



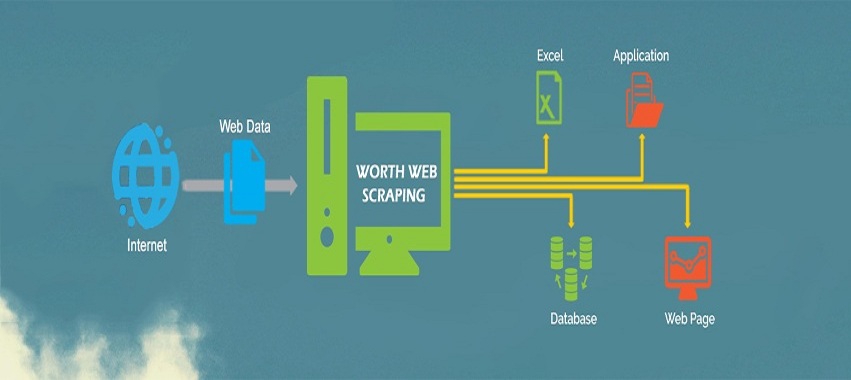
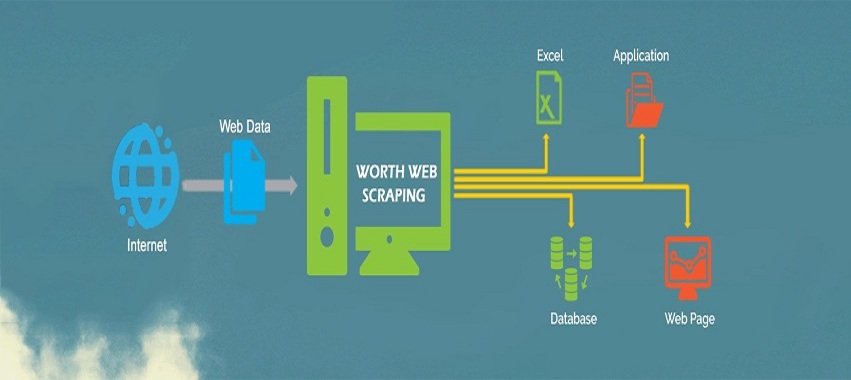
We have all used crawlers in some capacity; either trying to get our hands dirty with some DIY scraper tools or having companies like PromptCloud do it for a custom use case. Given the current web technologies, most of the concepts around acquiring data from the web remain the same irrespective of the tool in use.
So here’s an introduction to a typical journey of a crawler through mines of web pages, and eventually gracing its way through with beautiful data.
Phase 1- The seed
Every crawler needs a starting point. A seed is a URL or a set of URLs where the crawler has to begin searching towards the next depth. In case you’re looking to traverse an entire domain, this would be just the domain URL like amazon.com or if you have already distilled certain places on the domain to foray into, it’d be those specific URLs. For instance, if you are a seller with toys in your inventory, category links like these would be your seed- https://www.amazon.com/toys/b/ref=sd_allcat_tg?ie=UTF8&node=165793011.
Phase 2- The discovery process
On the web, there could be various directions you could go at any point in space. Each hyperlink on a page is a path that a web crawler can potentially take to further move to the next depth levels. However, if you’re looking for specific data as opposed to indexing the whole web, there’s a limited set of paths you can take to finally reach the destination page that hosts your imperative. Once the crawler is placed on the starting point, you need to instruct it to the next relevant depth until it discovers the ultimate destination pages.
Continuing with the above example of Toys section on Amazon, you’d tell your crawler to move to subcategory pages like these- https://www.amazon.com/s/ref=lp_165793011_nr_n_0?fst=as%3Aoff&rh=n%3A165793011%2Cn%3A%21165795011%2Cn%3A165993011&bbn=165795011&ie=UTF8&qid=1453888737&rnid=165795011 (Action Figures & Statues), and further down into these- https://www.amazon.com/s/ref=sr_ex_n_1?rh=n%3A165793011%2Cn%3A%21165795011%2Cn%3A165993011%2Cn%3A166026011&bbn=166026011&ie=UTF8&qid=1453890223 (Statues & Bobbleheads), until you reach these- https://www.amazon.com/s/ref=lp_166026011_nr_n_0?fst=as%3Aoff&rh=n%3A165793011%2Cn%3A%21165795011%2Cn%3A165993011%2Cn%3A166026011%2Cn%3A2514596011&bbn=166026011&ie=UTF8&qid=1453890218&rnid=166026011 (Statues). This is where coverage comes into play. The more precise your instruction, the better job would the crawler do in covering all possible destination pages.
Phase 3- Creating a queue and crawling destination pages

Your crawlers have so far done a great job of drilling down into maximum depths. They have treasure hunted the final pages that list your destination URLs i.e. the actual product pages like these- https://www.amazon.com/Funko-Movies-Dragon-Exclusive-Figure/dp/B0189S8WZO/. Next up is collating all of these URLs and pushing them to a common repository from where they can be picked to be crawled.
Crawling here essentially means fetching the complete HTML page by making calls to these URLs just like you do when you enter them in your browser’s address bar. Some fetches could fail; either due to requests timing out or another journey from crawl errors and hence a contingency plan is integral to any crawler so as to minimize such failures.
All of these fetched HTML dumps then need to be stored at a place where the final scraping can occur.
Phase 4- Data Scraping
Now that you have all the pages of your interest, it’s time to crawl only the relevant pieces of information that you need from these pages, in accordance with your database’s schema or fields in your excel. In the above example, we could be looking for the product name, description, price, availability, brand and so on. So you’d have to pass these rules to your crawler in a language that it understands, instructing it to only look for these fields while being agnostic to the rest of the HTML sections.
Phase 5- Structuring the data
By now, you should have also setup rules in your crawler for structuring all of this data post-crawl. For example, you’d require all your data to appear in an XML like below, record after record.
Funko Pop Movies Bruce Lee Enter the Dragon Exclusive Vinyl Figure
BAIT Exclusive x Funko POP Movie Enter the Dragon – Bruce Lee
$20
Yes
Funko
……………………….
Or in a CSV row after row-
product_name,product_description,price,stock,brand
Funko Pop Movies Bruce Lee Enter the Dragon Exclusive Vinyl Figure,BAIT Exclusive x Funko POP Movie Enter the Dragon – Bruce Lee,$20,Yes,Funko
………………………….
And there you have it; big data made usable; with just a single starting point and some rules for discovery and extraction of data. While some journeys are more complicated than others; this is the usual journey any crawler, looking for relevant structured information from the web, follows.















