




**TL;DR**
Instant Data Scraper 2025 edition – This guide compares DIY scraping tools like Instant Data Scraper with managed web scraping services that handle retries, QA, deduplication, and delivery. Use this breakdown to decide when it’s time to stop building—and start scaling.
What Is Instant Data Scraper (and What It’s Built For)?
Instant Data Scraper is a lightweight Chrome add‑on that pulls tables off a page without any code. It’s the go‑to for quick jobs—think marketers grabbing a list of products, researchers exporting a directory, or anyone who needs a price table in a hurry. You install it, hit the button, and it guesses the repeating blocks on the page (rows, cards), then spits out a CSV. When it clicks, it feels effortless.
But it also hits a ceiling. Extensions like this are great for one‑offs; they don’t handle scale, flaky pages, or the guardrails you need for dependable data.
What It Does Well (And Why It’s Popular)
| Feature | Instant Data Scraper |
| No-code usage | ✅ Point-and-click UI |
| Auto-detects rows/cards | ✅ Good for simple list pages |
| Export to CSV instantly | ✅ Direct download |
| Pagination support | ✅ Auto-next-page loop |
| Works inside browser | ✅ Easy install, no setup |
Use cases it shines at:
- Scraping one page of job listings or product specs
- Exporting contact directories or event tables
- Pulling property listings or leads for quick research
Want expert‑built scraping support?
Building a crawler proves extraction is possible. Keeping it reliable at scale requires infrastructure, monitoring, and continuous maintenance.
But It’s Not Built for Scale or Reliability
Instant Data Scraper isn’t designed for:
- Sites behind bot protection (Cloudflare, Akamai, etc.)
- Authenticated flows
- Real-time data syncing
- Quality assurance or schema enforcement
- Large-scale automation across 1000s of pages
If you need to monitor eCommerce listings daily, feed product data into AI models, or enforce delivery contracts—this is where DIY breaks.
The Real Limitations
- Runs only in your browser tab: No headless support, no server scheduling.
- No retry logic or proxy rotation: You’ll get blocked or rate-limited quickly.
- Zero field validation or deduplication: Risk of corrupt, incomplete, or repeated records.
- No structured delivery: You download CSVs manually; there’s no pipeline, schema control, or delivery endpoint.
- Can’t scale jobs or manage load: No task queues, no parallel scraping, no TTL, no backpressure control.
This isn’t a flaw—it’s just not what Instant Data Scraper was made for. It’s a lightweight, manual tool for quick extractions. The problem starts when people try to duct-tape it into a scraping “system.” That’s where a managed web scraping service comes in—automating the hard stuff like anti-bot mitigation, schema consistency, data validation, and delivery pipelines.
When DIY Scraping Starts to Break: 5 Red Flags
Instant Data Scraper and other DIY tools might work for a week. Maybe a month. But as soon as your scraping needs shift from “grab some rows” to “feed this data into an operational system”—things start to crack.
Watch for these 5 red flags that signal your DIY scraping setup is hitting its limit.
1. Frequent Bot Blocks or Captchas
If your browser-based tool starts failing or returning empty rows, it’s likely hitting anti-bot systems like Cloudflare, Akamai, or perimeter-based WAFs.
DIY tools don’t rotate IPs, change headers dynamically, or spoof devices. And they definitely can’t handle:
- JavaScript fingerprinting
- Behavioral detection
- CAPTCHA challenges (Google reCAPTCHA, hCaptcha)
Without advanced anti-bot mitigation, your success rate drops sharply—even if the tool itself seems functional. For practical anti‑ban tactics—rotating IPs, pacing requests, and handling geo walls—see our guide on how to use proxies for scalable scraping.
2. Output Quality Is Inconsistent
You scrape five pages. Three work fine. One is missing half the rows. One exported empty headers.
This is where the lack of QA gates and schema contracts bites you:
- No field validation (e.g., price = “N/A”)
- No deduplication logic
- No crawl timestamp or versioning
- No alert when selectors break or data changes
Instant scrapers just export what they find. If the site structure shifts subtly—or loads elements via JavaScript—you’re left with silent failures. Many teams hit silent failures from selector drift or missing QA gates. These enterprise scraping mistakes and fixes will save you from bad rows and broken feeds.
3. It’s Taking Up More of Your Time
If you’re spending weekends refreshing pages, rerunning exports, or writing cleanup scripts—you’ve moved from “quick scrape” to ongoing maintenance burden.
That time cost compounds quickly:
- Fixing broken selectors after site updates
- Manually handling pagination or infinite scroll
- Checking for duplicates
- Re-uploading files to another system
You’ve built yourself a part-time job. That’s when it’s time to ask: Why not hand this off?
4. You Need Reliable Delivery (Not Just Download Links)
When data needs to be consumed by:
- A product analytics pipeline
- A data warehouse
- A machine learning model
- An internal dashboard
- A client deliverable
—you can’t afford to click “Download CSV” anymore.
You need structured delivery:
- Timestamped files in S3
- API access with retry support
- Streaming into a queue
- JSON/CSV that’s schema-aligned, deduped, and QA’d
DIY tools can’t provide delivery SLAs. And they can’t alert you when something fails.
5. Your Use Case Involves Scale or Frequency
If you’re scraping:
- 1,000+ URLs
- Multiple domains
- Pages with rotating content
- Price or job listings that update daily
You’ll need:
- Proxy rotation (residential, geo-targeted, mobile)
- Retry logic (auto-escalate on failure)
- Concurrency controls (to avoid rate limits)
- Job queues + TTL (don’t re-scrape stale tasks)
DIY tools don’t have queues, TTLs, or backpressure. They don’t batch requests or throttle intelligently. They just run—until they don’t.
Lifecycle of a Web Scraping Decision: Build vs Buy
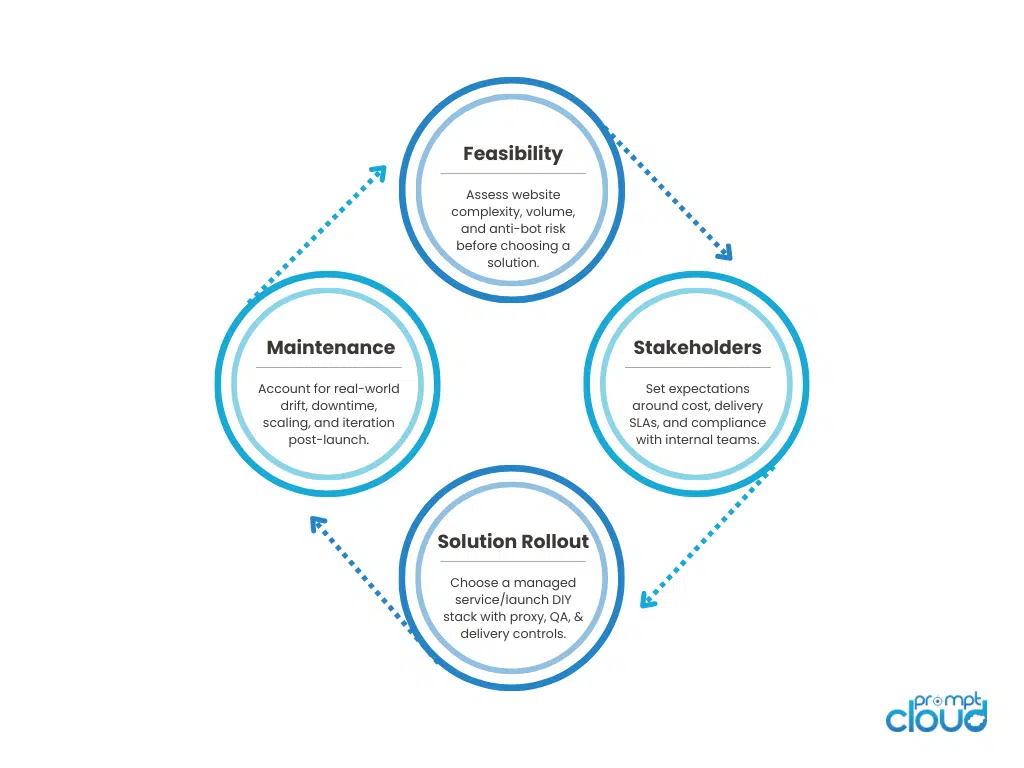
Instant Data Scraper vs Managed Scraping Services (Full Comparison 2025)
| Capability | Instant Data Scraper (Extension) | DIY Scripts (Build In‑House) | Managed Service (PromptCloud) |
| Setup time | Yes (minutes) | Partial (days–weeks) | Yes (onboarding) |
| Anti‑bot mitigation (Cloudflare/Akamai, FP, Captcha) | No | Partial | Yes |
| Proxy rotation (residential, mobile, geo) | No | Partial | Yes |
| Headless/browser automation at scale | No | Partial | Yes |
| Authentication flows / tokens / cookies | No | Partial | Yes |
| Pagination, infinite scroll, JS galleries | Partial | Partial | Yes |
| Retry logic with escalation tiers | No | Partial | Yes |
| Concurrency & rate control per domain | No | Partial | Yes |
| Task queue with TTL & priority | No | Partial | Yes |
| Idempotency keys / dedupe | No | Partial | Yes |
| Field‑level QA (presence, format, ranges) | No | Partial | Yes |
| Schema contracts & versioning | No | Partial | Yes |
| Change detection (delta‑only exports) | No | Partial | Yes |
| Delivery modes (S3, API, webhooks, streams) | No (download only) | Partial | Yes |
| Freshness SLOs / SLAs | No | No | Yes |
| Observability (dashboards, reason codes) | No | Partial | Yes |
| Compliance guardrails (robots/TOS policies) | No | Partial | Yes |
| Support & maintenance | No | No | Yes |
| True cost at scale (TCO) | Low at tiny scale | High | Optimized for scale |
How to read this table
- Yes = Designed capability with production coverage.
- Partial = Possible with significant engineering effort, ongoing maintenance, or limited reliability.
- No = Not supported or impractical for sustained operations.
Key takeaways
- Extensions like Instant Data Scraper are excellent for one‑off pulls, but lack the controls required for repeatable pipelines.
- DIY can match some features, but you inherit a permanent maintenance burden: anti‑bot updates, proxy ops, schema changes, QA gates, and delivery reliability.
- A managed service gives you controls that matter in production: retries with escalation, queue TTLs and priorities, idempotency keys, schema governance, and auditable delivery.
If you’re only doing quick, one‑off pulls, a browser extension can be fine—see this rundown of Instant Data Scraper Chrome extensions and where they shine (and don’t).
The Hidden Costs of DIY Scraping (TCO You Actually Pay)
Extensions and quick scripts feel “free,” until you account for the operational work required to keep data flowing. Below is a pragmatic breakdown of where DIY costs accumulate—both in money and in risk.
Where the Time and Budget Go
- Anti‑bot drift: Sites rotate WAF rules, add device fingerprinting, or move to challenge pages. DIY means you’re reacting—rewriting headers, adding waits, and still losing throughput during changes.
- Proxy ops: Sourcing residential/mobile IPs, geo‑targeting, managing pool health, and tracking ban rates. Costs scale with volume and geography.
- Selector and schema breakage: Minor DOM changes cause silent nulls or field shifts. Without validation ladders and schema contracts, bad rows slip through.
- Retries and load control: Spikes (sales, seasonality, catalog updates) require queues, TTL, backoff, and priorities—or you drown jobs and deliver stale data.
- Delivery guarantees: Someone has to version files, maintain S3 prefixes, sign URLs, and ensure row counts/checksums match contracts.
- Compliance & audits: Robots/TOS reviews, access logs, provenance, and reason codes—especially when stakeholders ask, “Where did this price come from and when?”
TCO Snapshot (12 months)
| Cost Center | DIY Baseline | Notes |
| Engineering time | 0.5–2 FTE | Keeping scrapers alive, fixing drift, writing QA/delivery glue |
| Proxies | $300–$3,000+/mo | Varies by geo, volume, and mobile/residential mix |
| Headless infra | $100–$1,000+/mo | Browser fleets, containers, observability |
| Storage & egress | $50–$500+/mo | Images, manifests, CSV/JSON batches, vector artifacts |
| QA & monitoring | Hidden | Time to build validators, dashboards, alerts |
| Incident cost | Hidden | Downtime during bans, missed refresh windows |
| Compliance overhead | Hidden | Reviews, logs, change approvals |
In practice, teams underestimate coordination: getting ops, data, and engineering aligned every time a site changes.
Reliability Controls You’ll Eventually Need
If you continue with DIY, bake these in early to avoid rework:
- Backoff + retries with escalation tiers: plain HTTP → headless render → alt proxy → mobile exit. Cap total attempts per URL.
- Queue TTLs and idempotency keys: drop stale jobs; prevent duplicate records on retries.
- Field‑level validators: presence, format, and range checks tied to reason codes (EMPTY_PRICE, BAD_UNIT, PAGINATION_GAP).
- Schema governance: versioned contracts; additive changes; consumer compatibility tests.
- Provenance metadata: scrape_ts, source domain, proxy region, selector path, and checksum per row.
Buy vs Build: Controls You Need to Scale Scraping
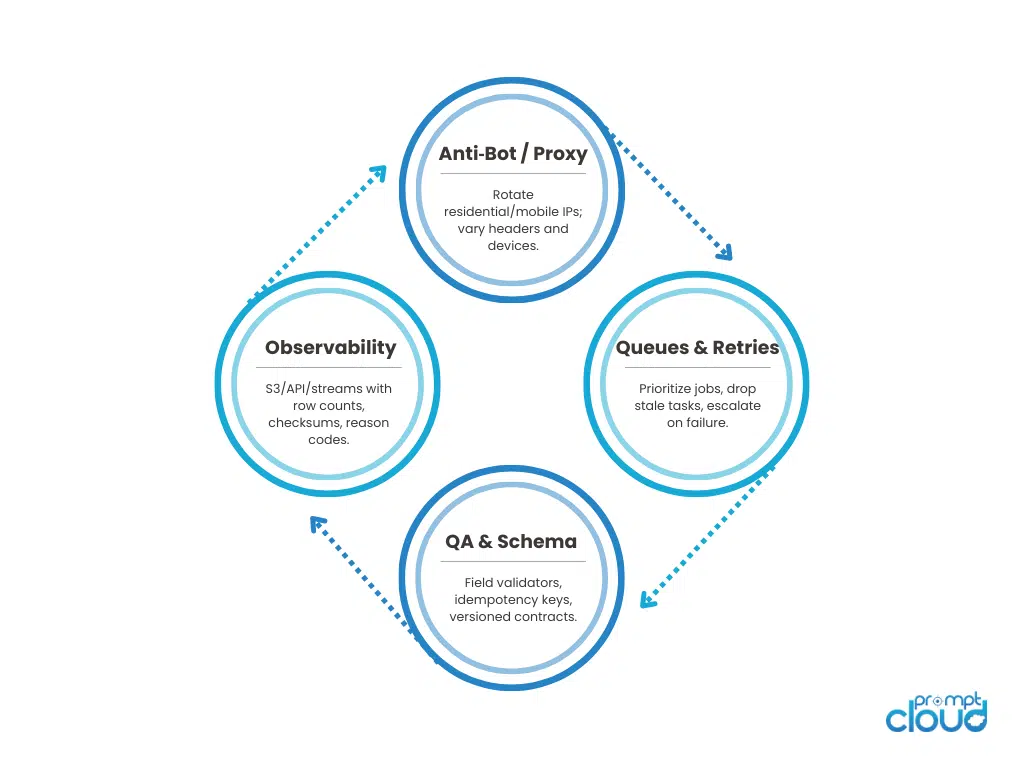
When “Buy” Pays for Itself
Choose a managed service when one or more of these are true:
- Scope: >1,000 URLs per run, multiple domains, or frequent refresh (daily/weekly).
- Friction: Recurrent bot blocks, captchas, geo walls, or mobile‑only views.
- Consumers: Data feeds a warehouse, ML training, or client deliverables with SLAs.
- Compliance: You need auditability and documented provenance.
- Focus: Your team’s priority is using the data—not running browser farms.
A managed partner absorbs the maintenance burden, keeps success rates high under changing anti‑bot conditions, and delivers schema‑aligned, deduped, and validated data via S3/API/streams—so your cost is predictable and your roadmap stays on track.
If you’re moving beyond experiments and need S3/API delivery with SLAs, read how managed web scraping offloads maintenance while keeping data fresh and compliant.
Build or Buy? A Decision Framework + ROI Example
If you’re still unsure whether to keep hacking away at your scraper or switch to a managed solution, use this quick decision checklist.
Build vs Buy Checklist
| Question | If YES → | If NO → |
| Do you need daily or weekly refreshes across 1,000+ pages? | Buy | Build may work |
| Are pages frequently behind anti-bot systems (Cloudflare, CAPTCHAs)? | Buy | Build (with effort) |
| Will you deliver data to other teams or clients with SLAs? | Buy | Build |
| Is your team spending 5+ hours/week maintaining scrapers? | Buy | Build |
| Do you need schema-aligned JSON/CSV with versioning and QA? | Buy | Build |
| Is data powering AI/analytics pipelines with accuracy dependencies? | Buy | Build |
| Are you handling multiple domains, countries, or device variants? | Buy | Build (will get harder) |
| Do you lack in-house proxy/IP rotation infra? | Buy | Build with vendor help |
| Do you want to avoid compliance risk? | Buy | Build (but risky) |
If you answered “Yes” to 3 or more — you’re better off with a managed scraping provider.
ROI Example: DIY vs Managed Service
Let’s say you need to scrape:
- 10,000 product pages weekly from 3 different domains
- Pages include images, prices, availability, and product specs
- You need QA checks, deduplication, and delivery to S3
DIY Setup (Over 12 months)
| Component | Cost Estimate | Notes |
| Engineer time (0.5 FTE) | $45,000 | Upkeep, monitoring, schema drift |
| Proxy infrastructure | $6,000 | Geo rotation, IP bans, mobile fallback |
| Headless browser infra | $1,200 | Puppeteer/Playwright containers |
| QA & retries tooling | $3,000 | Manual scripts or CLI tools |
| Downtime/incident cost | $3,000 | Missed runs, cleanup, QA regression |
| Compliance effort | $1,500 | Legal review, logs, robots.txt |
Total: ~$59,700 annually
Managed Service (PromptCloud or similar)
- Fully managed extraction, QA, and delivery
- Includes anti-bot, retries, schema governance, and support
- Transparent per-URL or per-domain pricing
- Scale, monitor, and adapt without growing your team
Total: Typically 40–60% cheaper, with fewer incident costs, and faster time-to-data.
Strategic ROI: Time and Focus
Managed services don’t just save money—they give your team back time:
- No more babysitting broken selectors
- No more proxy bans or user-agent hacks
- No more “why is the CSV missing half the rows?”
Emerging Trends That Could Shift the Build vs Buy Balance
As of 2025, a few new developments are changing what it means to build vs buy in the web scraping world. They could tilt the scale for “DIY” tools—or render them even less viable.
1. AI‑Powered Scrapers That Self‑Adapt to Site Changes
According to Web Scraping Statistics & Trends You Need to Know in 2025, one strong pattern among modern scraping infrastructures is the adoption of AI‑enabled componentry that dynamically responds to changes in site layout.
- When websites change their DOM or load elements dynamically (React, Vue, Angular frameworks), AI systems are being used to auto‑detect and update selectors based on visual features, not just CSS paths.
- Metadata extraction frameworks are being built that compare before/after samples and surface drift alerts (for example: missing price fields, shifted image galleries, changed alt text semantics).
For teams doing DIY scraping, this introduces both opportunity and burden: either you build machine learning / vision‑based detection of drift, or you incur increasing manual maintenance costs. Managed services are increasingly including “drift detection + retraining of extractors” as part of their SLAs.
2. Innovations in Anti‑Bot Measures & Ethical Bot Mitigations
Sites are getting more aggressive. The Rise of the LLM AI Scrapers: What It Means for Bot Management (Akamai, 2025) reports that bot traffic across sectors continues to rise fast, especially from agents built with LLMs (which try to mimic human behavior).
Key techniques being adopted on the defense side:
- “AI Labyrinth”‑style decoy systems (e.g., Cloudflare’s tool) that feed likely scrapers a maze of fake, generated content to waste bot cycles.
- Behavioral profiling that monitors not just rate of requests but scroll behavior, mouse movement, latency patterns, timing between requests. These are increasingly paired with ML algorithms.
- Adaptive CAPTCHAs and JavaScript challenges that change based on detected bot signature or proxy usage.
These mean DIY tools that don’t address anti‑bot dynamics via proxy rotation, randomized user agents, or headless browser simulation become much more brittle.
3. Real‑Time / Incremental Scraping with On‑the‑Fly QA
Another trend: shift from large periodic scraping to real‑time or near‑real‑time incremental updates. The market data on AI‑powered web scraping tools shows strong growth in APIs or services that push item‑level deltas rather than full catalog exports every time.
This has implications for build vs buy:
- DIY setups often export full CSVs periodically, which means repeated work, bandwidth cost, and stale data in between.
- Real‑time/incremental setups require infrastructure: change detection, item versioning, webhook or streaming endpoints, row‑level checksum logic.
Managed services increasingly bundle incremental pipelines with guaranteed freshness, thereby reducing data redundancy and supporting use cases (price monitoring, inventory alerts) where time is critical.
4. Ethical / Compliance Pressures as a Growing Cost
Scraping isn’t just technical now—it has regulatory, ethical, and cost implications.
- New policies (both internal and external) are increasingly enforcing compliance with Terms of Service, use of public vs private data, and respecting robots.txt / crawl‑delay directives. Some tools allow “ethical scraping modes” (throttling, respecting bot labels) to avoid legal or reputational risk. Web Scraping in 2025: Balancing Data Collection and Cybersecurity notes these pressures.
- Privacy constraints are relevant when scraping UGC (user content), images, videos, or image metadata (faces, personal identifiers). Misuse or overcollection can lead to legal risk.
Managed services often absorb this risk (have legal review, compliance documentation, policy layers, opt‑in features), whereas DIY must build from scratch.
Why These Trends Matter in the Build vs Buy Decision
Putting it together:
- If you plan only small, occasional scraping, DIY may still make sense—but even then, maintenance and risk are increasing.
- The cost of building “just enough” anti‑bot, drift detection, and real‑time delivery is rising. There’s a steeper hill to climb for DIY so that it matches reliability expectations.
- Managed providers are now offering features that were previously available only to high‑budget, in‑house teams: adaptive scraping, AI‑driven extractor retraining, compliance modules, etc.
If your scraping needs align with any of these trends (frequent layout changes, anti‑bot risk, need for freshness, compliance), the ROI of buying over building begins to tilt sharply.
Want expert‑built scraping support?
Building a crawler proves extraction is possible. Keeping it reliable at scale requires infrastructure, monitoring, and continuous maintenance.
FAQs
1. What is Instant Data Scraper best used for?
Instant Data Scraper works well for quick, one-off extractions from list-based webpages. It’s ideal for simple jobs, not for automated or large-scale scraping.
2. Why do DIY scrapers often fail at scale?
DIY tools struggle with anti-bot systems, proxy management, retries, schema enforcement, and delivery automation—leading to silent failures or inconsistent data.
3. What does a managed web scraping service offer that DIY doesn’t?
Managed services provide scalable infrastructure, proxy rotation, schema alignment, QA, retries, and compliant delivery via S3, APIs, or streams.
4. Is Instant Data Scraper safe to use on any website?
Not always. Many websites block scraping, and Instant Data Scraper doesn’t include compliance checks or ethical scraping safeguards like robots.txt handling.
5. When should I switch from DIY to managed scraping?
If you’re scraping at scale, facing frequent site changes, or delivering data to teams or clients with SLAs, a managed solution is the better long-term option.















