



**TL;DR**
Competitive intelligence demands multi-agent scraping. These systems draw on collaborative agent frameworks and large language models to handle layout changes, site segmentation and high-volume collection automatically.
What you’ll learn:
- Why traditional individual crawlers struggle with modern intelligence use cases
- How multi-agent scraping architectures work and scale
- What roles and coordination patterns matter for competitive workflows
- Practical challenges around orchestration, data overlap and fault-tolerance
Takeaways:
- More sources mean more value but also more complexity
- Multi-agent systems break bottlenecks and improve resilience
- Governance, orchestration and design matter more than raw speed
Imagine you’re tracking competitors’ product changes, pricing updates, and market sentiment across dozens of websites and you’re doing it manually or with a single crawler. Every time a layout shifts, you update code. Every site requires its own logic. Coverage is limited and fragile.
Now imagine a system of three bots working together: one bot maps site structures, another crawls data at scale, a third monitors changes and triggers retries. They talk to each other, share state, handle failures, and serve your intelligence pipeline constantly.
That’s the promise of multi-agent scraping. It moves competitive intelligence off the ladder of brittle scripts and into a resilient, orchestration-driven network. Large language models and agent frameworks serve as the brain, turning distributed bots into coordinated teams. In this article we’ll explore:
- Why one bot is rarely enough for serious data coverage
- How to design a multi-agent scraping architecture for scale and resilience
- The roles each bot plays and how they coordinate
- The practical tradeoffs and what to watch out for
- How this fits into competitive intelligence workflows and the future of scraping as orchestration
Let’s dive into how to build smarter intelligence by breaking the “single-bot” mindset.
Why One Bot Doesn’t Cut It for Competitive Scraping
Competitive intelligence depends on coverage. A single crawler can handle one website well, maybe two if they share a structure. But when you’re tracking competitors, products, and markets, the scale breaks fast.
Most companies that rely on solo scraping pipelines run into the same problems: incomplete data, blind spots, and fragile uptime.
The Limits of the Lone Crawler
1. Structural rigidity
Each bot is built for a fixed layout. The moment a competitor redesigns their product pages, half your fields vanish silently. You can patch it, but those hours of downtime mean lost data.
2. Bottlenecks during bandwidth
A single crawler can only handle limited requests per second. To cover multiple geographies or categories, you’d need thousands of concurrent threads and one crawler simply can’t scale that far.
3. Poor error isolation
When one process handles all logic, a minor selector mismatch or timeout cascades into full failure. There’s no redundancy or task handoff.
4. No specialization
Competitive intelligence data isn’t homogeneous. Price tracking, sentiment monitoring, and product updates all require different crawling logic. A single bot trying to handle all of them ends up doing none well.
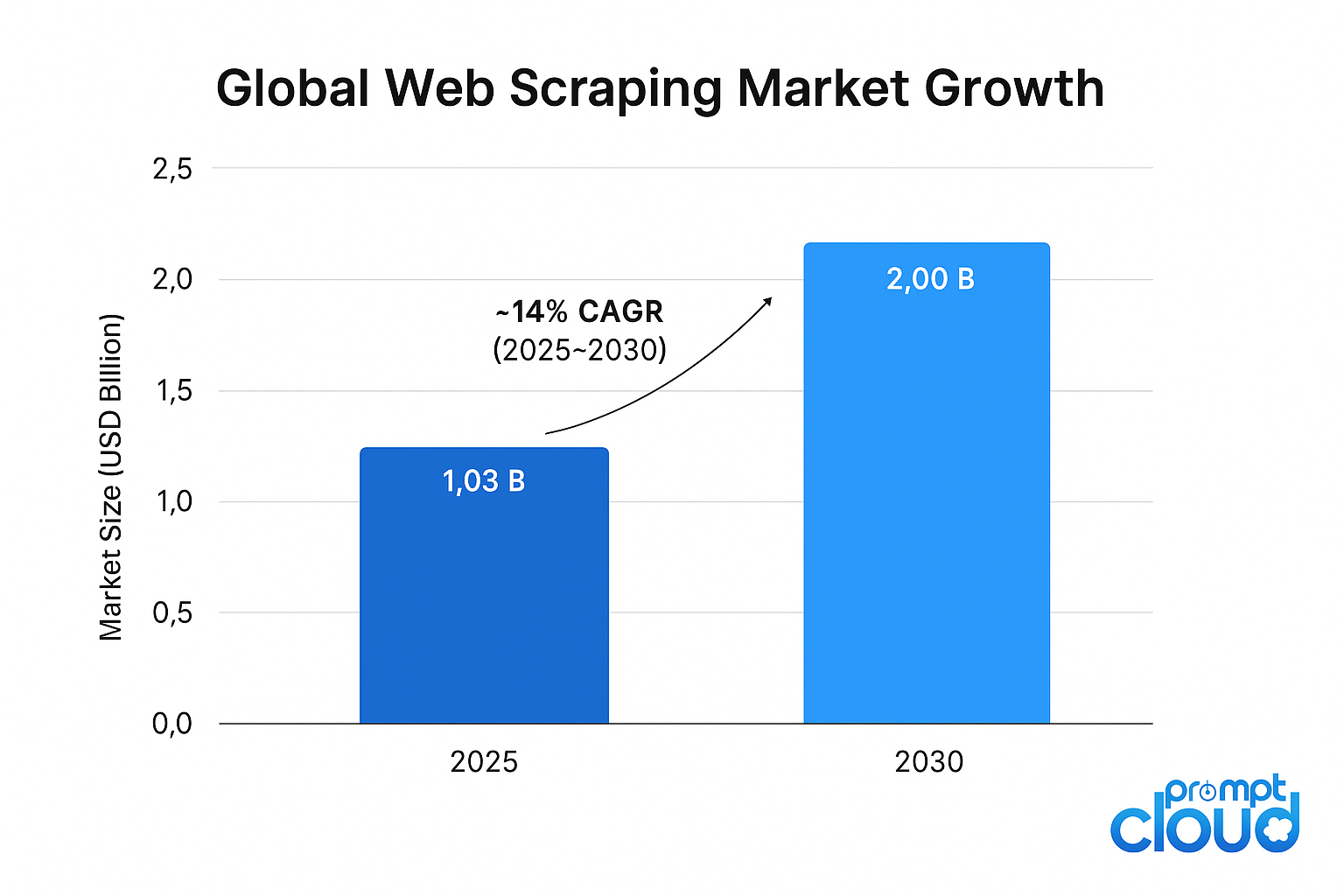
Source: Mordor Intelligence – Web Scraping Market Report
Figure 1: Global web scraping market projected to grow from USD 1.03 billion in 2025 to USD 2.0 billion by 2030 (~14 % CAGR).
Want to see how multi-agent scraping can strengthen your competitive intelligence stack?
Want reliable, structured Temu data without worrying about scraper breakage or noisy signals? Talk to our team and see how PromptCloud delivers production-ready ecommerce intelligence at scale.
The Real Competitive Problem
Competitive data changes faster than websites do. Prices shift hourly. Inventory fluctuates. Product messaging evolves. The “single crawler” mindset can’t keep up with that tempo.
What multi-agent systems offer is division of labor. One agent watches structure, another extracts, a third monitors freshness, a fourth validates schema integrity. Together they operate like a newsroom of data gatherers each with a clear beat but working toward a shared publication deadline. Enterprises that adopt multi-agent architectures report shorter recovery time after layout changes, more consistent dataset completeness, and better control over rate limits. It’s the same philosophy that drives scale in other domains. Cloud systems use microservices. AI uses distributed models. Scraping is evolving the same way modular, parallel, and fault-tolerant.
How Does Multi-Agent Scraping Work?
Multi-agent scraping systems borrow a simple idea from teamwork: specialization. Each agent focuses on one function: discovery, extraction, validation, or delivery and all agents share state through a coordination layer.
The Core Roles in a Multi-Agent System
- Discovery Agent
Maps domains, identifies URLs, and prioritizes targets. It acts as the scout. - Extraction Agent
Handles parsing, rendering, and data capture. Optimized for structure, not logic. - Validation Agent
Checks output against schema expectations and catches field drift early. - Orchestration Agent
Coordinates scheduling, load balancing, retries, and communication between agents. - Analytics Agent
Aggregates cleaned data and routes it into storage, dashboards, or APIs.
Each agent has a narrow focus but collectively they form a resilient pipeline.
How do Multi-Agent Scraping Coordinates in Real Time?
| Stage | Agent Responsible | Primary Function | Output Passed To |
| Target Discovery | Discovery Agent | Map URLs, categories, and domains | Extraction Agent |
| Data Extraction | Extraction Agent | Collect structured and unstructured content | Validation Agent |
| Schema & Quality Check | Validation Agent | Detect drift, nulls, or missing fields | Orchestration Agent |
| Load & Retry Management | Orchestration Agent | Reassign failed jobs, throttle requests | Extraction or Validation Agent |
| Aggregation & Delivery | Analytics Agent | Consolidate clean data for intelligence use | Business Systems / API layer |
How Agents Communicate
Agents coordinate through shared state; typically a message queue, Redis cache, or vector database that stores task metadata and partial results. Each agent writes updates like “Job #123 complete” or “Schema drift detected” so the orchestration layer can redistribute work or trigger validation.
That communication loop also supports reasoning. When powered by multi-agent LLM frameworks, each bot can interpret messages semantically. The extraction agent can ask, “Did the schema change for this category?” and the validation agent can respond with context, not just status codes. This dynamic exchange is what turns scraping into collaboration rather than parallel chaos.
For example, in scalable retrieval-augmented generation, multiple agents retrieve, verify, and rank results for AI systems. Multi-agent scraping applies that same logic to real-time data gathering.
The Orchestration Layer – Keeping Agents in Sync
If multi-agent scraping is a team, orchestration is the manager. It decides what happens next, who takes over, and how to balance priorities when conditions change. Without orchestration, multiple agents quickly become multiple problems.
What the Orchestration Layer Does
The orchestration layer is the system’s control room. It tracks job states, manages resource allocation, and enforces communication between agents. Every scrape task runs as a discrete unit with checkpoints and status logs. When a task fails, the orchestrator reassigns it. When a site slows down, it adjusts rate limits automatically. When schema drift appears, it triggers validation or fallback logic.
At enterprise scale, this is what separates chaos from continuity.
Table: Orchestration Responsibilities and Signals
| Responsibility | Example Signal | Outcome Triggered |
| Job Scheduling | “Feed A ready for extraction” | Assigns Extraction Agent |
| Load Balancing | “Region servers 80% capacity” | Shift new tasks to alternate nodes |
| Schema Drift Detection | “Missing field: product_price” | Activate Validation Agent |
| Failure Recovery | “HTTP 500 on batch #45” | Retry job or switch proxy pool |
| State Tracking | “All agents idle, new site discovered” | Dispatch Discovery Agent |
Why Auto Orchestration Matters
Manual coordination doesn’t scale. Each scraping job behaves differently, and conditions shift hourly — from site redesigns to proxy slowdowns to data type mismatches. Auto orchestration lets the system adapt instantly without waiting for human input.
It also enables parallel autonomy, where multiple scrapers operate independently but share insights through the orchestrator. One agent may learn that a site has started rendering JavaScript differently, prompting others to switch to a browser-based approach.
This isn’t theoretical. It’s the same principle used in microservice orchestration for AI pipelines, like the frameworks described in scraping real-time stock market data, where distributed processes continuously coordinate live inputs.
How Does Multi-Agent Scraping Boost Competitive Intelligence?
Competitive intelligence depends on three things such as speed, coverage, and accuracy. Multi-agent scraping delivers all three by distributing effort and cross-verifying results. Instead of running a single monolithic crawler, you operate a synchronized team that understands context, shares progress, and ensures no signal is missed.
Why Competitive Teams Use Multi-Agent Systems
- Parallel Coverage
Each agent can specialize by domain, geography, or data type. One focuses on product listings, another tracks pricing updates, a third monitors social reviews or blog mentions. Together, they cover what a single crawler never could within a reasonable time window. - Real-Time Competitor Tracking
Multi-agent setups allow rolling, near-continuous data collection. While one agent scrapes product details, another monitors promotions, and a validation agent ensures nothing breaks during peak hours. This architecture keeps intelligence fresh and ready for market-facing dashboards. - Error-Resistant Workflows
The beauty of multiple agents is resilience. If a layout update breaks one agent, the orchestrator reroutes tasks or assigns a different extraction method until recovery. No waiting, no downtime, no data loss. - Cross-Source Verification
Agents can double-check one another’s results across overlapping sources. If two retailers show conflicting prices for the same SKU, the validation layer highlights the inconsistency — providing more reliable competitor insights downstream. - Scalable Segmentation
As markets grow, so does the number of monitored competitors. Multi-agent frameworks scale horizontally. You simply add more agents and register them with the orchestrator; the logic and quality controls remain the same.
Multi-Agent Advantages for Competitive Intelligence
| Objective | Single Crawler Outcome | Multi-Agent Outcome |
| Market Coverage | Limited to a few domains | Dozens of domains in parallel |
| Error Recovery | Manual patching | Automated agent reassignment |
| Data Freshness | Daily or weekly updates | Continuous real-time refresh |
| Insight Quality | Unverified, incomplete | Cross-source validated |
| Operational Load | High maintenance | Distributed and balanced |
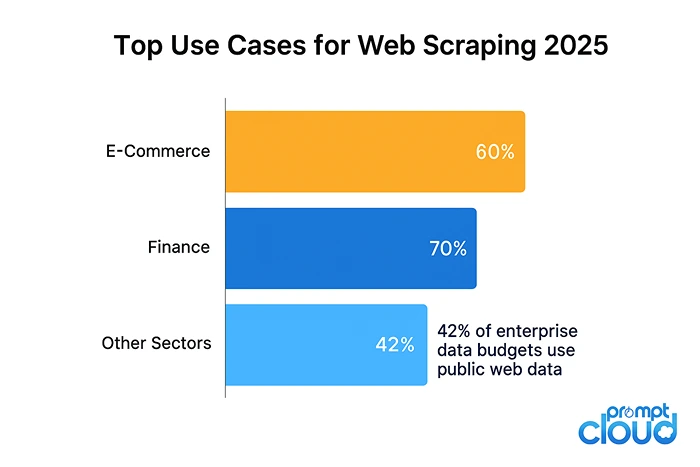
Source: ScrapeOps – Web Scraping Market Report 2025
Figure 2: E-commerce (60 %) and finance (70 %) dominate enterprise web scraping usage, driving adoption of scalable multi-agent systems.
Where It Fits in the Competitive Stack
Once the scraping agents collect and validate the data, it flows into your analytics or market intelligence layer. Retail teams use it for pricing parity tracking. Financial analysts use it for trend correlation and stock sentiment. Real-estate researchers rely on it to monitor listing velocity; similar to the pipeline described in weekly housing data for the US real estate market.
By automating discovery, extraction, and verification, multi-agent scraping becomes the foundation of an always-on competitive edge.
Challenges and Design Considerations for Multi-Agent Scraping Systems
Like any distributed system, multi-agent scraping comes with tradeoffs. You gain scale, but you also add coordination overhead, debugging complexity, and governance risks. Knowing these challenges early helps you design smarter and avoid expensive rebuilds later.
1. Agent Coordination Overhead
More agents mean more messages, task states, and dependencies. If the orchestration layer lacks strong observability, minor sync delays can snowball into duplicate jobs or missing data.The solution is to design for asynchronous coordination agents to communicate through queues, not direct calls, so each can operate independently but still report state updates in real time.
2. Cost of Infrastructure
Each agent consumes compute, bandwidth, and storage. As agent count grows, so does operational cost. Smart scheduling, shared cache layers, and dynamic scaling policies keep the footprint efficient.
3. Data Deduplication and Conflict Resolution
When multiple agents crawl overlapping sources, you’ll inevitably get duplicates. A deduplication layer powered by content hashing or semantic similarity scoring ensures that only unique records are published downstream.
4. Observability and Error Tracing
In large agent networks, finding which scraper failed or which schema drifted can be tricky.
Centralized observability (with trace IDs and structured logs) gives every task a trail from assignment to output. Without it, debugging distributed scrapers becomes guesswork.
5. Governance and Security
Agents share credentials, sessions, and access tokens. If not managed securely, these can leak or collide.
Enterprise systems enforce scoped authentication, audit logs, and key rotation. A breakdown here can jeopardize not only compliance but also client trust a risk addressed deeply in data security in web scraping.
Tradeoffs in Multi-Agent Scraping Design
| Aspect | Benefit | Challenge | Mitigation Strategy |
| Scalability | Parallel execution and fast coverage | High orchestration cost | Use async queues and task schedulers |
| Reliability | Redundant agents prevent downtime | Data overlap and duplicates | Deduplicate using content hashes |
| Flexibility | Agents can specialize per source | Version drift between agents | Centralized schema registry |
| Efficiency | Optimized per-agent load | Increased compute cost | Autoscale and prioritize high-value sites |
| Compliance | Scoped credentials per agent | Security management complexity | Enforce key rotation and token isolation |
The Strategic Perspective
The complexity of multi-agent scraping is worth it when your intelligence pipeline depends on reliability. A well-designed orchestration layer turns those challenges into strengths for scaling collection, distributing logic, and detecting breaks before they impact insights.
A recent MIT Technology Review article notes that multi-agent AI architectures are becoming the new foundation for real-time data pipelines, where independent bots collaborate through shared reasoning layers. The same trend applies to web data systems: independence with coordination.
The Future of Multi-Agent Scraping: From Collaboration to Autonomy
The next evolution of web scraping won’t just be more bots; it will be smarter collaboration. Today’s multi-agent systems coordinate tasks. Tomorrow’s will reason together.
We’re already seeing early signs of autonomous scraping ecosystems where agents negotiate, self-assign, and optimize jobs without orchestration scripts. One agent might specialize in detecting site updates, another in adapting extraction logic, and a third in validating results all communicating through a shared reasoning model.
The Path Forward
- Agent Reasoning Networks
Large language models will move from prompt responders to coordination layers, managing task dependencies and resolving conflicts on the fly. The orchestrator becomes less of a traffic cop and more of a coach guiding strategy, not micromanaging every request. - Context-Aware Collaboration
Agents will soon share memory across pipelines. A schema drift detected in one vertical (say, electronics retail) can trigger preventive adjustments across similar categories automatically. - Self-Healing Pipelines
Instead of alerting engineers, future agents will repair selectors, rerun failed scrapes, and confirm data integrity autonomously. This kind of adaptive behavior is already visible in next-generation frameworks where LLMs fine-tune scraping logic dynamically based on historical outcomes. - Ethical and Policy-Aware Agents
As data governance tightens, agents will need built-in compliance. Expect systems that read and respect robots rules, privacy boundaries, and site terms before scraping — compliance as cognition, not configuration.
Why This Shift Matters
When scraping moves from manual orchestration to autonomous coordination, data pipelines become self-sustaining ecosystems. The human role doesn’t disappear, it evolves. Teams focus on designing objectives, validating insights, and improving context libraries instead of debugging crawl scripts.
It’s the same transition that machine learning went through with AutoML — humans set intent, machines handle iteration. Web scraping is entering that phase now.
In a few years, asking “Which crawler broke?” may sound as outdated as asking “Which page didn’t load?” Automation will answer before you even ask.
The rise of multi-agent scraping signals a shift in how businesses treat web data not as a static feed, but as a living system that reacts, learns, and scales with market activity. As competition grows more digital and product cycles get shorter, intelligence pipelines must match that pace. Multi-agent systems make that possible. They don’t just collect information; they orchestrate insight. For teams managing high-frequency competitive research, this approach turns data collection into a continuous conversation between agents, each one adding context, precision, and speed to your strategic edge.
Want to see how multi-agent scraping can strengthen your competitive intelligence stack?
Want reliable, structured Temu data without worrying about scraper breakage or noisy signals? Talk to our team and see how PromptCloud delivers production-ready ecommerce intelligence at scale.
FAQs
1. What is multi-agent scraping?
Multi-agent scraping is a distributed approach where several specialized bots work together to collect, validate, and monitor data from multiple web sources. Instead of one crawler handling every task, each agent has a defined role — discovery, extraction, validation, or delivery — making the system faster and more reliable.
2. How is it different from traditional web scraping?
Traditional scraping relies on one monolithic crawler that performs every step sequentially. Multi-agent scraping divides responsibilities across multiple agents that coordinate through an orchestration layer, allowing real-time scaling, error recovery, and better performance under load.
3. What role do LLMs play in multi-agent scraping?
Large Language Models (LLMs) enhance communication between agents. They interpret context, detect schema drift, and generate adaptive instructions when sites change. This allows the scraping network to reason about structure instead of relying on rigid scripts.
4. How does multi-agent scraping improve competitive intelligence?
It enables continuous coverage of competitor websites, product catalogs, pricing, and sentiment data. With parallel crawlers and validation agents, organizations can refresh datasets faster and detect changes in near real time — ensuring market insights are always up to date.
5. Can multi-agent scraping reduce scraping downtime?
Yes. If one agent encounters an error or timeout, the orchestrator reroutes tasks to another agent or reassigns extraction logic automatically. This redundancy minimizes downtime and prevents data loss.
6. What challenges come with multi-agent scraping?
The biggest challenges include coordination overhead, cost scaling, deduplication, and maintaining observability across agents. Well-designed orchestration and validation layers mitigate these issues by providing centralized monitoring and automated error handling.
7. Is multi-agent scraping suitable for small teams or startups?
Yes, but at a smaller scale. Even a three-agent setup — discovery, extraction, and validation — can dramatically improve efficiency. Cloud-based orchestration tools make it feasible without building large infrastructure.
8. What industries benefit most from multi-agent scraping?
Industries that depend on real-time competitive or market data: eCommerce, finance, real estate, travel, and retail analytics. These sectors need rapid, reliable insights that can only come from distributed, fault-tolerant scraping systems.















