




**TL;DR**
Privacy safe scraping is about designing data pipelines that automatically protect personal information before it spreads. Instead of fixing privacy risks after data is collected, teams use PII masking and anonymization inside secure pipelines so web data stays usable without exposing identities.
What is Privacy Safety and PII Masking?
Most data privacy problems do not start with bad intent. They start with pipelines that were never designed to protect people in the first place.
A crawler pulls web data. A parser structures it. A dataset lands in storage. Everything looks clean and functional. Then someone notices names, emails, usernames, or location hints sitting quietly inside the data. By the time that realization hits, the data has already moved through systems, dashboards, and models.
That is where privacy safe scraping becomes necessary.
Privacy safe scraping is not a tool or a checkbox. It is a way of building pipelines so personal data never becomes a liability. Instead of collecting everything and deciding later, secure pipelines limit exposure by design. Sensitive fields are masked early. Identifiers are transformed or removed before storage. Anonymization happens before reuse, not after complaints. PII masking plays a central role here, but it is often misunderstood. Masking is not just hiding values with asterisks. It is a controlled transformation that preserves usefulness while reducing risk. When done inside secure pipelines, it allows teams to analyze trends, patterns, and signals without tying them back to individuals.
This matters because web data is no longer used in isolation. It feeds analytics, compliance checks, competitive intelligence, and AI systems. Once personal data leaks into those workflows, cleaning it up becomes painful and expensive.
This article is written for teams that want to avoid that situation entirely. We will break down what privacy-safe pipelines actually are, how PII masking fits into them, where anonymization succeeds and fails, and why secure pipelines are becoming the default expectation for modern web data systems.
Many organizations begin web scraping with internal scripts, but maintaining crawler infrastructure, handling anti-bot protections, and monitoring data quality quickly becomes a full-time operational task.
Why Traditional Scraping Pipelines Fail at Privacy
Most scraping pipelines were never built with privacy in mind. They were built for speed, coverage, and scale. Privacy came later. As a patch.
They collect first and think later
The default pattern looks harmless.
- Crawl everything.
- Store everything.
- Decide what to use later.
This works fine until personal data slips in. And it almost always does. Names in reviews. Emails in contact pages. Usernames in forums. Location hints buried in text. None of these feel dangerous individually. Together, they form identity. Traditional pipelines treat this as a cleanup problem. Mask it later. Filter downstream. Delete when asked. By then, the damage is already done. Privacy safe scraping flips this logic. It assumes sensitive data will appear and designs the pipeline to handle it before it spreads.
Masking happens too late
In many systems, PII masking is applied after storage.
That means raw data sits somewhere, even briefly. In logs. In backups. In temporary tables. In debug exports. From a privacy standpoint, that window matters. Secure pipelines apply masking at ingestion or transformation, not after analytics teams have already accessed the data. Once raw personal data is written, it becomes harder to track, harder to delete, and harder to explain.
Anonymization is treated as a checkbox
Another failure point is shallow anonymization.
Replacing names with hashes feels safe. It often is not. If the same hash appears across datasets, identity can still be inferred. If timestamps, locations, or behavioral patterns remain intact, re-identification becomes possible. Traditional pipelines rarely test for this. They assume anonymization works because a function ran. Privacy safe scraping treats anonymization as a risk reduction strategy, not a guarantee. It evaluates combinations of fields, not just individual ones.
Pipelines optimize for reuse, not restraint
Scraping pipelines are usually designed to maximize reuse.
Once data exists, it flows everywhere. Dashboards. Exports. AI training. Internal tools. External sharing. Each reuse amplifies privacy risk. Secure pipelines introduce friction intentionally. Purpose limits. Field-level controls. Context tags. Data collected for one reason does not automatically become available for another. This feels restrictive until the first audit or legal review. Then it feels necessary.
Why these failures keep repeating
The uncomfortable truth is that privacy failures are invisible at first.
Systems work. Metrics improve. No alarms go off. Problems appear later, when someone asks hard questions. Where did this data come from? Why do we have this field? Who accessed it? Can we delete it everywhere? Traditional pipelines struggle to answer those questions because they were never designed to. Privacy safe scraping exists to prevent that moment.
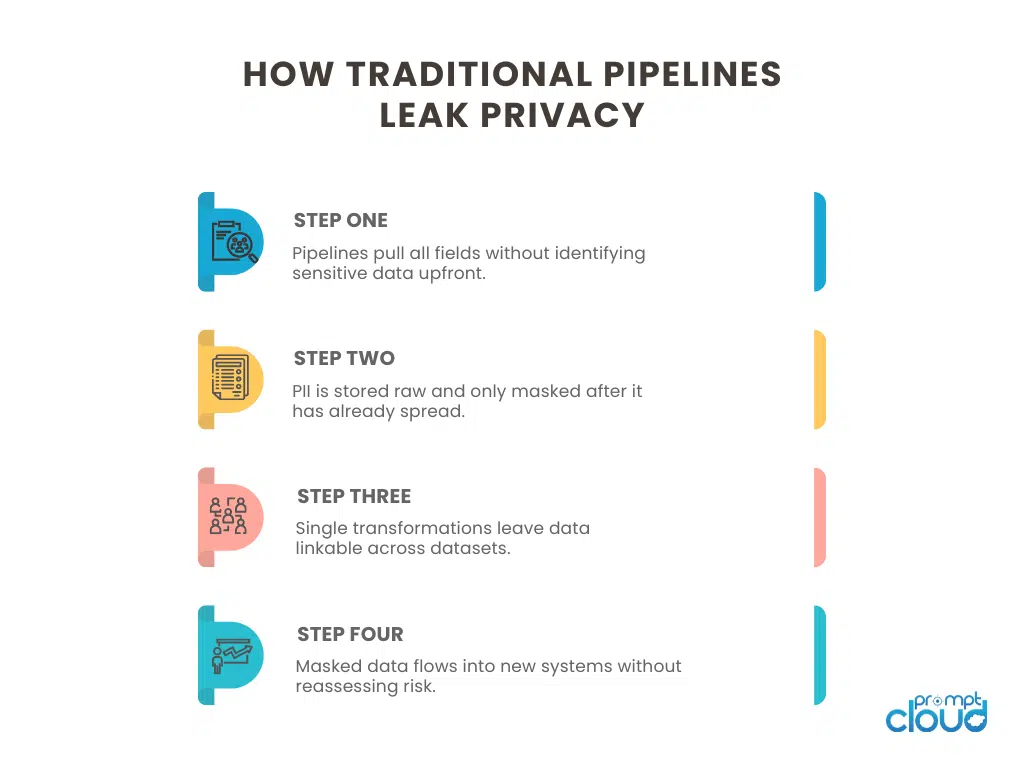
Figure 2: Common points where non-privacy-safe pipelines expose personal data through late masking and uncontrolled reuse.
What Makes a Pipeline Privacy-Safe by Design
Privacy-safe pipelines do not rely on cleanup, intent, or best-effort controls. They are structured so sensitive data never gets comfortable inside the system. That difference shows up in a few very specific design choices.
Mask before storage, not after use
The most important shift is timing. In privacy safe scraping, PII masking happens before data is written to long-term storage. Not after dashboards are built. Not after models are trained. Right at ingestion or during the first controlled transformation. That way, raw identifiers never spread across logs, backups, or downstream systems. Even if something breaks later, exposure is already limited. This is what turns privacy from a policy into an engineering property.
Treat fields as risk, not just schema
Traditional pipelines think in schemas. Columns, types, formats. Privacy-safe pipelines think in risk categories. The name field is obvious. But a username might be risky too. A timestamp alone is fine, until it is combined with location. Free-text fields are especially dangerous because personal data hides where you least expect it. Secure pipelines classify fields by sensitivity and apply controls accordingly. Some fields are masked. Some are generalized. Some are dropped entirely. And those decisions are explicit, not accidental.
Purpose is encoded, not assumed
One of the quiet strengths of privacy-safe pipelines is purpose limitation. Data is collected for a reason, and that reason is encoded into the pipeline. When someone wants to reuse the data for a new purpose, the system does not silently allow it. It forces a decision. This is how privacy safe scraping avoids the “we already had the data” trap. Purpose tags, routing rules, and access controls make sure anonymized data stays anonymized and scoped, even as use cases expand.
Anonymization is layered, not singular
There is no single anonymization technique that solves everything. Masking, hashing, tokenization, generalization. Each reduces risk in a different way. Privacy-safe pipelines layer these techniques based on context. For example, a pipeline might hash identifiers, generalize locations, and bucket timestamps. Individually, each step helps. Together, they dramatically reduce re-identification risk while keeping the data useful. This layered approach is what separates real anonymization from cosmetic changes.
Observability is part of privacy
You cannot protect what you cannot see. Privacy-safe pipelines log masking decisions, field exclusions, and transformations. They make it possible to answer simple but critical questions later. What data did we collect? What did we mask? Why does this field look the way it does? This matters for audits, but it also matters for engineering sanity. When behavior is visible, mistakes are easier to catch early.
Why this design holds up under pressure
These design choices are not theoretical. They show up when something goes wrong. A complaint. A review. A legal question. A client audit. Teams with privacy-safe pipelines do not scramble. They explain. They show controls. They demonstrate intent and execution lining up. That is the real test of privacy safe scraping. Not whether a pipeline runs, but whether it can stand up to scrutiny.
Figure 1: A step-by-step view of how privacy-safe pipelines identify, transform, and govern sensitive data from ingestion onward.
PII Masking vs Anonymization: Where Teams Get Confused
This confusion shows up in almost every technical discussion around privacy safe scraping. Teams say “it’s anonymized” when they mean “we hid the obvious parts.” Regulators, auditors, and security teams mean something very different.
Let’s separate the two properly.
Masking and anonymization are not the same thing
| Aspect | PII Masking | Anonymization |
| Primary goal | Reduce exposure | Prevent re-identification |
| Reversible | Often yes | No, by design |
| Typical use | Logs, analytics, internal datasets | Public sharing, AI training, long-term storage |
| Identity risk | Reduced but present | Minimized to reasonable levels |
| Works alone | No | Only when layered correctly |
| Common mistake | Treated as “privacy done” | Assumed without testing |
Masking is a control. Anonymization is a privacy outcome. Privacy safe scraping usually uses both, but at different stages and for different reasons.
Why masking alone is rarely enough
Masking hides values. It does not break relationships. If the same email hash appears across multiple datasets, identity can still be inferred. If usernames are masked but timestamps and locations remain precise, re-identification becomes likely. This is why secure pipelines never rely on a single transformation.
Practical masking examples (early pipeline)
Below are examples of field-level masking that should happen at ingestion.
Email masking
def mask_email(email):
if not email or “@” not in email:
return None
local, domain = email.split(“@”)
return f”{local[:2]}***@{domain}”
Used when:
- Emails appear in scraped text
- The domain is useful, but the identity is not
Username tokenization
import hashlib
def tokenize_username(username, salt):
return hashlib.sha256(f”{salt}{username}”.encode()).hexdigest()
Used when:
- You need stable joins inside one dataset
- You do not want reversibility across systems
Key rule: rotate salts per pipeline or client, not globally.
Anonymization requires combinations, not tricks
True anonymization focuses on reducing linkage, not hiding characters. Example strategy for scraped review data:
- Hash reviewer identifiers
- Bucket timestamps to day or week
- Generalize location from city to region
- Drop rare attributes that create uniqueness
Timestamp generalization
from datetime import datetime
def bucket_timestamp(ts):
return datetime(ts.year, ts.month, ts.day)
This removes precision that enables tracking while preserving trends.
Testing for re-identification risk
One mistake teams make is never testing anonymization outcomes. A simple sanity check:
- Count unique combinations of quasi-identifiers
- Flag rows that remain unique after transformation
If uniqueness remains high, anonymization is not working. Privacy safe scraping treats anonymization as an engineering problem, not a legal checkbox.
Where this fits into secure pipelines
Masking happens before storage. Anonymization happens before reuse or sharing. Both are logged. Both are deliberate. This layered approach is what allows pipelines to stay useful while staying defensible.
How Secure Pipelines Enforce Privacy at Scale
Designing a privacy-safe pipeline is one thing. Keeping it effective as volume, velocity, and use cases grow is another. This is where many systems quietly regress.
Privacy controls must be automatic, not optional
At small scale, teams rely on discipline. At large scale, discipline fails.
Secure pipelines enforce privacy through automation, not convention. Masking rules are part of ingestion. Anonymization steps are embedded in transformations. Access controls are applied by default. No one needs to remember to “turn privacy on.” It is already on. This is especially important in privacy safe scraping, where data sources change frequently and new fields appear without warning.
Field-level governance scales better than dataset rules
One of the most effective patterns is field-level control.
Instead of labeling an entire dataset as sensitive, secure pipelines classify individual fields. Each field carries metadata about sensitivity, allowed uses, and retention. That allows the same dataset to support multiple use cases without leaking risk. Analytics can access aggregated signals. Models can use anonymized features. Raw identifiers never leave controlled boundaries. This approach is far more scalable than duplicating datasets for every use case.
Privacy enforcement travels with the data
In weak systems, privacy controls stop at the pipeline boundary. In secure pipelines, privacy travels with the data.
Masked fields stay masked. Purpose tags remain attached. Retention rules follow copies and derivatives. When data moves, its constraints move too. This is what prevents accidental exposure when datasets are exported, shared internally, or reused months later. If you want a broader view of how compliance and data quality intersect in these systems, this piece on web scraping compliance and data quality shows how privacy controls become part of overall pipeline health.
Scaling without losing restraint
As pipelines grow, pressure builds to relax controls. More speed. More coverage. More reuse. Secure pipelines resist that pressure by making restraint cheaper than risk. When privacy is automated, the cost of doing the right thing is low. The cost of bypassing it is high. That is the real scaling advantage.
When privacy becomes invisible in a good way
The best privacy-safe pipelines do not feel restrictive day to day. Engineers build features. Analysts query data. Product’s ship. Privacy is handled quietly, consistently, and predictably. Problems only surface when controls are missing. That invisibility is not neglect. It is a sign that privacy has been engineered properly.
How Privacy-Safe Pipelines Support Legal and Regulatory Compliance
Most teams approach regulations backwards. They start with laws, then try to retrofit systems to match them. That almost always leads to brittle controls and endless exceptions. Privacy-safe pipelines take the opposite approach. They design for restraint first, and legal compliance becomes a natural outcome.
Regulations care about outcomes, not intentions
Whether it is GDPR, CCPA, or regional privacy laws, regulators rarely ask what you meant to do. They ask what actually happened.
- What data did you collect?
- What personal information was stored.
- Who could access it?
- How long it stayed in the system. Whether it could be deleted or corrected.
Secure pipelines make these questions answerable because they control exposure at the technical level. PII masking reduces the amount of personal data collected in the first place. Anonymization limits downstream risk. Purpose and retention rules prevent uncontrolled reuse. This aligns well with regulatory expectations without having to hard-code legal language into engineering workflows.
Lawful data collection becomes provable
One of the hardest compliance problems is proof.
Teams often believe they are compliant, but cannot demonstrate how. When data flows through multiple systems, explanations become fuzzy. Privacy-safe pipelines generate evidence as a side effect of normal operation. Masking decisions are logged. Field exclusions are recorded. Retention actions are automated and auditable.
When questions come, teams do not reconstruct history. They show it. This is especially relevant for web data collected at scale, where regulators increasingly expect organizations to demonstrate proactive safeguards rather than reactive cleanup. For a broader view of how global data laws intersect with automated data collection, this article on web scraping legality across jurisdictions provides useful context.
Regional differences matter less when pipelines are designed well
Different laws emphasize different things. Some focus on consent. Others on deletion rights. Others on data minimization. Privacy-safe pipelines handle this variability better than rule-based systems. Because sensitive data is minimized early, fewer regional differences matter downstream. Because retention is enforced automatically, deletion requests are easier to fulfill. Because access is scoped, internal misuse is harder. Good engineering reduces the surface area where legal interpretation becomes critical.
Compliance stops being a blocker
In poorly designed systems, compliance slows everything down. Reviews, approvals, exceptions. In privacy-safe pipelines, compliance fades into the background. New data sources are onboarded faster because controls already exist. New use cases are evaluated against existing rules instead of reinvented policies. This is why many teams find that investing in secure pipelines speeds them up over time instead of slowing them down.
Where Teams Overestimate Their Privacy Readiness
This is where confidence quietly turns into risk. Most teams believe they are privacy-ready because nothing has gone wrong yet. Pipelines are running. Clients are happy. No complaints have landed. That sense of safety is misleading. Privacy failures rarely announce themselves early.
The readiness gap
| Assumption teams make | What is actually happening | Why it becomes risky later |
| We mask PII, so we’re safe | Masking is partial and reversible | Re-identification remains possible across datasets |
| Personal data is rare in our sources | Free-text and edge fields contain PII | Exposure grows silently as volume increases |
| We only use the data internally | Internal reuse expands over time | Purpose drift breaks original privacy assumptions |
| Deletion is possible if needed | Raw data exists in logs and backups | Full deletion becomes impractical |
| Compliance checks happen during audits | Pipelines run unchecked day to day | Issues surface too late to fix cleanly |
| Our schema does not include PII | Derived fields still reveal identity | Privacy risk shifts instead of disappearing |
| One anonymization pass is enough | Context changes over time | Old data becomes risky in new combinations |
What stands out is that none of these assumptions are reckless. They sound reasonable. They are often true at a small scale. The problem is that privacy risks compounds.
Scale changes the meaning of safe
At low volume, privacy gaps are manageable. At scale, the same gaps become systemic. A single masked identifier might be fine. Millions of them across time, locations, and behaviors create patterns. Patterns lead to inference. Inference leads to exposure. Privacy-safe pipelines account for this by treating readiness as a moving target. Controls are revisited. Transformations are reviewed. Old data is reassessed against new use cases. Teams that skip this step usually do not notice the risk until someone external does.
Readiness is about friction, not features
One of the clearest signs of overconfidence is frictionless reuse. If data flows effortlessly into every new product, dashboard, or model, privacy controls are probably too loose. Healthy pipelines introduce just enough friction to force conscious decisions. That friction is not inefficiency. It is governance showing up at the right moment.
Why this matters before something breaks
Once a privacy issue surfaces publicly or legally, the conversation changes. The question is no longer whether controls exist. It is whether they existed before the problem. Privacy-safe scraping is about being able to answer that question honestly.
A More Durable Way to Handle Privacy
Most teams do not set out to mishandle personal data. They inherit pipelines that were built for speed, reuse, and flexibility, and then try to add privacy on top.
That order rarely works.
Privacy-safe pipelines flip the sequence. They assume personal data will appear. They assume it will show up in places no one planned for. And they assume that once data moves, it is hard to pull back. PII masking and anonymization are not defensive measures in this model. They are structural ones. They decide what data is allowed to exist inside the system at all. Secure pipelines enforce those decisions automatically, quietly, and consistently.
This is why privacy safe scraping is less about individual techniques and more about pipeline behavior. When masking happens early, exposure shrinks. When anonymization is layered, inference risk drops. When purpose and retention are encoded, reuse becomes intentional instead of accidental. The strongest signal that a pipeline is privacy-safe is not a policy document. It is how boring privacy becomes day to day. Data arrives already transformed. Analysts never see raw identifiers. Engineers do not debate what should be hidden because the system already knows.
When questions come later, and they always do, the answers are already there. Not reconstructed. Not guessed. Recorded. That is what holds up under audits, client reviews, and regulatory scrutiny. Not perfect privacy, but explainable privacy. If your pipelines are growing in volume, complexity, or downstream use, this approach stops being optional. It becomes the only way to scale without carrying invisible risk forward.
If you want to know more, read our two articles on:
- Privacy-safe pipelines align closely with expectations around data minimization and protection described in GDPR compliance for web data collection, especially when personal data appears in automated workflows.
- Many privacy issues surface even before PII masking begins, particularly when crawling behavior ignores intent signals discussed in robots.txt and scraping compliance.
- EDPB guidance on anonymisation and pseudonymisation – European Data Protection Board (EDPB)
Many organizations begin web scraping with internal scripts, but maintaining crawler infrastructure, handling anti-bot protections, and monitoring data quality quickly becomes a full-time operational task.
FAQs
What is privacy safe scraping?
Privacy safe scraping is the practice of designing data pipelines that protect personal information by default. It relies on early masking, anonymization, and controlled reuse instead of post-collection cleanup.
Is PII masking the same as anonymization?
No. Masking reduces exposure but can be reversible. Anonymization aims to prevent re-identification and usually requires multiple transformations working together.
Where should PII masking happen in a pipeline?
As early as possible. Ideally at ingestion or during the first controlled transformation, before data is written to long-term storage or logs.
Can anonymized data still create privacy risk?
Yes. If combinations of fields remain unique or linkable, re-identification is possible. This is why anonymization must be tested, not assumed.
How do privacy-safe pipelines help with compliance?
They minimize personal data exposure, enforce purpose and retention automatically, and generate evidence of how data was handled, which simplifies audits and reviews.















