated cost. A crawler that silently misses 5% of records will not throw an error, but it will distort every downstream analysis. Currency symbols flip, dates lose timezone context, product variants get merged into one row. Catching these issues requires automated validation, schema monitoring, and human review. None of this appears in a quick build estimate.
Where Web Crawling Creates Real Business Value
Web crawling is almost invisible when it works, which makes it easy to underestimate. The applications below are running in production today, and the data they produce is shaping pricing, product, and strategy decisions in real time.
E commerce and retail intelligence: Retailers track competitor catalogs, prices, promotions, and reviews across thousands of storefronts. Some teams refresh pricing every fifteen minutes during peak shopping events.
Travel and hospitality: Airlines, hotels, and aggregators crawl each other constantly. Fares, room availability, and loyalty promotions need to be captured the moment they appear. An hour of delay can mean millions in mispriced inventory.
Financial services and alternative data: Hedge funds crawl job postings, product reviews, regulatory filings, and social media to build leading indicators that beat quarterly earnings. This entire category of investing only exists because crawling does.
AI and machine learning: Training data, fine tuning corpora, retrieval augmented generation indexes, and evaluation benchmarks all depend on crawled content. The crawl now determines the model.
Risk, fraud, and brand protection: Companies crawl marketplaces and app stores to find counterfeit listings, phishing pages, and trademark abuse. The faster the crawl, the smaller the damage.
Real estate and property tech: Listings, rental rates, and neighborhood data feed valuation models and investor dashboards. A crawler that misses a regional MLS can wipe out an entire model’s accuracy.
Best Practices for Responsible Web Crawling
Running a web crawler well in 2026 is less about clever code and more about disciplined operations. The teams that get sustainable results follow a handful of consistent practices.
Respect robots.txt. The official robots.txt specification, formalized as IETF RFC 9309, is the closest thing the web has to a universal agreement on crawler behavior. Following it is not legally required everywhere, but ignoring it almost always becomes a problem eventually. Identify your bot clearly in the user agent string. Provide a contact URL or email so site owners can reach you if there is an issue. Throttle requests so that no single origin sees you as a denial of service event.
Build in observability. You cannot fix what you do not measure. Track per site success rates, latency, parsing accuracy, and freshness. Alert on anomalies before they become incidents. Keep audit logs that can answer the question “what did our crawler do on this site, on this day” months after the fact. That kind of evidence is increasingly important for compliance reviews and customer trust conversations.
Treat data quality as a first class concern. Schema validation, null detection, volume monitoring, and human review are not optional extras. They are the difference between a dataset you can trust and one that quietly poisons your decisions. Teams evaluating a managed service often compare an Apify alternative on exactly these quality and observability dimensions, not just on price per request.
Build vs Buy: Choosing the Right Path
There is no universal answer to the build versus buy question for web crawling. The right choice depends on the volume you need, the volatility of your target sites, and the maturity of your engineering team.
Build in house if you are crawling a small, stable set of sources where the data and methodology are core intellectual property. A search startup that depends on a proprietary index will want full control of the stack. A research team running a quarterly crawl of a hundred URLs can do it with a junior engineer and a weekend.
Buy as a managed service if your scale is high, your target sites are volatile, your time to value matters, or your team would rather spend its energy on downstream products than on proxy management. Managed providers absorb the operational overhead: anti bot evasion, parser maintenance, infrastructure scaling, and compliance reporting. You pay for output, not for the plumbing.
Most mature organizations run a hybrid model. Critical or sensitive crawls stay in house. High volume, commodity crawls are outsourced. The split is about focus, not capability.
How PromptCloud Helps Teams Crawl the Modern Web
PromptCloud is a fully managed web crawling and data extraction service that has been delivering enterprise grade datasets since 2010. The platform handles the entire pipeline: discovery, fetching at scale across rotating proxy networks, JavaScript rendering through headless browsers, schema validation, deduplication, and delivery in the format your downstream systems already speak (JSON, CSV, XML, or direct push to S3, BigQuery, and similar destinations).
Three things matter most to teams that choose a managed service over an in house build. The first is reliability. PromptCloud’s infrastructure auto recovers from site changes, anti bot rule updates, and selector drift, with human in the loop quality assurance catching the failures that automation misses. The second is compliance. Every crawl is logged, every site is reviewed for terms of service alignment, and the platform supports the user agent identification and removal request workflows that regulators now expect.
The third is breadth. PromptCloud crawls e commerce catalogs, travel inventory, real estate listings, job boards, news, reviews, and AI training corpora across millions of pages daily for customers in retail, finance, hospitality, and AI research. Teams that start with a single source typically expand to ten or twenty within a year, because once the operational burden of crawling is gone, new use cases stop feeling expensive.
The Future Belongs to Responsible Crawlers
Web crawling has grown up. What used to be a clever script tucked behind a dashboard is now a regulated, observable, mission critical layer of the internet. The crawlers that thrive in the next decade will not be the ones that fetch the most pages. They will be the ones that identify themselves clearly, honor the consent signals publishers expose, and deliver clean and verifiable data quarter after quarter.
If you are building a data program from scratch, or modernizing one that has been running on autopilot, the strategic question is no longer can we crawl this. It is whether you can crawl it in a way that will still be working, still be trusted, and still be compliant three years from now.
Spending more time managing crawlers than using the data they collect?
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema.
• No contracts. • No credit card required. • No scraping infrastructure to maintain.
Frequently Asked Questions
1. What is web crawling in simple terms?
Web crawling is the automated process of discovering and downloading pages from the internet. A program called a web crawler (or spider) visits a starting URL, reads the page, follows the links it finds, and repeats the loop to map a section of the web. Search engines, AI companies, and data providers all use crawlers to keep their indexes fresh.
2. How does a web crawler work step by step?
A web crawler starts with a list of seed URLs, fetches each page through an HTTP request, parses the HTML, extracts the links and content, deduplicates the results, stores them in a database, and queues newly found URLs for the next round. Professional crawlers also check robots.txt, throttle requests, render JavaScript when needed, and revisit pages on a schedule that matches how often the content changes.
3. What is the difference between web crawling and web scraping?
Web crawling is about discovery: finding and downloading pages. Web scraping is about extraction: pulling specific fields like prices, titles, or reviews out of pages you have already found. Most commercial data projects do both, with crawling running first and scraping running on top of the crawled pages.
4. Is web crawling legal?
Crawling publicly accessible pages is generally legal in most jurisdictions, but the rules vary by country and by what you do with the data. Following robots.txt, respecting terms of service, avoiding the collection of personal data without a lawful basis, and not bypassing technical access controls keep most crawls on safe ground. Consult counsel for any crawl that touches regulated industries or personal data.
5. What are the different types of web crawlers?
The main types are general purpose crawlers (used by search engines), focused crawlers (one topic or niche), incremental crawlers (revisit on a schedule), distributed crawlers (split work across machines), vertical crawlers (one industry deeply), event driven crawlers (trigger on change), and AI training crawlers (build corpora for model training). Most production data programs combine two or three of these.
6. How do search engines like Google use web crawlers?
Google operates a crawler called Googlebot that continuously discovers new pages, updates its index when existing pages change, and assesses content for ranking signals. The crawler follows links from already indexed pages, reads sitemaps, and revisits popular or frequently updated pages more often. Without web crawling, search engines would have nothing to rank.
7. Can a website block a web crawler?
Yes. Websites can block crawlers through robots.txt directives, IP blocking, rate limiting, CAPTCHAs, behavioral fingerprinting, and managed services like Cloudflare’s bot mitigation. Responsible crawlers honor robots.txt and stop or slow down when sites signal that they should. Hostile blocking exists too, but ethical crawling treats the publisher’s signals as the starting point.
8. What is robots.txt and do web crawlers have to follow it?
Robots.txt is a plain text file at the root of a website that tells crawlers which paths they may or may not access. It is formalized in IETF RFC 9309 as a voluntary standard. Major search engines and reputable data providers follow it as a hard rule, both because it is the right thing to do and because ignoring it tends to trigger faster, harsher blocks downstream.
9. How much does it cost to build a web crawler?
A simple in house crawler for a handful of stable sites can be built in a week and run on a small server for under a hundred dollars a month. A production grade crawler covering hundreds of sites with proxy rotation, headless browsers, monitoring, and human quality assurance typically costs between five and twenty thousand dollars a month all in, plus the engineering salaries to maintain it. Managed services often come in below that figure because the underlying infrastructure is shared across customers.
10. What tools and frameworks do professional web crawlers use?
Common building blocks include Scrapy and Crawlee for orchestration, Playwright and Puppeteer for JavaScript rendering, residential and datacenter proxy networks for IP rotation, and anti bot bypass services for protected sites. Managed crawling platforms package these layers together with scheduling, monitoring, and data delivery, so teams do not have to assemble and maintain the stack themselves.















