




What are Web Scraping Challenges?
Web scraping didn’t suddenly get harder in 2026. It got less forgiving. Most pipelines fail now not because of one big blocker, but because of many small ones stacking up quietly. Anti-bot systems that adapt mid-session. JavaScript that changes per user. Layouts that mutate without warning. Compliance rules that vary by geography and intent. If your scraper still assumes fetch, parse, done, you’re already behind.
An Introduction to the New Challenges of Web Scraping
Every year, people say web scraping is getting harder. That line is lazy. What actually changed in 2026 is how failure shows up. Scrapers don’t crash loudly anymore. They succeed and still give you the wrong data. Pages load fine, but fields drift. Requests return 200s, but the content is personalized junk. A pipeline runs green for weeks while quality slowly rots underneath.
Meanwhile, websites are no longer static documents. They’re adaptive systems. They respond differently based on geography, session history, browser fingerprint, and even crawl cadence. The page you see once is not the page you’ll see tomorrow, or the page your crawler sees at scale.
This piece breaks down the real web scraping challenges in 2026, not the surface-level ones you’ve read a dozen times already. These are the problems teams actually spend time debugging. The ones that cause silent data loss, bad decisions, and late-night rollbacks.
Many organizations begin web scraping with internal scripts, but maintaining crawler infrastructure, handling anti-bot protections, and monitoring data quality quickly becomes a full-time operational task.
Trusted by data teams at global retailers, financial institutions, and AI platforms processing billions of records annually.
“PromptCloud reduced our scraping failure rate by over 40% within the first quarter.”
Head of Data Engineering
Global Retail Brand
Challenge 1: Anti-Bot Detection Systems That Learn Over Time
Most articles still talk about anti-bot detection as if it’s a static wall. Solve CAPTCHA, rotate proxies, move on. That mental model is outdated.
In 2026, anti-bot systems behave more like feedback loops. They don’t just look at a request. They observe patterns over time. Session depth. Navigation order. Retry behavior. Even though your scraper hesitates between actions. A headless browser that works today can become suspicious tomorrow without any code change on your side. Not because it was blocked, but because its behavior no longer matches evolving human baselines.
This is where many teams get stuck. They keep adding patches. New headers. New fingerprints. More proxies. Each fix works briefly, then decays. You need session strategies that don’t reuse suspicious patterns. And you need monitoring that tells you when success rates stay high but content quality drops.
This is why scalable systems now treat detection as a moving variable, not an obstacle. If you’re still hardcoding around blocks, you’ll lose the race quietly.
According to Imperva’s Bad Bot Report 2024, automated traffic accounts for nearly 49% of all internet traffic, and sophisticated bot traffic continues to rise year over year. Detection systems are evolving because bot behavior is evolving.
See how enterprise teams solve these web scraping challenges in production. Read the case study.

Figure 1: A visual breakdown of how modern scraping failures emerge gradually through detection, rendering instability, semantic drift, and silent data degradation.
Challenge 2: JavaScript-Heavy Websites and Dynamic Rendering
Most modern pages don’t have a single finished state anymore. They hydrate. Re-render. Personalize. Fire background calls long after the first paint. What your scraper captures depends on when it looks, not just what it loads.
This breaks a lot of old assumptions. Teams still design scrapers around a moment in time. Wait for the DOM to be ready. Wait for the network to be idle. Extract. Done. But many pages never go idle. Some keep polling. Others lazy-load critical fields only after user interaction. Prices appear after scrolling. Availability appears after location resolution. Reviews load after consent checks.
So what happens?
Your scraper works in staging. It works on day one. Then, at scale, fields go missing intermittently. Not all records. Just enough to poison downstream logic. This is where data quality issues start masquerading as “edge cases.” In reality, the extraction logic is racing the page lifecycle and losing unpredictably.
Headless browser scraping helps, but it’s not a silver bullet. Running a browser doesn’t mean you captured the right state. You still need to define stability conditions. What signals mean “this data is final enough”? What events matter? What can be ignored?
In 2026, strong teams treat JavaScript rendering as a coordination problem, not a tooling problem. They explicitly model page states. They version extraction logic based on render paths. And they monitor field-level completeness, not just page success rates. If your scraper can’t explain why a field is missing, you don’t have a scraping issue. You have an observability gap.
Challenge 3: Website Structure Changes and Semantic Drift
This one catches even experienced teams off guard. In 2026, many website structure changes don’t involve obvious HTML rewrites. No class names change. No tags disappear. Your selectors keep matching. And yet, the data is wrong.
Why?
Because structure has moved up the stack. Sites now experiment through configuration flags, CMS rules, and client-side logic. A price field might still exist, but its meaning changes based on region. A badge might render in the same DOM node, but represent a different state. The markup stays stable while semantics drift.
This is why selector-based monitoring is no longer enough. Your scraper doesn’t break. Your pipeline doesn’t alert. But downstream numbers start behaving strangely. Conversion models drift. Price deltas spike. Inventory appears to oscillate. Teams that handle this well track expectations, not just extraction. They validate ranges. They compare distributions. They ask whether today’s data still behaves like yesterday’s data.
Challenge 4: Scraping at Scale and Pipeline Coordination Failures
- Small-scale scraping failures are obvious.
- Large-scale scraping failures are procedural.
Once you cross a few hundred sources, the problem stops being can we scrape this site and becomes can we operate all of this without tripping ourselves. Different crawl frequencies. Different retry policies. Different rendering paths. Different legal constraints. All running at once. This is where many pipelines buckle. One source slows down and backs up the queue. Another needs higher freshness and starves the rest. A third suddenly starts rate-limiting and causes retry storms. Strong systems isolate failure domains. They don’t let one site’s instability leak into others. They separate crawl intent from execution. They treat retries as controlled decisions, not automatic reflexes.
And most importantly, they stop thinking in pages and start thinking in pipelines. If you can’t explain how data flows from request to delivery under stress, you’re already losing reliability. This is also where the proxy strategy stops being an afterthought. Rotation isn’t just about avoiding blocks anymore. It’s about traffic shaping, failure isolation, and geographic correctness at scale.
Challenge 5: Data Quality Issues in Web Scraping Pipelines
In 2026, the most dangerous scraping failures are the ones that look like success. Requests complete. Pages load. Files are delivered on time. Dashboards stay green. And yet, the data slowly becomes unusable.
This happens because most pipelines still monitor execution, not outcomes. Fields start going null intermittently. Text values shift format. Numbers stay numeric but drift outside expected ranges. Duplicates creep in because identifiers subtly change. None of this breaks a scraper. All of it breaks decisions. Teams often blame downstream systems when this surfaces. Models “behave oddly.” Reports “feel off.” Pricing logic starts overcorrecting. By the time someone inspects the raw data, weeks of silent decay have already passed.
In 2026, data quality issues are rarely caused by one bad scrape. They’re caused by small inconsistencies accumulating across time and sources. High-performing teams treat quality as a continuous signal. They track field-level completeness. They compare distributions week over week. They flag anomalies even when extraction technically succeeded. This is where scraping and validation can no longer be separated.
In our analysis of 500+ large-scale scraping pipelines, the most common failure pattern was not blocking. It was silent field decay — fields dropping below 92% completeness without triggering alerts.
Execution monitoring alone failed to detect quality degradation in over 70% of cases.
Experiencing These Challenges?
Many organizations begin web scraping with internal scripts, but maintaining crawler infrastructure, handling anti-bot protections, and monitoring data quality quickly becomes a full-time operational task.
Challenge 6: Legal Compliance Risks in Web Scraping
In 2026, legal compliance scraping is no longer evaluated purely by robots.txt or technical access. Risk is increasingly determined by intent and downstream usage.
A pipeline that was considered low-risk when used for price monitoring can become legally sensitive the moment the same dataset feeds an AI model. The extraction didn’t change. The regulatory posture did.
We’ve seen real-world cases where:
- A company scraping competitor pricing began training internal recommendation models on that dataset.
- Legal review reclassified the activity as higher risk due to derivative AI usage.
- The entire scraping pipeline required redesign, audit trails, and usage segmentation.
The modern compliance challenge has three dimensions:
- Jurisdictional variance – EU, US, APAC treat data use differently.
- Purpose limitation – monitoring vs redistribution vs AI training.
- Traceability – Can you prove where each record originated and under what policy?
According to Gartner (2025 AI Governance Report), over 60% of enterprises deploying AI initiatives were required to retroactively audit their training data sources for compliance exposure.
Compliance is now a systems design decision. If you cannot trace usage intent, enforce access controls, and document lineage, you are exposed — even if technically allowed to scrape.
Strong pipelines embed:
- Data lineage logging
- Source-to-use mapping
- Policy tagging by geography
- Automated redaction workflows
In 2026, “can we scrape this?” is the wrong question. The real question is: “Can we defend how this data is used?”
Challenge 7: Website Blocking Scrapers Without Explicit Errors
This is one of the nastier shifts in 2026. A lot of sites no longer block scrapers outright. No CAPTCHA. No 403s. No obvious signals. Instead, they degrade what you see. Prices are rounded differently. Availability delayed. Reviews truncated. Pagination capped early. Sometimes the page loads perfectly, but you’re served a simplified or stale variant that no real user ever sees.
From the scraper’s point of view, everything worked. From a business point of view, the data is quietly wrong. This kind of blocking is hard to detect because it targets trust, not access. Teams often discover it only when scraped data diverges from ground truth or from what manual checks show in a browser.
In 2026, the only reliable defense is comparison and expectation-setting. You need baselines. You need to know what “normal” looks like per source, per region, per access pattern. When your scraper starts getting a different version of reality, you need to catch it early. This is also why blind retries make things worse. If a site decides you’re suspicious and starts serving degraded content, retrying harder just reinforces that decision. Blocking has become subtle, adaptive, and asymmetric. If your pipeline assumes that “success equals truth,” you’re already exposed.
Download The State of Web Scraping 2026 to see how teams are adapting pipelines to anti-bot systems, data quality drift, and compliance pressure. This report maps real failure patterns we see across large-scale scraping systems.
Challenge 8: Proxy Rotation and Geographic Data Inconsistency
Proxy rotation used to be a simple lever. Get blocked. Rotate IP. Continue. In 2026, that logic creates as many problems as it solves. Modern sites don’t just care that you’re coming from different IPs. They care how those IPs behave. Rotate too aggressively and you fragment sessions. Rotate too slowly and patterns emerge. Rotate without geography awareness, and you get the wrong content entirely.
This is where many teams accidentally sabotage themselves.
A scraper might pull prices from one region, availability from another, and reviews from a third, all for the same URL. Every request succeeds. Every field looks valid. But the combined record never existed for any real user. That’s not a scraping bug. That’s a coordination failure. In 2026, proxy rotation is no longer a defensive trick. It’s part of data correctness. You need to decide when identity should persist and when it should change. You need to bind proxies to sessions intentionally. And you need to understand how location, language, and consent flows affect what the page returns.
Strong pipelines treat proxy choice as a first-class parameter, not a background utility. They log it. They validate against it. And they know when rotating more actually makes things worse.
Challenge 9: Headless Browser Scraping at Scale
Headless browser scraping is the default answer when the site is JavaScript-heavy. And yes, it unlocks pages you cannot reliably scrape with plain HTTP. But in 2026, browsers introduced a new class of problems that teams underestimate until they go live.
First, cost and throughput. Browsers are slower, heavier, and far less predictable under load. One “small” change on a site, like an extra script, a new consent flow, or a delayed API call, can blow up your render times and your infrastructure bill.
Second, stability. Rendering is not deterministic across regions, sessions, and devices. A headless browser can still return partial states depending on timing. If your extraction depends on “wait 3 seconds then scrape,” you’re basically guessing.
Third, detection. Many anti-bot systems now assume browsers. So running one does not make you look human. It just moves the detection surface from headers to behavior, fingerprints, and interaction patterns. The outcome is a trap: teams adopt browsers to reduce breakage, then end up firefighting a different set of failures. Timeouts, incomplete DOM, memory leaks, flaky selectors that only fail at scale.
The teams that win with headless browser scraping treat it like a constrained tool, not the default engine. They use it only where it changes outcomes, and they put hard controls around it: render budgets, state checks, and field-level quality gates.
According to HTTP Archive Web Almanac 2024, the median web page now loads over 2MB of JavaScript. Rendering cost is not theoretical — it directly impacts scraping stability and infrastructure cost.
Challenge 10: CAPTCHA Handling and Behavioral Detection Systems
CAPTCHA used to be a wall. In 2026, they’re a signal. Many teams still treat CAPTCHA handling as a technical puzzle. Plug in a solver. Increase retries. Escalate to manual. Move on. That approach misses what CAPTCHA actually indicates now.
A CAPTCHA is rarely the root problem. It’s the system telling you your access pattern no longer makes sense. Solve it blindly, and you often make things worse. You confirm the suspicion. You increase scrutiny. You push the site to respond with degraded content instead of outright blocks. This is why teams that beat CAPTCHA still end up with unreliable data. In 2026, effective CAPTCHA handling starts earlier. It’s about reducing how often you trigger them in the first place. Crawl pacing. Session coherence. Navigation realism. Geographic consistency. All of these matter more than the solver itself.
When a CAPTCHA does appear, strong systems treat it as a branching decision, not a failure. Should this session continue? Should it cool down? Should traffic shift? Should this source be reclassified as high-friction? CAPTCHAs are no longer an obstacle to bulldoze through. They’re feedback loops you either listen to or ignore at your own risk.
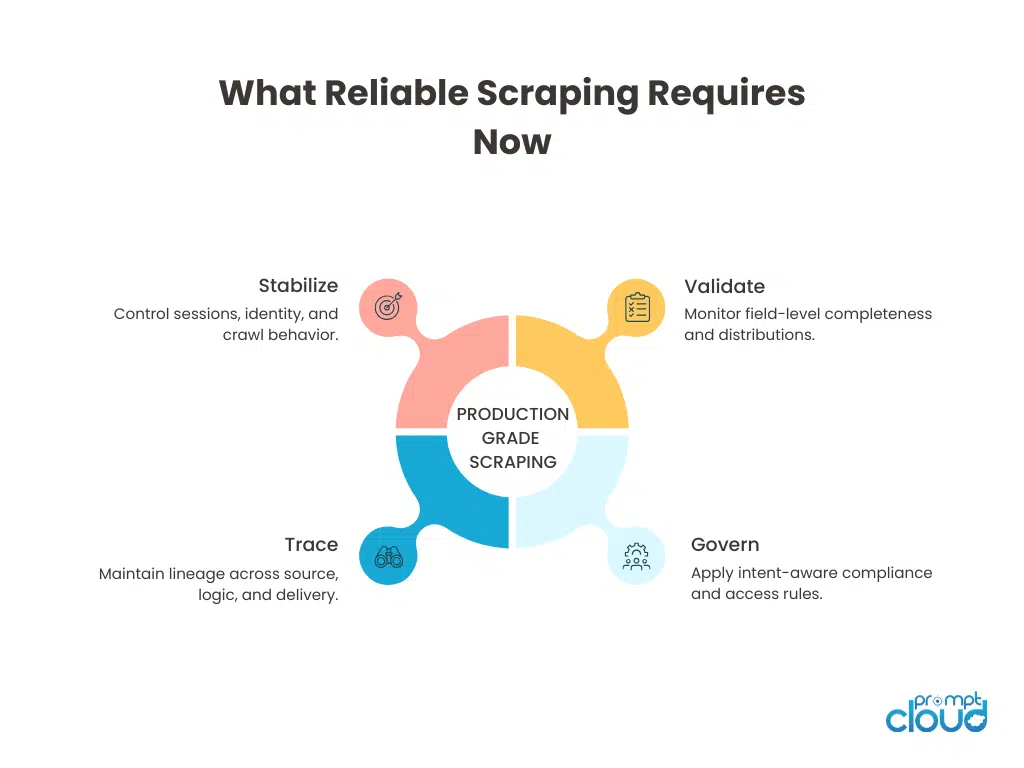
Figure 2: The operational pillars required to run web scraping as a reliable, production-grade data system in 2026.
If you want to go deeper
- Designing scrapers that survive at scale – Why architecture decisions matter more than extraction logic.
- What proxy rotation actually solves and what it breaks – How identity, geography, and session design affect correctness.
Why monitoring is the difference between data and noise – How teams catch silent scraping failures before they spread. - When compliance becomes a data quality problem – Why governance, lineage, and intent now shape scraping systems.
Why modern bot detection is behavioral, not signature-based – This overview explains how adaptive detection systems learn patterns over time, which is why static scraping tricks decay so fast.
What Changes When You Treat Web Scraping as Infrastructure
Most discussions about web scraping challenges still frame the problem as adversarial. Scrapers versus websites. Bots versus defenses. That framing is outdated. What actually defines success in 2026 is operational maturity. Scraping systems fail today not because they can’t fetch pages, but because they can’t explain themselves. They don’t know why a field disappeared. They can’t tell when content changed meaning. They can’t trace where a record came from or whether it still reflects reality.
The teams that struggle are often doing “everything right” in isolation. They use browsers. They rotate proxies. They solve CAPTCHAs. But they’ve stitched together tactics without a governing system. So when things drift, no one notices until decisions go wrong.
The teams that succeed treat web scraping as infrastructure. They design for change. They expect variance. They assume sites will adapt and regulations will tighten. And they build feedback into the pipeline instead of bolting fixes on top.
In that world, scraping isn’t fragile. It’s just demanding. If you approach 2026 with yesterday’s mental models, web scraping will feel impossible. If you approach it like a system you actually run, it becomes manageable again.
Many organizations begin web scraping with internal scripts, but maintaining crawler infrastructure, handling anti-bot protections, and monitoring data quality quickly becomes a full-time operational task.
What To Do About These Web Scraping Challenges in 2026
If you look closely, none of these challenges are purely technical. They are architectural.
Anti-bot systems adapt. JavaScript never settles. Proxies distort geography. Compliance depends on usage. Data quality decays silently.
What separates fragile scraping from production-grade infrastructure is observability, coordination, and policy control.
At PromptCloud, scraping systems are designed around:
- Field-level quality monitoring
- Controlled proxy and session orchestration
- Browser render governance
- Legal-aware data lineage
- Failure isolation at source level
If your current pipeline cannot explain why a field changed, why a page rendered differently, or where a record originated, it is operating on borrowed time.
What separates successful teams is operational discipline. They don’t treat scraping as code—they treat it as infrastructure. This is why managed web scraping services require production-grade reliability, governance controls, and long-term maintenance ownership. Organizations reaching this realization often evaluate whether continuing DIY scraping aligns with their scale and risk profile.
Scraping in 2026 is not about bypassing defenses. It is about building resilient data infrastructure.
FAQs
Why are web scraping challenges harder in 2026 than before?
Because failures are subtle now. Most pipelines don’t break loudly. They return plausible but wrong data.
Is headless browser scraping still worth using?
Yes, but selectively. It solves rendering problems while introducing cost, stability, and detection tradeoffs.
Can proxy rotation alone prevent blocking?
No. Poorly designed rotation often causes data inconsistency and increases suspicion instead of reducing it.
How do teams detect silent data quality issues?
By monitoring field-level behavior and distributions, not just request success rates.
Is legal compliance only about robots.txt?
No. In 2026, intent, usage, and traceability matter as much as access rules.
Are CAPTCHAs always bad?
They’re warnings. Treating them as feedback leads to better long-term stability than brute-force solving.
Many organizations begin web scraping with internal scripts, but maintaining crawler infrastructure, handling anti-bot protections, and monitoring data quality quickly becomes a full-time operational task.















