


Table of Contents
show
Introduction To Cloud Scraping and Web Crawling:
Web Crawling is a method done by companies to source and extracts information from various websites that have information that is available publically. It is a technique in which data extracted from web pages in an automated way. The scripts can load can extract the data from multiple pages based on the requirements of the client or the customer.
Web Crawling or web scraping is a new way forward and it has changed the way many organizations work across the globe. It has altered how organizations think and work.

This Is An Unconventional Guide To Deal With Web Crawling And Scraping And The Complexities That It Brings Up:
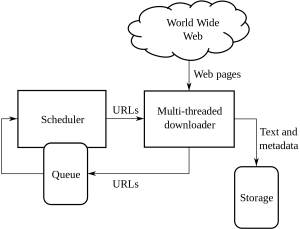
1. Choosing The Right Tool:
This step depends on the project taken up by you. The Python code has a set of different libraries and frameworks ready for the deployment of a website crawl. It has multiple functionalities and used by anyone to extract information from a website of your choice.
Some Types Of Pythons That Are Used In Web Crawling Are:
BeautifulSoup:
This is a code where it parses the library of HTML and XML documents. It is a combination of parsing and making HTTP sessions.
Scrapy:
This is a web crawling and framework and it completely provides a tool for scraping.
Selenium:
For all the heavy JSON rendered files this is the best use of python as it can parse all that information with ease and do it in a quicker timeframe if the size of the data is small.
Selenium is especially useful when scraping dynamic websites that heavily rely on JavaScript, AJAX, or other client-side technologies. Python is a popular programming language known for its simplicity and versatility. It provides a wide range of libraries and tools for web scraping, making it a preferred choice for many developers. By performing Selenium automation with Python, you can harness the power of both to scrape websites effectively.
These are the various types of Python codes used for web crawling.

2. Dynamic Pages or Rendering on Behalf of Client:

Websites these days are becoming more and more interactive and are being user friendly as much as possible. This is being done so that the users have a quick and easy look at the products sold to them. Modern Websites use a lot of dynamic and static coding practices used mainly not related to data crawling.
How Can You Detect If It Is Dynamic or Static Page?
You can detect the pages use asynchronous loading. For dynamic pages, you have to view the page source to find out if it is a dynamic or static page. Most websites these days are JavaScript rendered so they so scraping is particularly difficult at times.

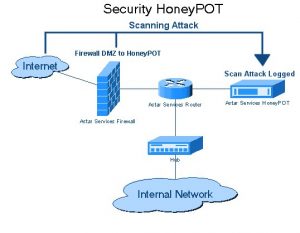
3. Traps of Honeypot
Website developers use honeypot traps on the websites in the form of links. These links are not visible to the typical user of the website. When a web crawler tries to extract data from the link, the website detects the same and triggers the block of the source IP address.

4. Authentication:
When we crawl data from different websites we need to get an authentication first into the website. Only after which we can be able to crawl the data.
There are 2 types of Inputs in the Authentication:
Hidden Inputs:
When more data provided like CSRF_TOKEN with the username and password provided.
More Header Information:
This will give a post header before making the POST request. For more information on the same head to Pluralsight.
5. Captcha:
This is a type of challenge-response code written by developers. This is to authenticate the user before he or she gives access to certain websites or features of a website. When captchas are present on the websites that you want to crawl or scrape. The setup will fail as web crawlers cannot cross the captcha barriers of websites.

6. IP Blocking:
This is a common method by Governments of all countries. If they find something that is malicious or anything dangerous then they might cancel the source IP of the crawler. To avoid the blocking of the IP the developer has to create and rotate the identity of the crawler across all platforms and make sure it works on all browsers.

7. Frequent changes in the Structure of the Framework of Web Crawling:

HTML passed into content-specific pages. Developers try to stick to the same structure but end up making changes to some parts of the HTML pages. This is by changing the ID of the website and all the elements of the HTML code. Developers also quest on how to improve the user interface of the website. When they land upon an idea the framework usually gets changed to give the customer or the client ease of usage on the website. They also leave behind fake data generated by them. This process is to leave behind the crawlers that are trying to crawl their data.

Conclusion:
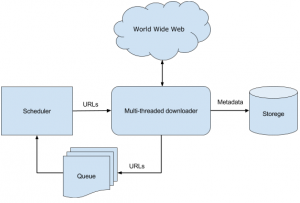
These are the various unconventional methods of web crawling. Web crawling is not an illegal process as many think it is. Web crawling is the extraction of data that is available to the general public from different websites across the globe by either using a web scraping tool or web scraping service. Making the most of data is possible once you have the data with you. While building your web scraping team might not be possible for every company and using internal data might not be enough for an ambitious data science project. That is the reason why our team at PromptCloud, not only offers you data scraped from the web but a full-blown DaaS solution, in which you feed in your requirements.















