




Executive Overview
Browser-based data extraction is having its moment. The right instant data scraper lets anyone from analysts to founders turn a live webpage into usable rows and insights in seconds. This guide breaks down what these Chrome extensions do, their pros and cons, and which ones are worth trying in 2026. We’ll look at the top 10 extensions dominating the market, when to use them, and what to watch out for regarding safety, scalability, and compliance.
You’ll also find a comparison chart, usage tips, and our take on when it’s time to move from DIY scraping to managed web data solutions.
How Instant Data Scraper Chrome Extensions Work
In today’s data-driven economy, speed is everything. Whether you’re tracking competitor listings, comparing product reviews, or building datasets for AI, your success depends on how quickly you can gather clean information. That’s where instant data scraper Chrome extensions come in.
These lightweight browser add-ons let you pull structured data directly from a webpage with no code, no setup, no waiting for an engineer. They detect tables, lists, and repeating elements, then export everything to CSV, Excel, or JSON formats ready for analysis.
While APIs and full-scale crawling frameworks remain the gold standard for production systems, Chrome-based instant scrapers fill an important gap. They allow business users to test ideas, validate datasets, and move quickly without engineering support. The key is understanding when they are sufficient — and when your workflow outgrows the browser.
Your data collection shouldn’t stop at the browser.
Many organizations begin web scraping with internal scripts, but maintaining crawler infrastructure, handling anti-bot protections, and monitoring data quality quickly becomes a full-time operational task.
Benefits of Using Instant Data Scraper Chrome Extensions

| Benefit | What It Means for You |
| Swift Data Capture | Automates extraction from web pages in seconds, cutting manual effort. |
| Straightforward Operation | Intuitive point-and-click setup — ideal for non-technical teams. |
| Budget-Friendly | Most tools offer free tiers, lowering entry cost for data collection. |
| Personalized Retrieval | Customize which fields or tables to capture. |
| Reliable Accuracy | Automated scraping reduces manual copy-paste errors. |
| Real-Time Intelligence | Stay updated with fast-refreshing data. |
| Competitive Edge | Use market and pricing data to act before competitors. |
The Top 10 Instant Data Scraper Chrome Extensions (2026 Edition)
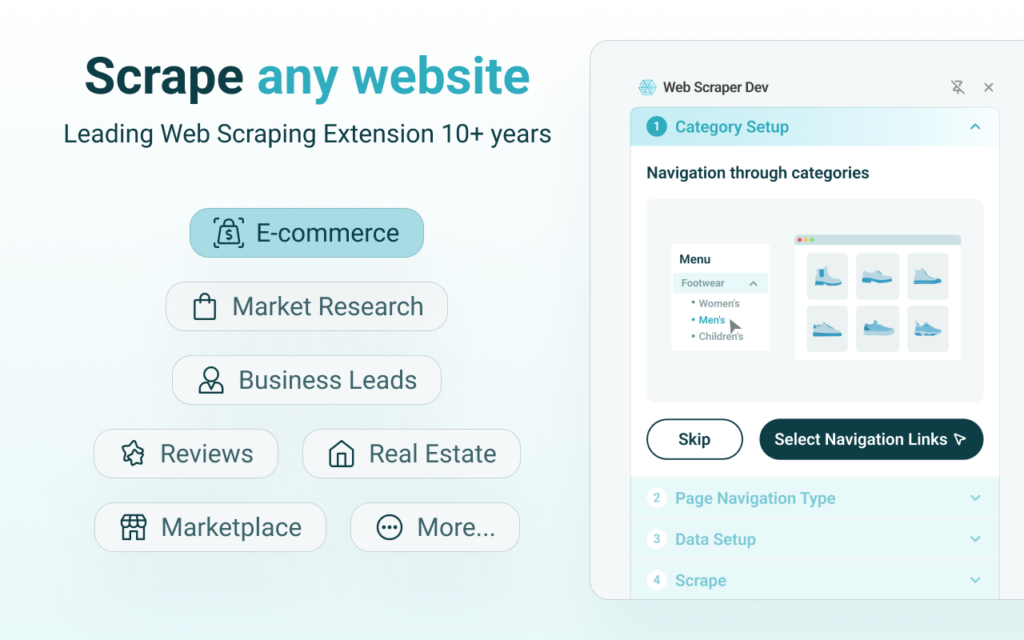
1. Web Scraper
The veteran in this space. Supports multi-page navigation, scheduling, and export to JSON or CSV. Works best for structured catalogs and static pages.
Source: Chrome Web Store
Best For:
SEO professionals, ecommerce teams, and analysts scraping structured catalogs or directory-style websites.
Pricing Snapshot:
Offers a free Chrome extension for manual scraping. Cloud automation and scheduling features are available in paid plans.
Limitations:
Requires manual sitemap configuration, which can feel technical for non-technical users.
Export Quality:
CSV and JSON exports are well-structured when sitemap logic is correctly configured, though improper pagination setup can result in partial datasets.
Our Testing Notes: Installation was straightforward from the Chrome Web Store. Setting up a sitemap required manual configuration, which may feel technical for beginners. Pagination worked reliably on structured ecommerce pages, but dynamic JavaScript-heavy sites required additional tweaks.
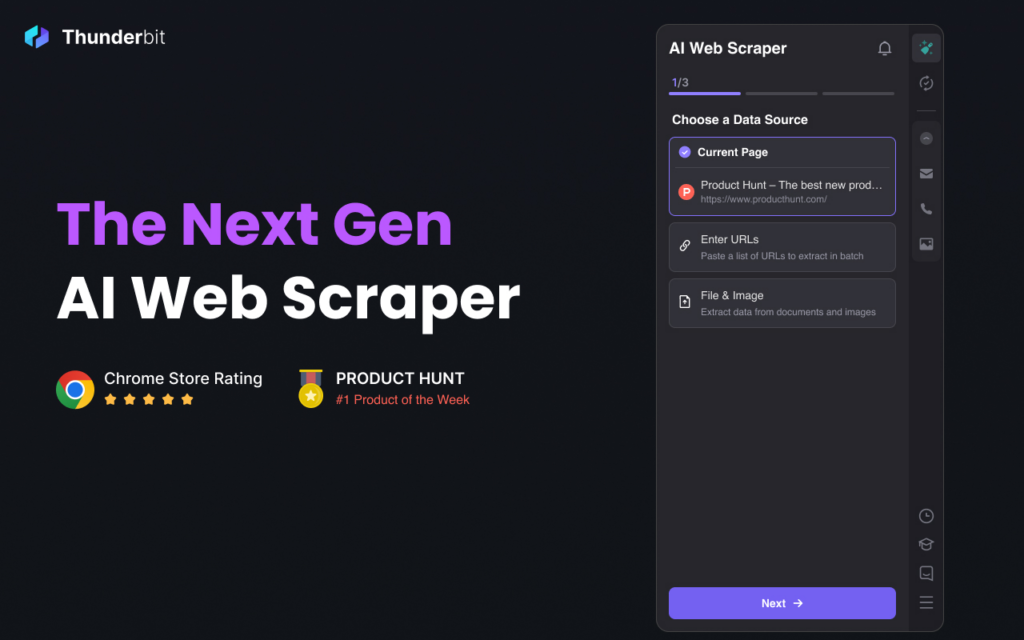
2. ParseHub (currently known as Thunderbit)
Combines a visual editor with dynamic rendering. Handles JavaScript-heavy sites and rotating IPs automatically.
Source: Chrome Web Store
Best For:
Users handling JavaScript-heavy websites or dynamic content that basic browser scrapers struggle with.
Pricing Snapshot:
Free tier available with project limits. Advanced scheduling and higher volume usage require paid plans.
Limitations:
Setup time is longer compared to lightweight Chrome-only tools, and there is a learning curve.
Export Quality:
Exports to CSV and JSON are clean and structured. Dynamic content is captured reliably, though larger datasets may require post-processing.
Our Testing Notes: The visual workflow builder handled dynamic elements effectively. However, initial setup took longer than pure browser extensions. Exported CSVs were clean and structured, though advanced scheduling required a paid tier.
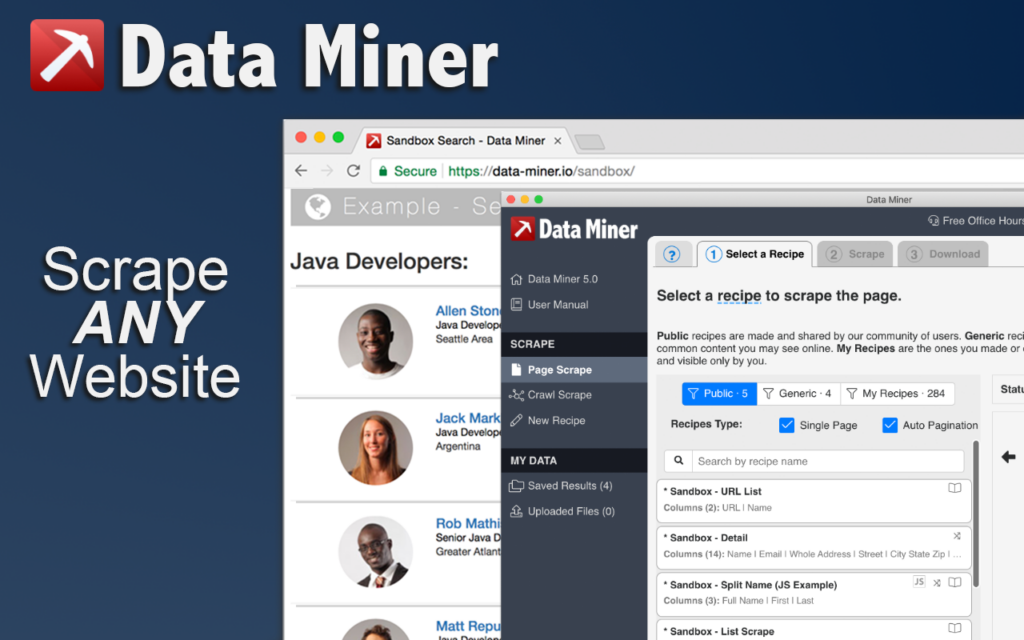
3. Data Miner
Lets you create, share, and reuse scraping templates. A favorite for collaborative teams working on similar domains.
Source: Chrome Web Store
Best For:
Teams that need reusable scraping templates across similar domains or recurring research tasks.
Pricing Snapshot:
Free tier with usage caps. Paid plans unlock higher extraction limits and advanced automation.
Limitations:
Complex multi-level extraction requires creating custom recipes, which may take time to configure.
Export Quality:
CSV and Excel exports maintain column consistency. Field structure is generally reliable when using tested templates.
Our Testing Notes: Template sharing worked smoothly across domains. The interface was intuitive for simple captures, but complex multi-level extraction required building custom recipes. CSV exports preserved column consistency well.
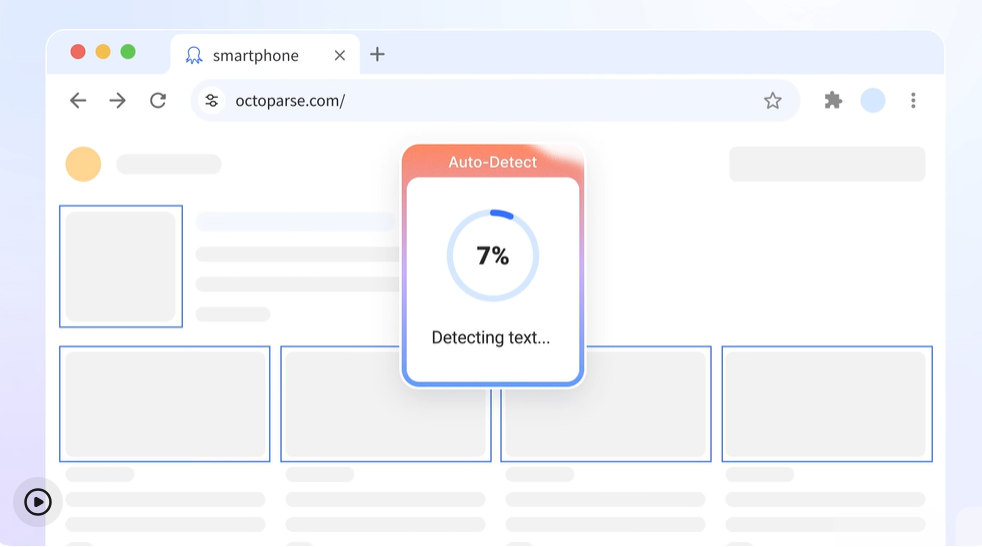
4. Octoparse
User-friendly “Wizard Mode” for beginners but powerful under the hood. Manages pagination, JS, and scheduling efficiently.
Source: octoparse.com’s website
Best For:
Business users seeking a balance between no-code simplicity and dynamic site support.
Pricing Snapshot:
Free version available for limited projects. Automation, scheduling, and API access require paid plans.
Limitations:
Cloud automation and advanced features are locked behind subscription tiers.
Export Quality:
Exports to CSV, Excel, and API endpoints are clean and suitable for analytics workflows. Pagination handling is stable when configured correctly.
Our Testing Notes: Wizard Mode simplified extraction for common layouts. Dynamic rendering worked reliably in testing, though scheduling and automation required upgrading. Initial configuration was beginner-friendly compared to developer frameworks.
5. Instant Data Scraper
A true plug-and-play tool. Detects data tables instantly, exports to CSV/Excel, and needs zero configuration. Excellent for quick market checks or simple lists.
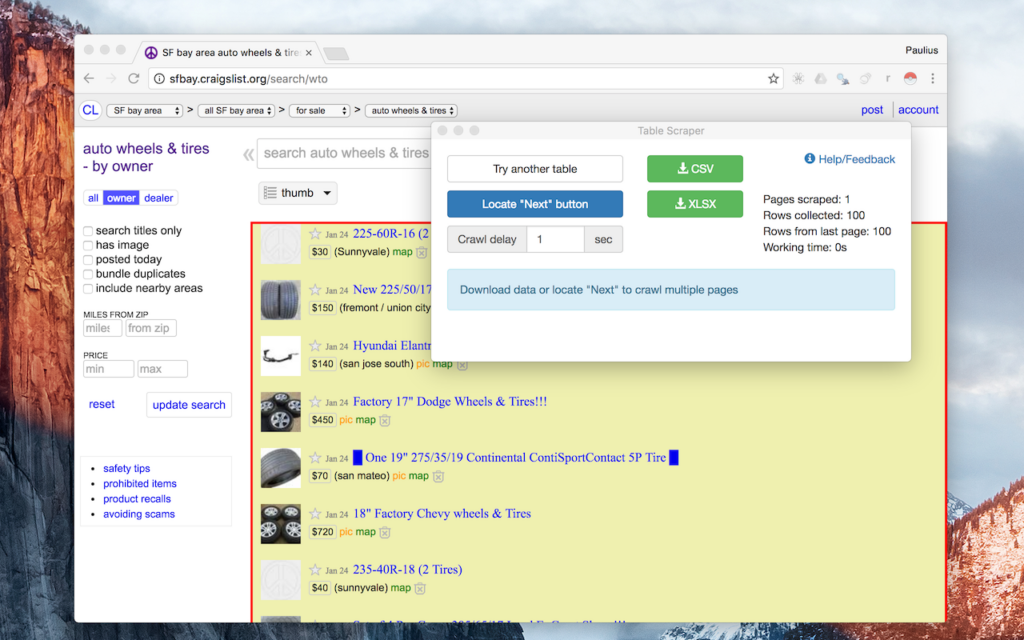
Source: Chrome Web Store
Best For:
Founders, marketers, and analysts running quick validations or one-off research tasks.
Pricing Snapshot:
Free Chrome extension with no paid tier required for basic exports.
Limitations:
No built-in scheduling or automation. Pagination must be handled manually.
Export Quality:
Exports to CSV and Excel are clean for single-page captures but may require deduplication when handling multiple pages manually.
Our Testing Notes: On a standard ecommerce category page, the tool immediately detected repeating product blocks. CSV exports retained proper column alignment. Pagination required manual page navigation, limiting automation potential.
6. CopyTables
Purpose-built for grabbing tabular data into Excel or Google Sheets. Perfect for researchers and journalists.
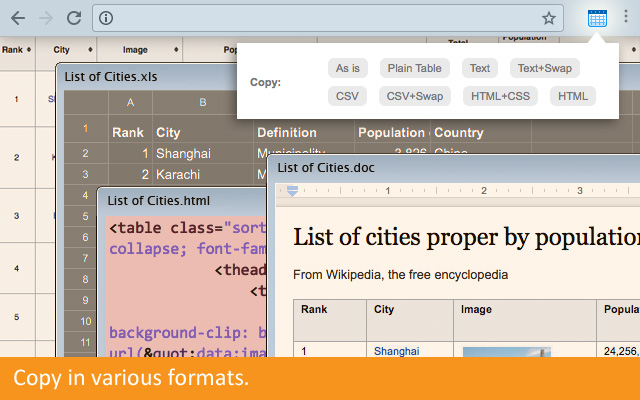
Source: Chrome Web Store
Best For:
Researchers, journalists, and analysts extracting visible HTML tables directly into spreadsheets.
Pricing Snapshot:
Free extension with optional premium functionality depending on the version.
Limitations:
Limited strictly to visible tabular data. Does not support dynamic page scraping or pagination.
Export Quality:
Produces clean spreadsheet-ready output with accurate column alignment when scraping static tables.
Our Testing Notes: Ideal for grabbing visible table data into spreadsheets. It does not handle pagination or dynamic content. Best suited for researchers needing clean table exports from static pages.
7. Simplescraper
Lightweight, clean UI, and offers batch extraction for multiple pages in paid tiers.

Source: Chrome Web Store
Best For:
Users looking for lightweight batch extraction across multiple similar pages.
Pricing Snapshot:
Free tier available for limited usage. Batch and automation capabilities require a paid plan.
Limitations:
Browser performance may slow when scraping larger datasets.
Export Quality:
CSV exports are structured and usable, though very large extractions may require additional cleaning.
Our Testing Notes: Lightweight and easy to use for basic extractions. Batch extraction worked in testing, though larger datasets slowed browser performance. Paid plans unlock more reliable automation.
8. Dexi.io
Cloud-based platform supporting Chrome and Firefox. Comes with templates, streaming options, and API access.

Source: Dexi.io’s website
Best For:
Teams requiring cloud-based workflows and structured data automation.
Pricing Snapshot:
Primarily paid plans with enterprise-oriented features. Limited trial options may be available.
Limitations:
Not a lightweight instant extension; setup requires onboarding and configuration time.
Export Quality:
Supports CSV, JSON, and API delivery. Structured exports are suitable for integration into BI systems.Our Testing Notes: More platform than extension. Cloud workflows handled structured extraction effectively. Setup required onboarding time and was better suited for teams than individual users.
9. Helium Scraper
Integrates machine learning for element recognition and can handle complex, dynamically loaded pages.

Source: Chrome Web Store
Best For:
Technical users handling complex or dynamically rendered pages.
Pricing Snapshot:
Paid software with trial options. Positioned more as a professional tool than a free extension.
Limitations:
Higher system resource usage compared to browser-only tools.
Export Quality:
Exports structured CSV files with solid field alignment, though configuration accuracy directly impacts output quality.
Our Testing Notes: Handled dynamic pages well during testing. Resource usage was noticeably higher compared to lightweight tools. Suitable for technical users comfortable configuring advanced options.
10. Import.io
A professional-grade tool offering full workflow automation, APIs, and built-in analytics. Best suited for teams managing recurring extraction jobs.
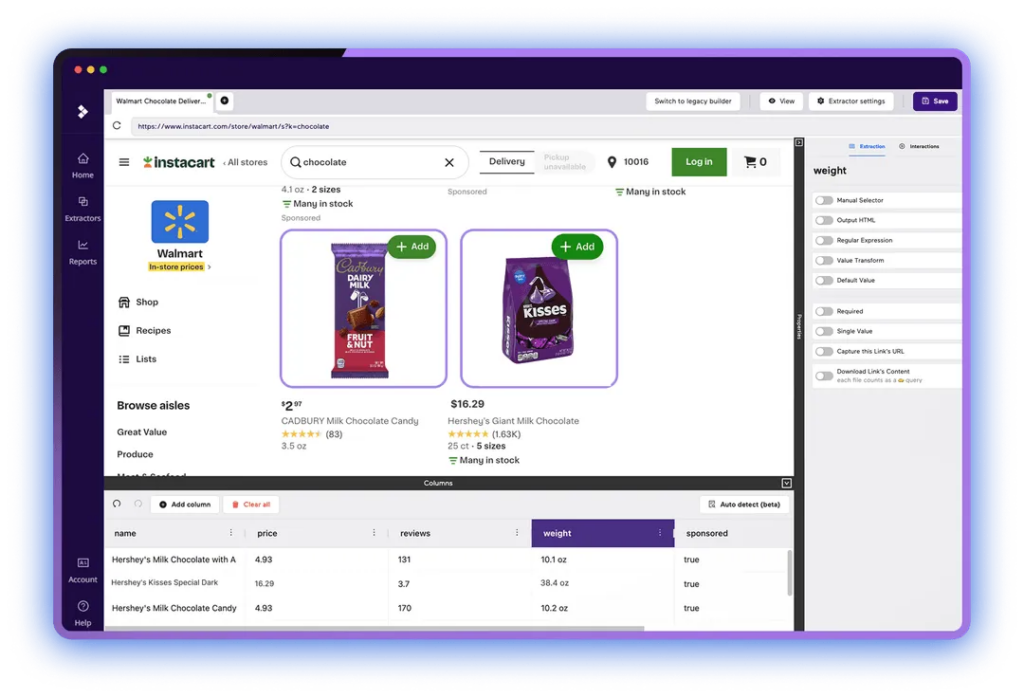
Source: import.io’s website
Best For:
Organizations needing workflow automation and recurring structured data extraction.
Pricing Snapshot:
Professional-grade paid plans. Free trial may be available depending on account type.
Limitations:
Steeper learning curve and overpowered for simple one-off scraping needs.
Export Quality:
Structured exports via CSV and API are consistent and suitable for enterprise analytics systems.
Our Testing Notes: Strong automation capabilities and API support. Setup required a learning curve but delivered stable recurring extraction. Better positioned as a semi-enterprise tool than a quick browser solution.
Many organizations begin web scraping with internal scripts, but maintaining crawler infrastructure, handling anti-bot protections, and monitoring data quality quickly becomes a full-time operational task.
Comparing Popular Instant Data Scrapers
| Tool | Ease of Use | Dynamic Page Support | Export Formats | Best For | Limitations |
| Instant Data Scraper | ★★★★★ | Moderate | CSV, Excel | Beginners | Not ideal for multi-page data |
| Web Scraper | ★★★★☆ | Moderate | CSV, JSON | SEO teams, catalog scraping | Needs sitemap setup |
| ParseHub | ★★★★☆ | Excellent | CSV, JSON | Advanced users | Learning curve |
| Octoparse | ★★★★★ | Excellent | CSV, Excel, API | Enterprises | Paid features for scheduling |
| Data Miner | ★★★★☆ | Good | CSV, Excel | Teams sharing templates | Limited free tier |
| Dexi.io | ★★★☆☆ | Excellent | CSV, JSON, API | Automation use cases | Requires paid plan |
| Helium Scraper | ★★★☆☆ | Excellent | CSV | Technical users | High resource usage |
How to Choose the Right Instant Data Scraper Chrome Extension
With dozens of instant data scraper Chrome extensions available, selecting the right one depends less on popularity and more on workflow fit. While feature checklists are helpful, decision-making should be based on four core factors: data complexity, frequency, compliance sensitivity, and long-term scalability.
1. Data Structure and Page Complexity
Start by evaluating the type of web page you plan to scrape. Static HTML tables are the easiest to extract. Product grids, directory listings, and paginated results require a tool that detects repeating elements reliably. Dynamic pages that load content via JavaScript or infinite scroll require extensions capable of rendering and waiting for content to load.
If your target site refreshes content dynamically, basic instant data scrapers may miss fields or export incomplete rows. In such cases, choose Chrome data scraping extensions that explicitly support dynamic rendering.
2. One-Off vs Recurring Use
Instant data scraper Chrome extensions are ideal for exploratory and one-time extraction. If your task involves downloading a supplier catalog once a month or validating competitor prices for a campaign, a browser-based tool may be sufficient.
However, if you need daily updates, automated refreshes, or integration into dashboards, manual browser exports quickly become inefficient. Ask yourself: will this task repeat weekly or scale beyond a few thousand rows? If yes, automation capabilities should be part of your evaluation criteria.
3. Export Cleanliness and Data Hygiene
Not all CSV files are equal. Some extensions export nested fields inconsistently. Others duplicate header rows across paginated exports. Before committing to a tool, test it on 3–5 pages and inspect:
- Are column names consistent?
- Are empty fields handled properly?
- Does pagination introduce duplicates?
- Is text encoding clean (no broken characters)?
Small export issues can multiply into hours of cleaning later. The best instant data scraper is not the one that extracts fastest — it’s the one that minimizes cleanup time.
4. Permission Model and Security Risk
Every Chrome extension operates within your browser session. That means it may access cookies, session tokens, and browsing history depending on permissions granted. Review extension permissions carefully before installation. Avoid tools requesting unrelated privileges such as file system access or clipboard monitoring.
For enterprise environments, internal approval workflows are recommended before deploying web scraping Chrome extensions across teams.
5. Scalability Ceiling
Browser-based data extraction tools operate within the memory limits of your local machine. Large datasets can freeze Chrome or crash tabs. If you anticipate scraping tens of thousands of records, consider whether the extension supports batching or cloud execution.
Instant data scrapers are excellent for validation and rapid research. But once datasets grow or business decisions depend on consistent refreshes, infrastructure limitations surface.
Choosing the right instant data scraper Chrome extension is ultimately about aligning the tool with the maturity of your workflow. Use browser extensions for speed and validation. Move toward structured automation when reliability becomes essential.
Maximizing Efficiency with the Right Tools
The best instant data scraper is the one that fits your project’s maturity. Start with quick browser runs to validate feasibility. As volume grows, move toward frameworks or managed pipelines.
Tips to get the most out of these tools:
- Always preview data before export.
- Capture unique identifiers (IDs or URLs).
- Test pagination early to avoid duplication.
- Document your runs (date, domain, and version).
- Respect website terms and robot directives.
Using extensions responsibly ensures both ethical compliance and consistent results.
Security, Safety, and Compliance
Always:
- Install from the official Chrome Web Store.
- Review permissions during setup.
- Avoid capturing personal or sensitive data.
- Use organizational approval flows for browser extensions.
Browser extensions operate with elevated permissions inside your browser. Over the past few years, Google has repeatedly removed extensions from the Chrome Web Store for policy violations related to excessive permissions or undisclosed data access. That makes due diligence non-negotiable when installing scraping tools. Always review permissions, verify the developer, and avoid extensions that request unrelated access such as clipboard or local file control.
Where Browser Extensions Work Best
Instant data scrapers are purpose-built for speed. If your workflow involves one-off captures, exploratory research, or datasets under a few thousand rows, extensions are often the fastest solution available. They require no backend infrastructure, no proxy management, and no engineering backlog.
The challenges begin when teams attempt to convert manual browser captures into recurring production systems. At that stage, automation, monitoring, and compliance requirements typically exceed what extensions can reliably support.
When to Move Beyond Browser Extensions
Instant tools are great for validation, but enterprise data needs scale, control, and reliability. A managed solution like PromptCloud offers:
- Continuous scraping with automatic retries
- Real-time data feeds and APIs
- Custom schema design
- Storage integration (S3, BigQuery, Snowflake)
- Built-in compliance with GDPR and CCPA
If your business depends on consistent web data — pricing, listings, or sentiment — consider managed data pipelines as the next logical step.
Evaluating Managed Solutions?
Many organizations begin web scraping with internal scripts, but maintaining crawler infrastructure, handling anti-bot protections, and monitoring data quality quickly becomes a full-time operational task.
Who Uses Instant Data Scrapers?
Marketing and Growth Teams:
Growth marketers monitor competitor pricing, SEO metadata, influencer mentions, and product listings directly inside Chrome. Exporting to Sheets or Looker Studio allows faster experimentation without engineering delays.
Research and Product Teams:
Analysts frequently use instant scrapers for high-frequency, small-batch captures such as app reviews, forum threads, or feature comparisons. The value lies in speed and freshness, not volume.
Journalists and Academic Researchers:
Investigative teams collect structured public data such as listings, directories, or policy notices. Browser-based exports allow timestamped documentation without backend tooling.
Small Businesses:
Local enterprises use extensions to monitor supplier catalogs, real estate listings, and competitor pricing without hiring data engineers. Instant scrapers democratize structured web data access.
The AI Layer: How Machine Learning is Changing Browser Scraping
In 2026, instant scrapers are starting to integrate computer vision and large language models to interpret page structures.
Visual Pattern Recognition
Traditional scrapers use XPath or CSS selectors. Modern tools now use visual AI to understand layout intent — detecting tables, product cards, or comment threads even when HTML changes. This reduces breakage and improves automation accuracy.
Natural Language Extraction
LLM integration allows scrapers to classify or summarize text before export. For example, an LLM-enabled scraper can label reviews as positive or negative, extract entities like “brand name” or “feature,” and output ready-to-analyze CSVs.
Challenges of Instant Data Scrapers (and How to Overcome Them)
Even as Chrome extensions evolve, limitations remain — especially when teams push them beyond their intended scale.
| Challenge | Impact | How to Mitigate |
| Dynamic Content | Data missing from JavaScript-rendered pages | Use JS-capable scrapers like ParseHub or Octoparse |
| Pagination & Infinite Scroll | Incomplete data capture | Configure pagination logic or switch to automation frameworks |
| Rate Limits & Blocks | IP or browser bans | Throttle requests or rotate user agents |
| Unstructured HTML | Messy exports, broken rows | Use extensions with AI field detection |
| Legal Compliance | Potential ToS violations | Always check robots.txt and site policies |
| Data Volume | Browser crashes or freezes | Move to managed crawlers for large-scale work |
PromptCloud addresses all of the above with dedicated infrastructure, rotating proxies, and schema validation layers — turning browser-level trials into production-grade pipelines.
Evaluating Instant Data Scraper Extensions Before Installation
Not all scrapers are equally safe or reliable. Chrome’s new AI Permission Monitor (rolled out in early 2026) automatically flags extensions that request excessive privileges.
Here’s a checklist before installing any data extraction extension:
- Check Source Authenticity – Always install from the official Chrome Web Store.
- Review Permissions – Avoid extensions requesting clipboard or file system access unnecessarily.
- Verify Developer Reputation – Established developers often maintain active GitHub pages or user communities.
- Check Last Update Date – Outdated extensions may be incompatible with Chrome’s latest security model.
- Read Independent Reviews – Sites like TechRadar, ZDNet, and Chrome Unboxed publish periodic safety audits.
For enterprise users, internal policy reviews are now mandatory before deploying extensions organization-wide.
Enterprise Transition: From Chrome Extensions to Data Infrastructure
Instant scrapers act as great prototypes. But once companies see recurring value, they start formalizing data operations. Here’s what that progression looks like:
Stage 1 – Ad Hoc Scraping
Analysts use extensions to capture data manually.
Stage 2 – Process Documentation
Templates, SOPs, and shared folders standardize workflows.
Stage 3 – Semi-Automation
APIs, schedulers, and integrations push scraped data to shared dashboards.
Stage 4 – Managed Infrastructure
Dedicated vendors like PromptCloud deliver automated data feeds with compliance SLAs and quality assurance.
Stage 5 – Analytics Integration
Web data merges with CRM, ERP, or ML systems becoming part of core business intelligence. At that point, “data scraping” becomes data delivery, and the organization treats it as a continuous system rather than a side task.
Global Regulations Impacting Browser Scraping in 2026
The legal environment for data extraction continues to evolve:
- EU Digital Services Act (2024): Requires clearer consent and labeling for automated data collection.
- California Data Broker Act (effective 2026): Extends CCPA by mandating registration for entities reselling scraped data.
- India’s DPDP Act (2023): Strengthens personal data protection and restricts scraping of identifiable user content.
- Japan’s Transparency Guidelines for AI (2026): Affect training datasets sourced via scraping.
Teams relying on instant scrapers should ensure they’re not collecting personal data (names, emails, social profiles) without consent. Managed vendors like PromptCloud implement automatic redaction pipelines to anonymize sensitive attributes before delivery.
An automatic redaction removes or masks sensitive information such as personal identifiers before data is delivered downstream.
The Economics of Browser-Based Scraping
While many scrapers are free, “free” rarely scales well. A 2026 Dataversity survey found that organizations relying solely on browser extensions for recurring scraping spend 2.5× more time cleaning and merging data than those using structured APIs or managed feeds.
True Cost Considerations
- Human Time: Manual exports and cleaning eat analyst hours.
- Error Rate: Browser captures often produce duplicates or misaligned columns.
- Compliance Overheads: Lack of audit trails creates risk.
- Downtime: Chrome updates or site layout changes can halt operations overnight.
Why Companies Upgrade
Once teams calculate the combined cost of downtime and rework, managed scraping becomes cheaper in total cost of ownership (TCO). PromptCloud’s automated data delivery systems run continuously, with monitoring and self-healing retries, eliminating hidden operational costs.
Case Example: Instant to Enterprise Transition
A mid-sized travel aggregator started with the Instant Data Scraper Chrome extension to track competitor listings. Within months, the team realized:
- Manual downloads couldn’t keep up with daily updates.
- CSVs lacked schema consistency.
- New site layouts broke extraction rules weekly.
They migrated to PromptCloud’s custom crawler feeds, gaining:
- Daily structured delivery in Parquet format.
- Monitoring for missing fields and errors.
- API integration with their pricing dashboard.
Parquet is a column-based data file format optimized for analytics systems like BigQuery and Snowflake. It stores data more efficiently than CSV and loads faster for large-scale analysis.
The result: a 40% reduction in data lag and zero manual upkeep. The original Chrome workflow still serves as a fallback for exploratory research — but production now runs fully automated.
Future of Instant Scraping: Browserless Automation
The line between browser-based and programmatic scraping is blurring. Chrome’s WebDriver BiDi (Bidirectional Protocol), rolled out in late 2024, enables remote automation while maintaining a real browser context.
Many extension developers are already pivoting toward browserless scrapers — lightweight agents that use headless Chrome in the cloud but mimic the same instant experience. Expect the next wave of tools to combine:
- Extension simplicity (visual selection)
- Server reliability (24×7 uptime)
- AI adaptation (self-repairing selectors)
For developers building internal tools, this hybrid approach will merge convenience with compliance.
Building a Sustainable Data Strategy Around Instant Scrapers
Instant scrapers are excellent entry points, but they shouldn’t operate in isolation. The smartest organizations build hybrid workflows blending fast browser-based scrapes with structured, automated data delivery.
Start small: test an instant data scraper to validate what kind of data truly adds value to your decisions. Once you identify consistent sources, formalize your process by scheduling updates and creating standardized schemas. Pair every quick scrape with metadata timestamps, URLs, and page versions to maintain transparency.
Over time, these habits evolve into a repeatable data pipeline. Marketing teams can track competitive listings automatically, product teams can benchmark features, and finance analysts can refresh pricing data weekly.
The real power lies in the combination of the agility of instant tools with the dependability of managed solutions. PromptCloud’s infrastructure exists to bridge that gap, ensuring every fast-captured dataset can scale into a secure, compliant, enterprise-ready feed.
Summary
Instant data scraper Chrome extensions have evolved from hobby tools into legitimate workflow components. They enable fast, no-code extraction for analysts, founders, researchers, and growth teams. For exploratory use, competitive monitoring, and lightweight research, they often represent the fastest path from webpage to spreadsheet.
However, browser-based scraping has structural limits. Once reliability, automation, compliance, or scale become requirements, teams typically move toward managed data infrastructure.
The most effective strategy is not choosing one approach over the other but understanding when each is appropriate.
Ready to evaluate?
Many organizations begin web scraping with internal scripts, but maintaining crawler infrastructure, handling anti-bot protections, and monitoring data quality quickly becomes a full-time operational task.
If You’d Like to Read More
- Real-Time Scraping for LLM Agents — how AI agents use live web data streams.
- Scraping Amazon Prices at Scale — technical deep dive into scaling product data feeds.
- Mobile Proxy vs. Datacenter for Scraping — which proxy strategy fits your data operations.
- Etsy Scraper 2026 — decoding category hierarchies and listing trends with structured feeds.
Many organizations begin web scraping with internal scripts, but maintaining crawler infrastructure, handling anti-bot protections, and monitoring data quality quickly becomes a full-time operational task.
FAQs
1. Is the Instant Data Scraper Chrome extension safe?
Yes, if downloaded from the Chrome Web Store and used responsibly. Always check permissions and reviews before installation.
2. How do I use an instant data scraper?
Visit your target site, click the extension, preview auto-detected data, and export to CSV or Excel. Most support pagination and custom selection.
3. Can I use these scrapers for dynamic or infinite scroll pages?
Tools like ParseHub, Octoparse, or Helium Scraper handle dynamic content. For others, test scroll depth manually.
4. Is Instant Data Scraper free?
Yes, it’s free to use. Some premium versions of other scrapers offer automation or cloud sync.
5. When should I move to a managed scraping service?
When you need recurring updates, large volumes, or guaranteed uptime. Managed services offer better data quality, scalability, and compliance.















