



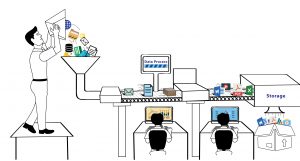
Web Scraping has become an integral part of Data Science is an ecosystem in itself and the term often ends up getting used as a substitute for machine learning, artificial intelligence, and others. The data science ecosystem consists of five different stages which together make up the entire lifecycle. Each step consists of multiple options which used to complete that step-
Web Scraping Methods:
-
Data Capture
- Data Extraction using processes like web scraping.
- Manual data entry.
- Data acquisition- by buying datasets.
- Capturing signals from IoT devices.

-
Data Processing
- Data mining.
- Classifying or clustering of raw data.
- Data cleaning and normalization.
- Data Modelling.
-
Maintenance
- Data warehousing and data lake.
- Building infrastructure to manage and store data and provide maximum availability.
-
Communicating Findings
- Visualization of findings using graphs.
- Summarising findings into a textual report.
- Business intelligence and Decision making.
-
Analytics
- Exploratory and confirmatory analysis.
- Predictive analysis.
- Regression.
- Text mining.
- Sentiment and qualitative analysis.

As we can see from the above list, nothing would happen in the field of Data Science without data-capture, which is having the data that you want to run your algorithms on. This first step is crucial and is the main building block. Unless you have your systems that generate terabytes of usable data every day, the probable option for you here is to crawl data from the web and store them in databases, over which you can run your algorithms and build your prediction engine.
What are the tools that a Data Scientist can use for Web-Scraping?
In case you are a data-scientist and need to crawl data from the internet by writing your code, you can use Python to write your code. Not only does it have an easier learning curve, but it also allows you to interact with websites in an automated manner through your code. Through your code, you can interact with websites in a manner such that the website receives your requests like it would when one uses a web browser. You can automate your scraping requirements, run timely scripts or even maintain a steady feed of data (from social media websites such as Twitter) to build your data-set for your data science project. Here are some of the libraries available in Python that would help you tackle different challenges faced by people when scraping data for their projects-
-
Requests
When you want to crawl data from the web through code, the first aim would be to hit websites using code. That is where the requests library comes in. It is a favorite among the Python community because of the ease with which you can make calls to web pages and APIs. This abstracts a lot of the boilerplate code and makes HTTP requests simpler than when using the built-in URLLib library. It includes several features such as browser style SSL verification, headless requests, automatic content decoding, proxy support and more.

-
Beautiful Soup
Once you have a web page, that you scraped from the web, you need to extract data from tags and attributes on the HTML page. For this, you need to parse the HTML content such that all the data becomes easily accessible. BeautifulSoup allows easy parsing of HTML and XML documents in a manner that makes navigating, searching, and modifying simple. It treats the document like a tree and you can navigate in the same way as you navigate a tree data-structure.

-
MechanicalSoup
When interacting with more complex websites. There might be a need for extended features that would help one crawl many web pages. Mechanical Soup helps in automation of storage and sending of cookies, allows redirects and can follow links and even submit forms.
![]()
-
Scrapy
One of the most powerful Python-based web scraping libraries, Scrapy provides an open-source and collaborative framework. It is a high-level scraping library used to set up data mining operations, automated spiders, periodic crawling of the web. Scrapy uses something called Spiders. They are user-defined classes used to extract information from webpages.

-
Selenium
Usually used for testing web pages and their functionality, Selenium can also be used for automatic manual tasks such as scraping data from the web using screenshots, automating clicks and scraping the exposed data, and more.

Web Scraping vs Other Data Sources:
While there are multiple data sources available today, web scraping has emerged as one of the most popular processes by which companies are procuring data (that end up getting processed and converted into usable information). One of the biggest reasons behind this is that when you are working on a data science project, you would prefer to have fresh unused data, using which you can build a thesis or predict an outcome, that has not derived before. Although data is the new oil, the value of data decreases over time. This way, web-scraping is a godsend, since data on the web gets updated every single second. It is valid only as long as it isn’t replaced by fresh data. For example, the price of an item on a website maybe $1000.
You can seek a report to get the price-list from a source. By the time the price-list reaches you with the $1000 mark, the price of the item may have decreased to $900. Hence your decision based on the price you have at hand would turn out to be wrong. Instead, if you crawl the price of an item right now, you will get its price at the moment. Then you can keep a scraper running at a regular frequency to capture the price-change every 10 seconds. Hence when you sit with the data, to make a decision, you will have both updated and historical data and this can improve the results. A steady stream of never-ending data is what web-scraping delivers. That’s the main reason for Data Sciences, whether it’s by a marketing manager or a research scientist.
The challenges of using scraped data in Data Science:
While the data that you get by web-scraping is massive and regular. An important fact is that data extracted from the web usually contains a high quantity of unclean and unstructured data. What also seen is the presence of duplicates as well as unverified data points. Getting your data sources correct is important and hence data should always crawl from verified and known websites. At the same time, many data sources used to confirm data. Cleaning up data and making sure duplicates are absent tackled using some intelligent coding. But then converting unstructured data to structured data remains one of the toughest web-scraping problems and the solutions vary from case to case.
The other major problem arises out of security, legality, and privacy. With more and more countries ruling for data privacy and higher limits on access to data, more and more websites are today accessible only via a login page. Unless you crawl data, there is a possibility of a penalty for the same. It can start from your IP getting blocked, to a lawsuit against you.
Conclusion:
Every opportunity comes with its challenges. The greater the challenge the higher the reward. Hence web scraping needs to integrate into your business workflow, and data-science projects need to generate usable information from that data. But if you need help scraping data from websites for your company or startup, our team at PromptCloud provides a fully managed DaaS solution where you tell us the requirements and we set up your scraping engine.















