



Our previous update was about easing the data delivery process by providing the option to download data directly from CrawlBoard. This update is yet another step in data accessibility improvement — now you’ll be able to merge the data available in API into fewer files and download the files directly in unzipped/zipped format apart from deduplicating the records.
We also understand the importance of recency in a highly dynamic and fast-paced web data ecosystem. Hence, this update comes with same-day crawl scheduling capability which can be easily triggered from your end.
Data merging
As mentioned above, this feature allows you to merge the extracted data available for different sites for a certain time period and get them uploaded. In case you consume data via API, it will be available in the folder ‘post_upload_merged_files_ignore_billing’ which can be accessed by adding the following parameter:
`&folder=post_upload_merged_files_ignore_billing`. However, if you have opted for file upload to your FTP server or any of the cloud storage solutions, then the merged data will be available on your server.
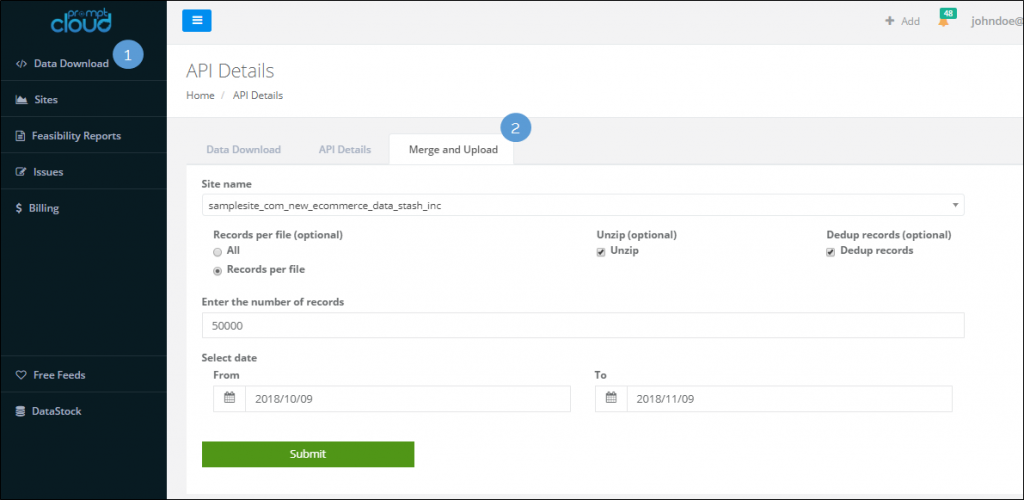
As you can see, accessing this section is quite straightforward – click on “Data Download” in the left sidebar and open up the “Merge and Upload” tab. Now, follow the step given below:
- Select the site for which data needs to be merged.
- Select whether you’d need all the records in a single file or breakdown the files based on a certain number of records.
- Select whether you need to access a zipped file or an unzipped file.
- Select the deduplication option if you only need unique records.
- Finally, select the date range and click on submit.
Note that based on the data volume, the whole process would take approximately 5 to 30 minutes.
Same-day crawl scheduling
Although we already had a crawl scheduling option (accessible from the “Sites” link in the left sidebar), the ability to initiate crawl on the same day was not available. With this update, you can initiate same-day crawls and it will be picked up by our system within an hour or two.
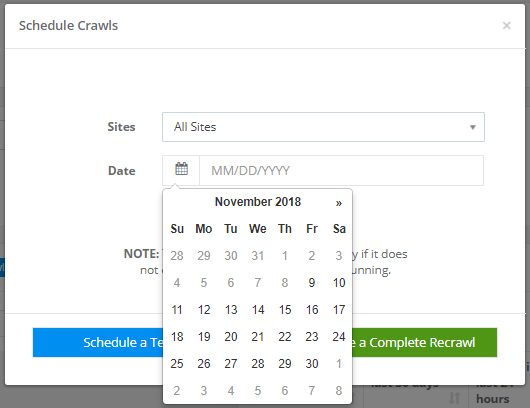
We’re super excited to launch these improvements — try them out and send us your feedback and suggestions.
Happy data crunching!
















