



With millions of products, the associated content, such as pricing information, product descriptions, images and reviews, can easily go into hundreds of millions for some of the largest eCommerce players. Though most sites predominantly use their own data, competitor and product data are obtained by crawling sites of the product sellers or suppliers. Web crawling application in eCommerce industry has grown by leaps and bounds, owing to the huge SKUs and growing data demand for internal audits and business insights.
Use Cases of Web Crawling Application in eCommerce
From eCommerce sites crawling their competitors’ or suppliers’ prices, product descriptions and images to site-specific web crawling – we try to explore how online shopping sites exploit data crawling to their advantage.
1. Real-Time Monitoring of Competitors’ Prices
Selling products at competitive prices all the time is a really crucial aspect of e-commerce. Some of these sites actually crawl web for their competitors’ sites to ensure that they’re either able to match the prices being offered over there or offer better prices. It has indeed been proved that pricing optimization techniques can improve gross profit margins by around 10%. Web crawling applications in eCommerce is felt by travel companies, to extract prices from airlines’ websites in (near) real time for a long time.
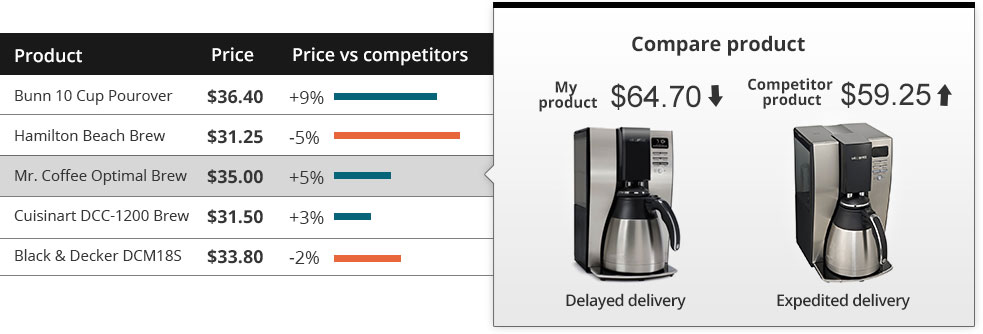
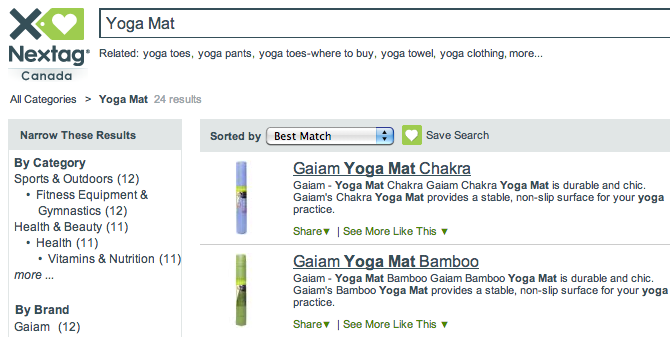
2. Price Comparison Shopping Engines
For e-commerce companies, customer loyalty is almost non existent. Today, customers are willing to switch retailers even if the product that they’re looking for is available just 5% cheaper elsewhere. Price comparison sites such as Nextag, PriceGrabber and ShopZilla crawl data from millions of product pages across major e-commerce sites. These comparison shopping engines extract product feeds, including all associated details regarding the product (title, description, ratings, images etc.) From multiple sites and juxtapose the products for enabling easy comparison.
3. Product Performance Intelligence
In order to stay on top of their direct competitors, nowadays e-commerce sites closely monitor their counterparts. For example, say Amazon would want to know how their products are performing against BestBuy or Walmart, and whether their product coverage is complete. Towards this end, they would want to crawl web product catalogs from these two sites to find the gaps in their catalog. They’d also want to stay updated about whether they’re running any promotions on any of the products or categories.
Web crawling application in eCommerce industry is established by gaining actionable insights that can be implemented in their own pricing decisions. Apart from promotions, sites are also interested in finding out details such as shipping times, number of sellers, availability, similar products (recommendations) etc. for identical products.
For requirements where the number of products involved is rather large; we also perform incremental crawls, wherein sources are crawled relative to how frequently they’re updated. For instance, through our Machine Learning algorithm, we can determine if a product gets a review daily, weekly or monthly (on an average) and the crawler prioritizes the fetching process accordingly.
4. Order Fulfilment Integration
Lately, some eCommerce sites have started providing package tracking information inside the customer area of their websites, along with the order details (as opposed to providing a third party tracking code). Though some courier companies might have an API for obtaining latest information, for others – their sites are crawled for product transit status frequently, and that data is integrated within the user interface itself or e-mailed to the customer.
Any sentiment analysis done at scale is a result of focused web crawls running in the background. Companies want to find out how their products are performing in the market, and whether their promotional efforts are having a direct impact on their sales. Traditionally, doing this would have incurred significant costs, as it would involve asking customers face-to-face through a survey or by conducting a focused group discussion.
With the advent of e-commerce, companies are now able to retrieve similar, unsolicited feedback from their customers in the form of reviews and ratings. It really separates the wheat from the chaff for vendors and companies looking for first hand opinions of customers on their products – information that they can incorporate in their product development and R&D almost instantaneously.
Through web crawlers, relevant data is delivered to companies by scraping the customer reviews and ratings on a site. Apart from this, many forums are also treasure troves of sentiment data that can be extracted. Sometimes, prominent sellers on marketplace sites are interested in extracting reviews and ratings of their own products listed on those sites. One of our clients was a furniture company having an online sales channel on sites like Walmart.com and Amazon.com. The client wanted to receive reviews posted on their products.
5. Fetching Product Information From Suppliers
Marketplace e-commerce websites have thousands of suppliers. Necessary information such as product descriptions, pricing, applying a markup%, images, and specifications needs to be pulled from the suppliers’ websites. The supplier might have feeds or an API, but mostly it is not the case. This is a gap that web scraping fills – by crawling the suppliers’ websites for specific product URLs or SKUs and extracting all the associated fields of a product listing. Doing this manually would cost several man-hours and isn’t really scalable.
A lot of web apps are changing the way images are searched. In order to find a similar product, the user just needs to upload an image to a visual product search engine like this one and it’ll do the rest. At the backend of these sites, there is a database of high-resolution images of products listed on all major e-commerce sites that are used for matching the image uploaded by a user.
Web crawling application in eCommerce continue to evolve, and the application of web crawling and data extraction to e-commerce is also becoming more widespread. Uses that hadn’t been thought of before are emerging constantly and it needs to be seen how much interdependent the two disciplines become over time.















