




Data mining and what it is solving today
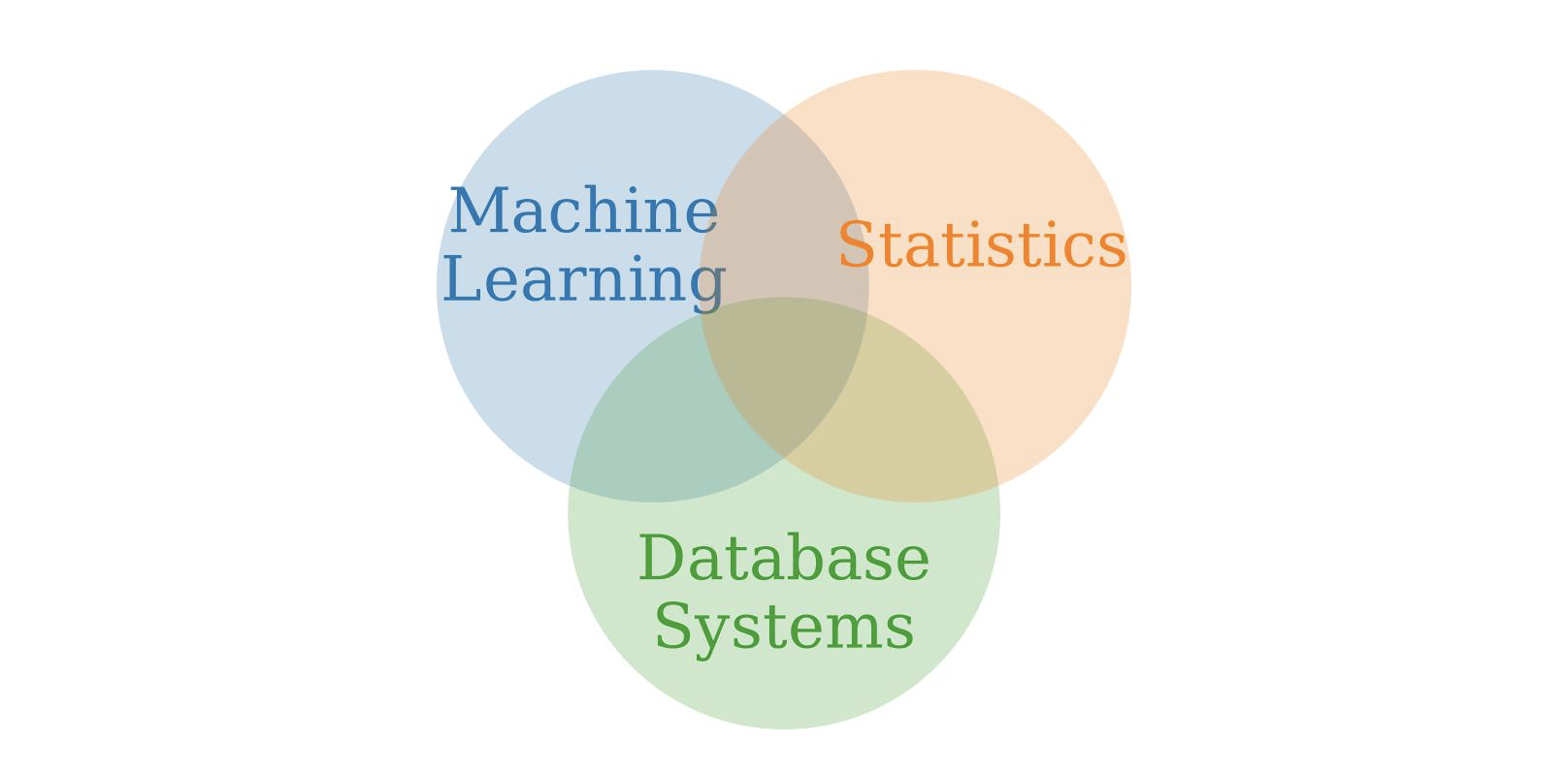
Data mining is an interdisciplinary topic that encapsulates Machine Learning, Statistics as well as Database Systems. Data mining would have been a mathematical subject had we been able to find trends in large datasets using pen and paper. Unfortunately, the computations involved are too massive and that is why we need a computer to find the hidden answers lying in our data. In the Venn diagram below, the area in the very middle, where the three topics intersect is where Data mining lies. But the diagram does not talk about an important factor that is even more necessary for data mining, one that we will soon find out
When undertaking projects involving data mining, people tend to get lost in the maths, the algorithms, and the computations involved. Even setting up the infrastructure itself (be it on-site or in the cloud), takes considerable time and effort. Often the most important aspect lies forgotten until a later point of time- the “data”.
Data Mining finds multiple uses today-
- Plagiarism checks
- Sentiment analysis from social media data
- Monitoring discussions in online forums (for national security)
- Fake News Recognition
- Business intelligence
… and more
Web scraping to collect data
These are some of the latest challenges that data is being used to overcome these days and the one thing common that you might have spotted is that all of these require web data. Web data is huge and is growing at a really humongous rate. As per this article, the Washington Post estimates that there are 305,500,000,000 pages online at the moment. However, you don’t need to worry about so many pages. You could use web scraping techniques to crawl a few thousand pages and extract their data to find answers to the problem statement that your team is facing. Web scraping for data mining is a complete and foolproof solution unlike other sources of data. Also, there are minimal chances of web-data falling short of your requirements, because of the sheer amount of data present. This in turn might seem hard to handle it first, but you can pick and chose the web pages, or data streams that are best suited for your study, and later on add to it as you deem suitable.
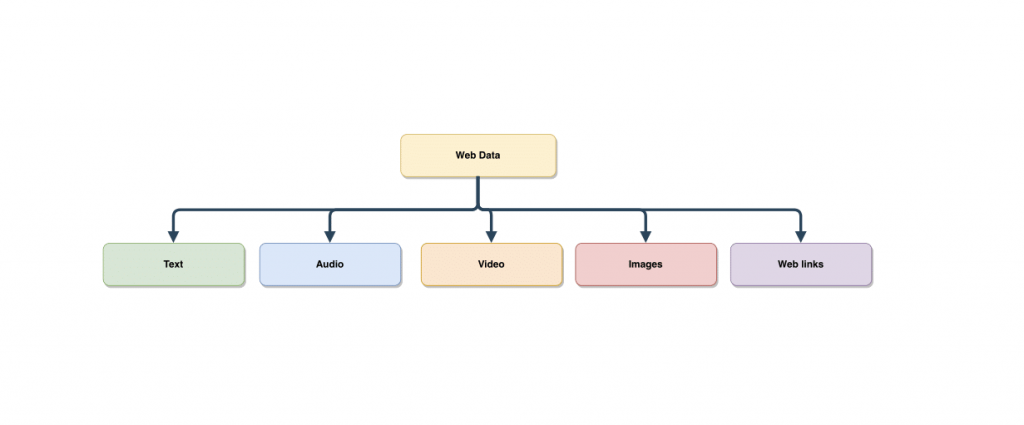
Implementing Web Scraping as the first step of Data Mining
Web Scraping to build large datasets, that you can in turn use for data mining, used to be a lengthy process in the early age of computers when people used to copy-paste text. But with the help of automated scrapers and scraping bots, the time taken to build your database and to keep it updated has gone down considerably. Whereas building a new team can be a lengthy process, several DaaS providers like PromptCloud do exist in the market today, and can act as a bridge between you and the data you need for your research. A downside of web-scraping can be unstructured data- text, images, videos, audio, and more. However, using intelligent scrapers different forms of data can be segregated and stored in separate databases or S3 containers so that they are available in plug-and-play formats and easily usable by the Data Mining Engine.















