



Web scraping has gained tremendous popularity over the course of the last 10 years and still continues to attract businesses to leverage web data for various business cases. Majority of companies in the e-commerce, travel, job and research space use have either set up an in-house crawling system or engage with a dedicated web crawling service provider. Here, we provide a FAQs on Web Scraping that will help you to clear the doubts.
Here is a Google trend search that shows growing interest in web scraping:
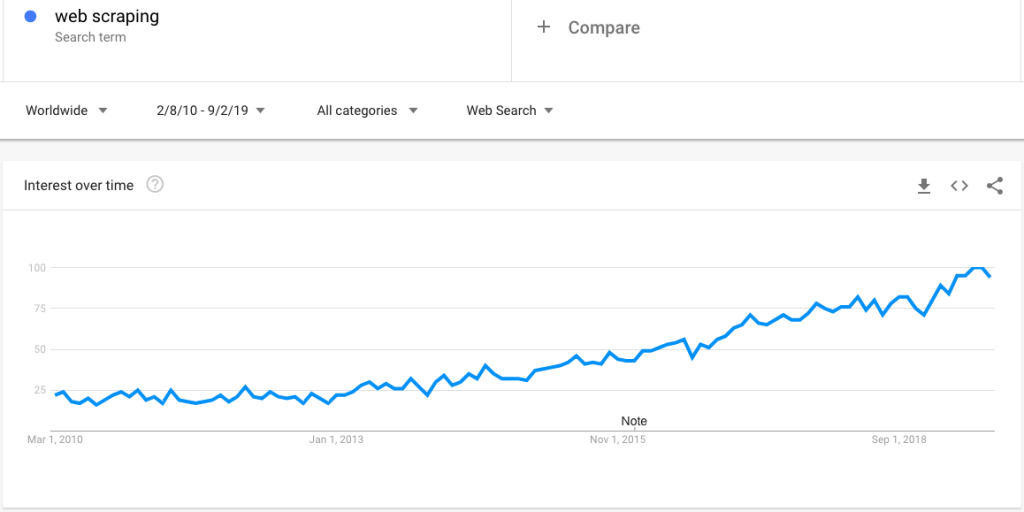
However, with growing interest, comes a large number of questions around web scraping. In this post, we clarify an extensive set of questions:
Q. What’s web scraping?
A. Web Scraping (also known as web data extraction and web harvesting) is the technique of automating the process of data collection from websites via an intelligent program and save them in a structured format for on-demand access. It can also be programmed to crawl data at a certain frequency like daily, weekly, and monthly or deliver data in near real-time.
Q. Which web scraping is the best?
A. There are several ways of extracting from the web — from dedicated web scraping services providers to vertical-specific data feed providers (e.g. JobsPikr for job data) and scraping tools (can be configured to perform simple and one-off web data collection).
The choice of the solution and approach really depends on the specific requirements. As a general rule, consider a web scraping service provide when you need to collect large amounts of web data (reads millions of records every week or day).
Q. What is web scraping used for?
A. There are several use cases of web scraping. Here are the most common ones:
- product and price comparison
- insight mining and reputation management via review data extraction
- competitive intelligence
- product cataloging
- training machine learning algorithm
- research and analysis of certain industries
Q. What is web scraping in python?
A. Web scraping can be done via different programming and scripting languages. However, Python is a popular choice and Beautiful Soup is a frequently used Python package for parsing HTML and XML documents.
We have written a couple of tutorials on this topic — you can learn about them from our post on web scraping examples.
Q. What is web scraping and crawling?
A. Web scraping can be considered as a superset of web crawling — essentially web crawling is done to traverse paths of web pages so that different steps of web scraping can be applied to extract and download data.
Q. What are web scraping tools?
A. These are primarily DIY tools in which the data collector needs to learn the tool and configure it to extract data. These tools are generally good for one off web data collection projects from simple sites. They generally fail when it comes to large volume data extraction or when the target sites are complex and dynamic.
Q. What is web scraping Reddit™?
A. This is simply the process of extracting data from Reddit which is a popular social platform to build different types of communities and forums. Data from Reddit can be scraped to perform consumer research, sentiment analysis, NLP, and machine learning training.
Q. What is web scraping services?
A. Web scraping service is simply the process of taking the complete ownership of the data acquisition pipeline. Clients generally provide the requirement in terms of the target sites, data fields, file format and frequency of extraction. The data vendor delivers the web data exactly based on the requirement while taking care of the maintenance of data feed and quality assurance.
Q. What is web scraping LinkedIn™?
A. Although many companies would like to access data from LinkedIn™, it is legally not allowed based on the robots.txt file and terms of use.
Q. When to web crawl?
A. As a company, you should web crawl when you need to perform any of the use cases mentioned above and would like to augment your internal data with comprehensive alternative data sets.
Q. Is web scraping legal?
A. It is indeed legal as long as you are following the guidelines surrounding directives set in robots.txt file, terms of use, access to public and private content. Learn more about the legality.
Q. Is web scraping data mining?
A. Data mining is the process of uncovering insights from large-scale data sets by deploying techniques at the intersection of machine learning, statistics, and database systems. So, the data extracted via web scraping technique will be processed via various analyses and the complete process of data acquisition to insight mining can be called data mining.
Q. What is web scraping BeautifulSoup?
A. Beautiful Soup is a Python library that allows programmers to quickly work on web scraping projects by creating a parse tree from HTML and XML documents (including documents with non-closed tags or tag soup and other malformed markups) for the web pages.
The current version of Beautiful Soup 4 is compatible with both Python 2.7 and Python 3.
Q. How to collect web data – web scraping vs. API?
A. APIs or Application Programming Interfaces is an intermediary that allows one software to talk to another. When using an API to collect data, you will be strictly governed by a set of rules, and there are only some specific data fields that you can get.
But, in the case of web scraping, clients are not restricted by the rate of access, data fields (anything that is present on the web, can be downloaded), customization options and maintenance.
Q. What is web scraping in R?
A. Similar to Python, R (a language used for statistical analysis) can also be used to collect data from the web. Note that rvest is a popular package for in the R ecosystem.
However, it is not as powerful as Python or Ruby for web scraping.
Q. Why web scraping is important?
A. Web scraping is important as it allows businesses and people across the globe to access the web data which is the largest and comprehensive data repository to date. We have mentioned several use cases in an earlier question.
Check out the case study page to learn more.
Q. How web scraping works?
A. Web scraping, in general, operates with several steps. Here are the steps PromptCloud follows on a high level:
- Seeding – It is a tree traversal like procedure, where the crawler first goes through the seed URL or the base URL and then looks for the next URL in the data that is fetched from the seed URL and so on.
- Setting the direction for the crawler – Once the data from the seed URL has been extracted and stored in the temporary memory, the hyperlinks present in the data need to be given to the pointer and then the system should focus on extracting data from those.
- Queueing – Extracting and storing all the pages that the crawler parses, while traversing in a single repository as HTML files.
- Deduplication – Removing duplicate records or data.
- Normalization – Normalizing the data based on client requirements (sum, standard deviation, currency formatting, etc.)
- Structuring – The unstructured data gets converted into a structured format that can be consumed by the database.
- Data integration – The REST API can be used by clients to fetch the required custom data. PromptCloud can also push the data to the desired FTP, S3, or any other cloud storage for easy integration of the data in the company’s process.
Q. Can you web crawl Facebook™??
A. There is a huge demand for data generated on Facebook. It can be used for anything from sentiment monitoring and reputation management to trend discovery and stock market predictions. However, crawling and extracting data from Facebook has been prohibited via robots.txt file and terms of service.
This concludes the question and answers series. Post your questions in comments if you would like to discuss more or have questions that we have not addressed here.















