



The Web Is Changing (And So Is the Way We Collect Data)
Remember when web scraping felt almost playful? You could write a quick Python script, grab a few product pages, and call it a day. Back then it was mostly hobby projects and small experiments, nothing that could shake the internet.
Fast forward to 2025 and that world feels ancient. Much of the modern web sits behind JavaScript, anti-bot systems, and login walls. Cloudflare now blocks many AI crawlers by default, and TollBit is pushing bots to pay for content access. The free-for-all web has grown up, and it is learning to charge rent.
Scraping has evolved with it. What used to be a midnight cron job now runs in cloud clusters with compliance checks, rotating proxies, and human QA loops. It is no longer just a crawler. It is an operational pipeline, an entire supply chain for data. Companies depend on it more than ever. E-commerce teams watch competitor prices by the minute. Travel platforms adjust fares the instant an airline changes availability. Researchers and marketers read live reviews to catch shifts in sentiment before dashboards update.

Figure 1: From DIY scripts to event-driven pipelines, web scraping has matured into the invisible infrastructure powering how businesses read the internet.
Of course, scale brings friction. Anti-bot tools adapt quickly. Legal clarity shifts by region. And the biggest irony of all, AI needs fresh scraped data to stay useful. Think of the web as a living organism. Every layout tweak, price update, and new review is a heartbeat.
- The real question is no longer “Can you scrape it?”
- The real question is “Can you scrape it responsibly, in real time, and without crossing a line?”
If that idea resonates, take a look at our guide to ethical AI web scraping. It shows how modern teams balance automation with consent, compliance, and transparency.
How Big Is This Market, Really?
If you’ve ever tried searching “web scraping market size”, you’ve probably ended up more confused than informed. One report says it’s a billion-dollar industry. Another swears it’s worth three. And each claims to be the “most accurate” one. Truth is, they’re all measuring slightly different things. Some count only scraping software. Others include proxy networks, browser farms, API platforms, and managed data services like PromptCloud. A few even stretch the boundaries to cover the entire alternative-data market, where scraped data powers finance, AI, and retail forecasting.
Let’s make it simple.
Mordor Intelligence estimates the web scraping market at USD 1.03 billion in 2024, growing to USD 2 billion by 2030 at roughly 14% CAGR. That’s the conservative view. Research Nester places it closer to USD 3.5 billion by 2032, while Business Research Insights goes all the way up to USD 11 billion by 2037.
Even if you split the difference, it’s clear: the demand curve is steep, and the growth is not slowing down. Why? Because web data is no longer a side resource it’s an operational necessity.
Figure 2: Despite varying forecasts, every major analyst agrees the web scraping market will more than double by 2030.
Think about how fast the online world moves. Prices fluctuate by the hour. Product listings come and go within minutes. Investors, e-commerce platforms, and travel portals all depend on live intelligence to stay competitive. That’s why most experts now describe scraping as part of the data-as-a-service economy, not a standalone niche. Enterprises don’t just want access to public data they want it cleaned, verified, and delivered directly to their dashboards. That’s the shift from “tool” to “infrastructure.”
PromptCloud sits right in that space, providing managed pipelines that transform messy HTML into decision-ready datasets. If you want to see what these applications look like across industries, check out our guide to top web scraping applications – it breaks down real-world use cases from e-commerce to travel.
So how big is the market, really? Big enough that even conservative analysts agree on one thing: web scraping has become one of the fastest-growing data technologies of the decade.
Ready to turn insights into action?
Want proxy rotation that stays stable across regions and traffic spikes?
The New Pipeline: From Scheduled Crawls to Event-Driven Streams
For years, scraping was a routine task. You’d set a cron job, scrape every few hours, and store the results in a CSV. It was predictable, but painfully wasteful. Most of that data never changed between runs. Now, that entire idea feels outdated. The web moves too fast. Prices change by the minute, inventory updates in real time, and entire product catalogs shift overnight. Scraping on a timer is like taking photos of a river and pretending you understand how it flows.
That is why modern data teams are switching to event-driven scraping. Instead of scraping everything on a schedule, scrapers now wake up only when something happens. A product price changes, a new article goes live, a flight route updates and the scraper responds immediately. Think of it like subscribing to a feed of changes instead of visiting every page again and again. The result is faster updates, fewer wasted requests, and cleaner data.
This model has quietly transformed how big scraping operations run.
- Retailers get alerts the instant a competitor’s price changes.
- Travel companies capture availability changes before OTAs can.
- Financial analysts stream market updates into dashboards without waiting for batch refreshes.

Figure 3: Event-driven pipelines eliminate redundant crawls by triggering scrapers only when website content changes.
PromptCloud has built much of its infrastructure around this concept. Our event-triggered pipelines deliver data the moment a change is detected, using webhooks and message queues instead of static schedulers. The result is lighter infrastructure, faster time-to-insight, and a far more reliable way to keep AI models fed with fresh data.
If you want to see a working example of this system in action, read our deep dive on real-time web data pipelines for LLM agents. It shows how event-driven architectures handle scale, backpressure, and streaming delivery. Event-driven scraping is not a trend, it is a mindset shift. The web no longer needs to be fetched, it needs to be listened to.
The AI Hunger Problem
AI models are only as good as the data they consume. And lately, that hunger has become impossible to ignore. Every new generation of large language models needs a constant flow of real-world information. It must be fresh, diverse, and always moving. Static datasets cannot keep up anymore. The web changes too quickly, and yesterday’s pages already look outdated.
That is where web scraping quietly powers modern AI. It is the hidden engine behind many of the tools people now take for granted. When an AI system answers a question about prices, reviews, or product details, that knowledge often comes from structured web data collected in the background.
The difference today is scale. AI does not need a few thousand records, it needs billions. It does not want last month’s numbers, it wants what changed an hour ago. Scraping for AI has shifted from simple extraction to orchestration. The goal is to maintain constant flows of clean, labeled information that never stops. This hunger is reshaping the scraping world itself. Developers now train small AI models to identify web elements, detect patterns, and fix broken selectors automatically. Tools like Playwright and Puppeteer have become smarter at handling dynamic pages without breaking after every site redesign.
It has become a loop. AI depends on scraping to learn. Scraping depends on AI to stay efficient. But this new balance also comes with responsibility. The line between public and protected data keeps moving. Many websites already block automated training crawlers. Cloudflare’s policy to restrict AI bots was only the first major step, and more companies will certainly follow.

Figure 4: AI and web scraping now evolve together—each advancement in one improves automation, accuracy, and scale in the other.
For anyone handling data, this marks a turning point. The time of “collect first, ask later” is over. AI will keep driving demand for web data higher, but it will also force every player to collect responsibly, explain how they do it, and maintain transparency.
If you want a closer look at how autonomous systems now build and maintain crawlers, read AI agents that build their own scrapers. It explores the new generation of adaptive bots and where their limits still lie.
The Compliance Crunch
For years, scraping sat in a grey area. Everyone did it, but few talked about how.
In 2025, that silence is gone. The rise of AI, combined with growing concerns about content ownership, has pushed web scraping into the center of the compliance debate. Even major publishers are drafting new “machine access” policies that define who can collect their data and how often.
This shift is not just legal, it is cultural. The old idea that everything on the web is free for anyone to copy no longer holds up. Website owners see their content being used to train models or power third-party apps, and they are demanding control.
- For data teams, this means a new set of questions before every project begins.
- Are we allowed to scrape this data?
- Does the site provide a public API?
- Are we identifying ourselves clearly through headers and user agents?
- And if the owner asks for data collection to stop, do we have a process to comply quickly?
The future of web scraping will depend on how responsibly these questions are answered. The most advanced teams are already moving toward permission-based data collection, where scrapers follow machine-readable policies or access APIs directly under usage agreements. It is slower at first, but it is also safer and more sustainable in the long run.
- To make this more tangible, imagine a Compliance Maturity Index.
- At the basic level, scrapers follow robots.txt and throttle requests to avoid disruptions.
- At the progressive level, teams maintain documentation, identifiable headers, and clear removal policies.
- At the mature level, organizations sign data access agreements, log every interaction, and maintain audit trails for accountability.
That is what separates hobby projects from professional data infrastructure. Compliance is not about limiting scraping, it is about preserving it for the future. Without responsible boundaries, the open web risks being locked behind legal walls forever.
For a deeper technical look at where compliance standards are heading, you can explore robots.txt to web bot authentication. It explains how new frameworks like HTTP message signatures are shaping machine-to-machine trust online.
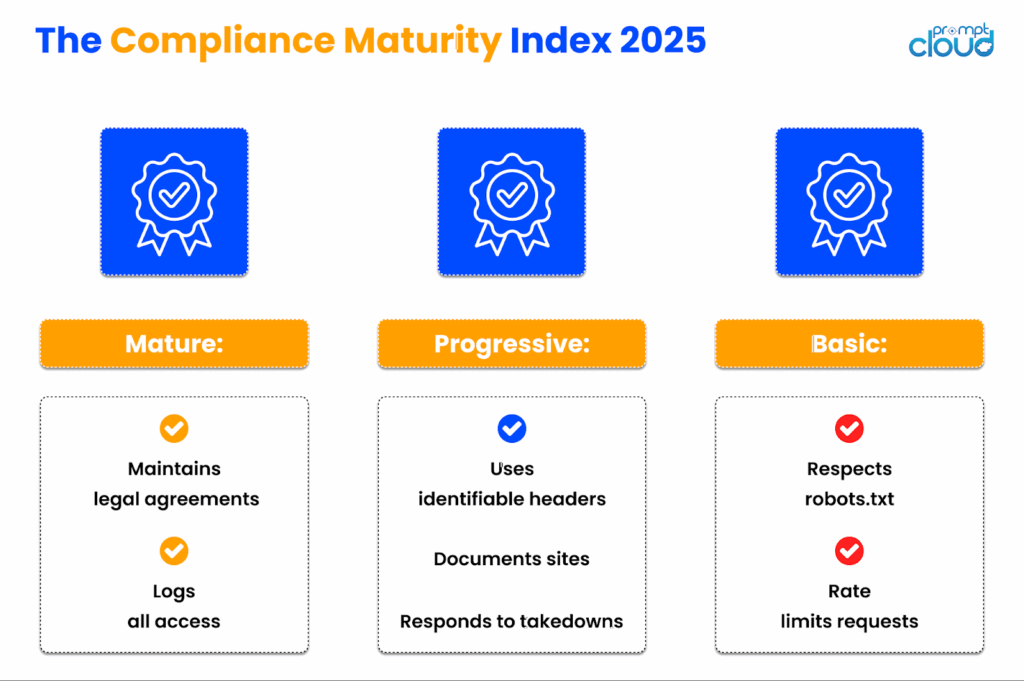
Figure 5: The three-tier compliance maturity model shows how data teams evolve from basic caution to transparent, audited partnerships.
The Price of Data: What It Really Costs to Scrape at Scale
On paper, scraping looks inexpensive. You write a script, host it on a server, and let it run. Easy. But anyone who has done it at scale knows that the real costs start showing up later.
First come the technical expenses.
Rotating proxies, residential IPs, headless browsers, and anti-bot solutions each add layers of overhead. A single misconfigured setting can double your bandwidth bills or trigger mass blocks across your IP pool. Then there is storage, retry logic, and load balancing. These costs pile up quietly, and by the end of the month, the “simple script” looks more like a small cloud platform.
Next come the hidden costs.
Site structures change without warning. Layouts break. Selectors fail. Someone has to monitor, fix, and redeploy constantly. Each interruption costs time, data, and credibility. In enterprise contexts, even a few hours of downtime can mean thousands of missed records.
Finally, there are people’s costs.
No matter how automated the system becomes, humans still play a key role in validation. Someone must check if the data looks right, if dates align, if currency symbols are consistent, and if the extraction logic still matches the schema. Human-in-the-loop quality assurance might sound old-fashioned, but it is the only reliable defense against silent data drift.
At this point, the conversation usually turns toward “build versus buy.”Building offers control, but the operational drag grows fast. Buying from a managed service offers predictability, but it trades customization for stability. Most mature data teams end up mixing both, maintaining small in-house crawlers for niche needs while outsourcing everything that demands volume or uptime guarantees.
The important lesson is this: scraping is no longer a one-time investment. It is an ongoing operation with maintenance, monitoring, and compliance costs that scale along with your ambitions. Data might look free on the surface, but in practice, it behaves like infrastructure. You must maintain it, patch it, and keep it alive.

Figure 6: A comparison of DIY versus managed scraping reveals that cost efficiency comes from smarter, not cheaper, scaling.
The Quality Battle: Accuracy, Freshness, and Human QA
It is easy to scrape a website. It is much harder to know whether the data you scraped is actually right.
Most scraping projects fail quietly, not because of missing data, but because of bad data that goes unnoticed. A wrong price, a mismatched date, or a missing field might seem small, yet at scale it can distort entire analyses. A model trained on half-correct data will still make predictions, but they will be wrong with confidence.
Data quality begins with accuracy, but that is only the surface. In 2025, the real measure of scraping success includes three pillars: accuracy, freshness, and consistency.
- Accuracy means the numbers and text you extract match the source exactly.
- Freshness means the data reflects the web as it exists right now, not last week.
- Consistency means the format and schema remain stable, so your downstream systems never break.
Maintaining those pillars requires both automation and people. Automated validation can check schemas, detect nulls, and flag sudden volume spikes. But only human review can notice when a column header shifts meaning, or when an image no longer matches a product title. That is why even the most advanced data operations rely on human-in-loop validation. A quick daily sampling of scraped data catches errors before they turn into system-wide noise.
Freshness is becoming a competitive edge. With websites updating multiple times a day, static scrapes quickly lose value. Event-driven systems are solving this problem by triggering extraction when content changes, not by schedule. It is a smarter way to stay current without overloading servers or wasting bandwidth. In short, quality is not an outcome, it is a process. It must be measured, monitored, and refined constantly. Without that discipline, even the most expensive scraping setup becomes just another unreliable data feed.

Figure 7: Web data passes through multiple validation stages before becoming reliable, analysis-ready information.
To see how quality monitoring works in real production environments, you can read the Scraped Data Quality Playbook. It explains practical methods like schema validation, coverage checks, and freshness SLAs that keep datasets dependable over time.
Where the Action Is: Top Industries Using Scraping in 2025
Every year, a few new industries discover the power of structured web data. And every year, it changes how they compete.
In 2025, scraping has moved far beyond e-commerce and SEO monitoring. It now touches almost every digital-first business model. The difference lies in how each industry uses the data. Some rely on it to react faster, others to see trends before anyone else.
Let’s take a look at where the real action is.
Figure 8: From retail to real estate, nearly every modern industry now relies on structured web data for competitive visibility.
E-commerce and Retail
No surprise here. Pricing intelligence, assortment tracking, and product sentiment analysis are still the largest use cases. Retailers now scrape millions of SKUs daily to spot competitor price changes or missing inventory. Many track both product listings and reviews to detect brand perception shifts in real time.
Finance and Investment
Investors have embraced scraping under the banner of “alternative data.” Market sentiment from social media, job postings, or product reviews often signals shifts before earnings reports do. Funds use web data to detect hiring surges, supply shortages, or executive changes across portfolios.
Travel and Hospitality
Airlines, hotel chains, and aggregators monitor fares, occupancy, and dynamic pricing across thousands of listings. Real-time visibility lets them adjust discounts or allocations before competitors do. Travel data scraping has become so common that rate parity monitoring is now considered an industry standard.
Real Estate
Developers and housing platforms track property availability, rental price fluctuations, and regional demand indicators. The goal is simple: identify growth zones faster than official reports can. Web data often reveals market trends weeks ahead of published statistics.
AI and Technology
This is the fastest-growing segment. AI models, recommendation systems, and agents all rely on continuously updated datasets. Companies collect training data from reviews, news sites, and product listings to make their systems more adaptive and context-aware. Each of these sectors uses web scraping differently, yet all depend on the same foundation: accurate, timely, and ethically gathered data. Without it, market visibility fades and decisions lag behind reality.
For a closer look at practical examples across industries, read Web Scraping for Real Estate Market Analysis. It breaks down how location data, listing frequency, and regional sentiment combine to predict demand more accurately than conventional surveys.
The Arms Race: Scrapers, Bots, and Browsers
The web has always been a game of adaptation. You build a scraper. The site changes its layout. You fix your code. The site adds a new bot filter.And the cycle repeats. In 2025, that cycle has turned into something bigger – a full-scale technological arms race between websites, security systems, and scraping tools.
Today, more than half of all internet traffic comes from non-human sources. Some of it is harmless, like search engine crawlers or uptime monitors. The rest includes scrapers, data harvesters, and automated agents trying to stay invisible. According to F5 Labs, bot traffic continues to rise across every sector, with e-commerce, ticketing, and travel platforms among the most targeted. As a response, websites are arming themselves with new defenses. Advanced anti-bot systems now analyze user behavior, cursor movement, and browser fingerprinting in real time. They look for patterns that hint at automation. Cloudflare’s latest updates go beyond simple blocks – they use AI to distinguish between legitimate crawlers and those acting without permission.

Figure 9: Human and automated traffic now share the web equally, forcing continuous evolution in both bot detection and scraping technology.
Scrapers, of course, are evolving too. Browser automation frameworks such as Playwright and Puppeteer can simulate realistic user behavior, from mouse movements to random scroll timing. Some teams even run scrapers on full headless browsers in distributed environments, blending in with normal user traffic.
This back-and-forth will not end soon. But what is becoming clear is that brute-force scraping is losing ground to intelligent scraping; systems that prioritize precision, respect site boundaries, and use smarter throttling rather than volume. A few years ago, success meant collecting more data than anyone else. Now, success means collecting it more carefully, staying compliant, and maintaining long-term reliability. The best scrapers no longer fight websites, they learn from them.
What’s Next: The Permission Economy of Web Data
The web is entering a new phase. A quieter, more deliberate one. After decades of open crawling, constant scraping, and invisible automation, 2025 marks the beginning of what many are calling the permission economy of web data. In this new world, access is no longer assumed; it is negotiated. You can already see the signs.
- Cloudflare now enforces AI bot restrictions by default.
- TollBit has built an entire marketplace for licensed data access.
- Publishers are embedding “machine-readable contracts” into their sites to declare how, when, and by whom their data can be used.
What started as polite robots.txt files is slowly turning into a global framework for digital consent.
That might sound restrictive, but it is actually healthy. The open web survives only when balance exists between creators and collectors.
- If scraping remains responsible and transparent, data owners will continue to allow it.
- If it becomes abusive, the door will close for everyone.
The next generation of scrapers will look less like stealth crawlers and more like verified agents authenticated programs with digital signatures that identify who they are and why they are visiting. APIs will merge with web interfaces. Sites will publish structured data feeds for licensed access. And companies that treat compliance as a design principle, not an afterthought, will thrive in this new environment.
What will not change is the demand. Businesses will still need live data to forecast trends, track pricing, and train AI models. What will change is the how. Data will move from being scraped to being exchanged. The web will remain open, but it will be governed by trust. Scraping is growing up, and so is the web. The next decade will not be about who can collect the most data, but about who can collect it responsibly, transparently, and in partnership with the people who create it.
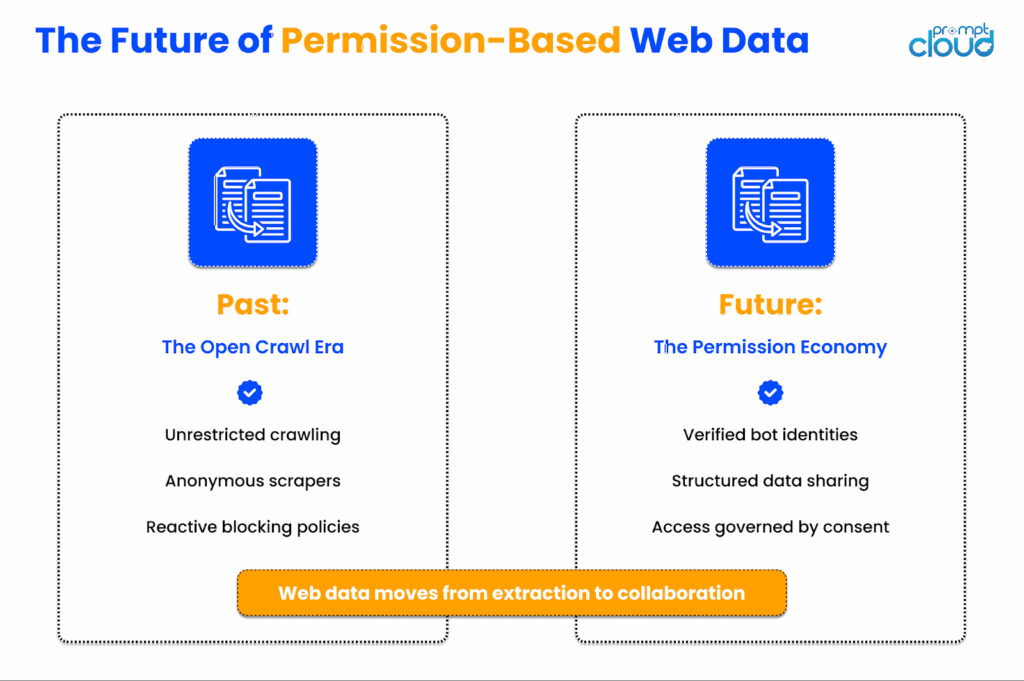
Figure 10: The web is shifting from unrestricted crawling to consent-based collaboration, where verified bots access structured data responsibly.
If you want to explore how event-driven systems and webhook-based feeds already reflect this new mindset, take a look at Pricing Intelligence 2.0: Event-Triggered Scrapers for Price and Availability Changes. It shows how modern data flows are moving toward cooperation, not confrontation.
Before we wrap up, it’s worth looking at the darker side of scraping – the part most reports skip over. Because while the web scraping industry grows in size and sophistication, something else is happening quietly beneath it: a surge in persistent, AI-powered bots that refuse to go away.
The Age of Persistent Scraper Bots
1. When Scraping Crosses the Line
According to F5 Labs’ 2025 Advanced Persistent Bot Report, 10.2% of all global web traffic now comes from scrapers, even after bot-mitigation systems are applied. In industries like fashion (53%), hospitality (49%), and healthcare (34%), scraping is no longer an occasional nuisance; it’s a constant force shaping competitive dynamics. The irony? Many of these same industries depend on scraping for competitive intelligence, price tracking, and sentiment analysis. It’s a mirror effect: the same technology that fuels innovation also creates exposure.
Where things start to blur is intent. Retailers scraping competitor listings for pricing parity aren’t committing cybercrime; they’re playing by the new data-driven rules of commerce. But large-scale extraction of copyrighted content, fare data, or financial rates often exceeding fair-use thresholds—pushes the boundary into what regulators now call “excessive automation.”
2. Industry Breakdown: Where Scraper Bots Hit Hardest
F5’s dataset, drawn from thousands of enterprise networks, reveals clear industry clusters:
| Industry | % of Web Traffic from Scrapers | Nature of Scraping |
| Fashion | 53.23% | Price, product image, and catalog scraping |
| Hospitality | 49.32% | Rate, availability, and review scraping |
| Healthcare | 34.47% | Drug pricing, medical publication, and insurance comparison |
| Airlines | 10.76% | Fare and seat availability scraping |
| Banking / Credit Unions | 7.73% (web), 4.17% (mobile) | Rate and product scraping |
| Insurance | 0.10% | High sophistication, low frequency |
What’s striking is how sophistication doesn’t correlate with volume. Insurance and banking see fewer scrapers overall, but they’re 99% “advanced” bots – custom-built, stealthy, API-aware agents that emulate real human behavior. Fashion and travel, meanwhile, are bombarded by cheap, mass-produced scrapers that rely on brute force rather than precision.
3. The Economics of Bot Scraping
Bot operators operate under simple economics: if the data is valuable enough, they’ll find a way in. F5’s analysis outlines three behavioral responses to mitigation:
- Go away: when effective mitigation exists, scrapers divert to weaker sites.
- Increase sophistication: they retool, mimicking user activity to bypass defences.
- Make no changes: in commoditized sectors (e.g., fashion), scrapers persist even when blocked because mass scraping yields value in aggregate.
This creates a stratified bot economy.
At the top: advanced, AI-guided crawlers that deploy fingerprint rotation, behavioral mimicry, and proxy chaining. At the bottom: simple HTTP curl scripts and no-code scrapers flooding retail domains. The middle layer – automated SaaS scraping APIs – represents the “legitimate” side of the same evolution.
4. Persistent Scrapers and the AI Feedback Loop
The rise of generative AI has multiplied scraping pressure. Every LLM or image model requires constant ingestion of new data. F5 highlights this feedback loop:
“Scrapers extract large amounts of data and content from their targets – well beyond what owners intend to provide.”
In short, AI has industrialized scraping. What used to be a single bot pulling a CSV is now a distributed mesh of autonomous agents collecting structured and unstructured content for model retraining. This “always-on” scraping behavior, termed Advanced Persistent Scraping (APS) by researchers, mirrors the persistence of cyber-threat actors. It’s not malicious in the traditional sense, but it’s relentless.
5. Web vs Mobile APIs: The New Frontline
While web endpoints remain the main target (17.6% automation on average), mobile APIs are the new frontier.
- Hospitality leads with 4.53% of all mobile API traffic coming from scrapers.
- Banks and credit unions face the most advanced attacks, with 99.24% of mobile API scrapers classified as “advanced.” These bots often mimic app requests to extract rates, branch data, or customer offers – information meant for authenticated users.
Mobile scraping requires higher technical investment, but its reward – access to structured, authenticated data feeds – makes it increasingly attractive. Expect to see the next generation of scrapers move from browser farms to device farms, where simulated smartphones conduct parallel, human-like scraping operations.
6. The Counter-Evolution: Anti-Bot Innovation
Every escalation spawns a countermeasure. Between 2022 and 2025, the number of commercial bot-management and anti-scraping services identified by Wappalyzer jumped from 36 to 60. The major players – Cloudflare, Akamai, Imperva, and hCaptcha – remain dominant, but new entrants like Sucuri and Distil have expanded the defensive ecosystem.
Emerging technologies include:
- Mouse movement intelligence: behavioral analysis to detect unnatural pointer patterns.
- SSL pinning and encrypted mobile APIs: block packet inspection and data interception.
- Dynamic protocol adoption (WebSocket, gRPC): obfuscates data exchanges.
- Adaptive CAPTCHAs: test micro-delays and sequence variance to distinguish bots.
Yet, even as defenses grow, so does stealth. The most advanced scrapers now incorporate reinforcement learning to “learn” avoidance patterns, adjusting request timing and fingerprint attributes dynamically.
7. Why This Matters for the Scraping Industry
The F5 findings change the tone of the broader web scraping market reports (Apify, Zyte, Mordor, ScrapeOps). While those analyses celebrate growth—CAGR between 13–18% and global market size over $2B by 2030 – F5 exposes the other side: operational friction and reputational risk.
Persistent scraper bots are driving up infrastructure costs (proxies, CAPTCHA solvers, compute) and pushing compliant scraping firms to adopt ethical throttling, verified bot IDs, and transparent reporting.
In effect, the cost of legitimacy has risen sharply. F5’s numbers also explain why major enterprises are consolidating toward managed providers: rather than risk being blacklisted or litigated, they prefer contracted data access under security audits and consent frameworks.
This is exactly why the industry is shifting from “data extraction” to “data partnership.”
8. Advanced Persistent Bots as Market Pressure
Think of scraper bots as both a symptom and driver of web transformation. The 2025 data economy operates under three realities:
- Public content will always attract automated demand. As long as price, product, or sentiment data exist, someone will try to harvest it.
- Anti-bot systems will continue to escalate. CAPTCHAs, tokenized sessions, and per-request signatures are now default.
- The line between good and bad bots is context, not code. The same crawler can serve academic research or competitive espionage depending on intent.
This tension has forced a moral and economic sorting of the web scraping ecosystem. Firms investing in responsible, authenticated scraping pipelines – those aligned with data rights, consent, and throttling norms – are setting the new baseline for acceptable automation.
9. From Arms Race to Regulatory Trigger
The Advanced Persistent Bot Report reads like a warning flare for policymakers. If nearly half of web traffic is non-human and 10% of it is extractive, regulators will eventually intervene. Already, Europe’s AI Act and the U.S. FTC’s draft data access guidelines are circling the question of “automated collection for model training.” Expect the next two years to introduce:
- Bot disclosure mandates (digital identification for crawlers).
- Rate-limit governance tied to fair use.
- Data-sharing exchanges where websites offer verified feeds to registered crawlers.
In other words, today’s anti-bot arms race could evolve into tomorrow’s compliance infrastructure.
10. Lessons from Competitor Benchmarks
Pulling insights from Apify, Zyte, and ScrapeOps’ 2025 reports, one trend aligns perfectly with F5’s warning: the convergence of scraping, security, and compliance into a single operational domain.
| Theme | Industry Trend (2025) | Implication |
| AI-driven extraction | Scrapers now adapt to dynamic pages via ML | Anti-bot systems adopt ML too, creating symmetry |
| Cloud migration | 68% of scraping now cloud-hosted | Centralizes detection and blocking patterns |
| API dependency | API deprecation driving HTML scraping resurgence | Raises legal ambiguity and technical pressure |
| Compliance spend | Up 86% YoY across major firms | Ethical scraping becomes a competitive differentiator |
The result is a bifurcation of the market: low-cost bot operators running semi-legal scraping clusters versus enterprise-grade providers investing in identity, logging, and consent architecture.
11. The Next Frontier: Scraping in a Bot-Saturated Internet
By late 2025, the open web resembles a chessboard of defenses and counter-moves. Cloudflare’s “One-Click-Nuke” initiative allows website admins to block entire bot networks at once, while adaptive scrapers use synthetic browsers to reappear within minutes. In parallel, mobile apps – once thought safe – are being reverse-engineered with code obfuscation breakers and API emulators.
The takeaway is not that scraping will die. It will mature, becoming more formalized, federated, and traceable.The next generation of data collection will hinge on trust tokens, crawler identity headers, and transparent logging that allows data owners to verify how their information is being used.
In that sense, the “Advanced Persistent Bot” era isn’t just a security story—it’s the final push that will force the industry to professionalize.
Summary
The F5 Labs report reframes the narrative: scraping is no longer a technical challenge; it’s a geopolitical, regulatory, and ethical one. As anti-bot innovation accelerates, legitimate web data providers will survive by moving toward verified identity, transparent consent, and compliance-grade automation. The scraper wars of 2025 are not about who can extract the most data, they’re about who can keep doing it legally, sustainably, and without breaking the web in the process.
Conclusion
If there is one truth the past decade of web scraping has taught us, it is that the internet never stands still. The scripts, tools, and techniques that once defined this craft have evolved into global data pipelines that fuel entire industries. What began as experimentation has become infrastructure.
In 2025, scraping is no longer a background process hidden behind dashboards. It is a visible and regulated layer of the digital economy. Every price change, review, or product update travels through a network of ethical checks, event triggers, and AI-driven decisions before becoming usable insight. The old question of “Can you collect it?” has quietly given way to “Can you collect it responsibly?”
This shift marks the beginning of a new social contract between data owners and data consumers. Websites will continue to publish, machines will continue to read, and both will need each other to survive. The balance will not be decided by legislation alone but by the trust built between those who create content and those who transform it into intelligence.
The next phase of web scraping will be quieter, smarter, and far more intentional. It will be defined not by the scale of data extracted but by the quality of relationships maintained. Companies that build transparent systems, honor consent, and maintain accuracy will not just comply with the future of the web; they will help shape it.
Scraping is growing up. The web is growing up with it. And for those who understand both the power and the responsibility of real-time data, the next decade is full of opportunity.
Ready to turn insights into action?
Want proxy rotation that stays stable across regions and traffic spikes?
FAQs
1. What is the State of Web Scraping 2025 report about?
It is a comprehensive industry analysis that explores how web scraping has evolved in 2025 – covering new technologies, compliance trends, AI-driven scraping, and the growing role of event-driven data pipelines.
2. How big is the global web scraping market in 2025?
According to Mordor Intelligence and other analysts, the market is valued between USD 1 billion and USD 1.1 billion in 2025, with projections exceeding USD 2 billion by 2030.
3. What are the latest web scraping trends for 2025?
Key trends include event-driven scraping, AI-assisted data extraction, real-time pipelines, stricter compliance policies, and the rise of verified, permission-based crawlers.
4. How is AI changing web scraping?
AI now powers selector repair, dynamic page handling, and intelligent scheduling. At the same time, large language models depend on web data for training, creating a feedback loop between scraping and AI development.
5. Why is web scraping compliance so important in 2025?
Because new rules from platforms, security providers, and regulators require transparent, permission-based access to data. Compliance ensures scrapers remain ethical, legal, and sustainable.
6. What industries benefit most from web scraping in 2025?
E-commerce, finance, travel, real estate, and AI technology lead adoption. Each uses web data for pricing intelligence, trend tracking, or training models.
7. What are advanced persistent scraper bots?
These are highly sophisticated, AI-driven bots that continuously harvest data while adapting to anti-bot defenses. F5 Labs reports they now account for more than 10 percent of all global web traffic.
8. How can businesses protect their websites from persistent scraper bots?
By using layered defenses such as behavioral analysis, CAPTCHA variation, SSL pinning, and verified bot identification. Balancing protection with legitimate crawler access is key.
9. What is event-driven scraping and why is it popular?
Event-driven scraping activates only when a page changes, delivering real-time data with fewer redundant requests. It reduces costs and improves data freshness compared to scheduled crawling.
10. What does the future of web scraping look like?
The industry is moving toward a permission economy where verified agents, digital trust tokens, and transparent data exchange replace unrestricted crawling. The focus shifts from extraction to collaboration.















