




**TL;DR** Good data is the oxygen your business runs on. Bad data? It’s poison in the system, invisible at first, then slowly choking decisions, draining budgets, and wrecking customer trust. Think clean, complete, and consistent information versus outdated, incomplete, and error-filled records that send your teams chasing ghosts. The cost of poor data quality isn’t just a spreadsheet headache; Gartner pegs it at an average $12.9 million lost per year for organizations, with some bleeding up to 25% of revenue.
The difference between good and bad data shows up everywhere: missed sales targets, wrong pricing calls, bad inventory bets, broken analytics. And here’s the kicker: most businesses don’t even know they’re running on bad data until it’s too late.
The fix? Stop treating data collection like a “good enough” checkbox. Partner with a web scraping service provider that doesn’t just dump raw data in your lap, but delivers structured, accurate, verified datasets you can trust. Because in the age of AI and predictive analytics, the cost of bad data isn’t just high, it’s lethal to your growth.
Why Good Data is the Foundation of Business Success
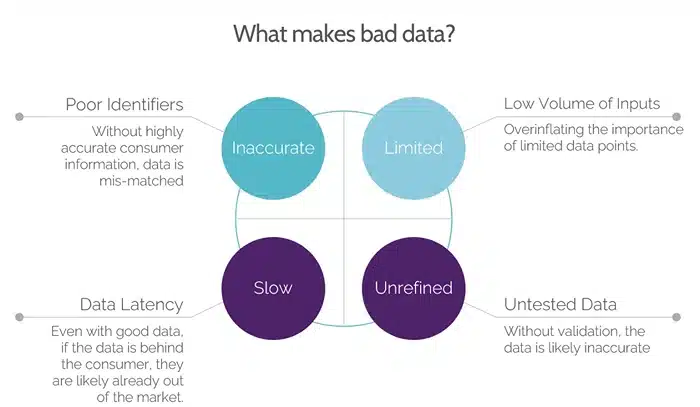
Image Source: analytics-iq
Data is supposed to be your secret weapon. The edge that tells you exactly what your customers want, where your competitors are headed, and where the next big opportunity is hiding. But here’s the uncomfortable truth: if that data is wrong, incomplete, or outdated, it stops being a weapon and starts being a liability.
We’ve seen it play out in every industry: e-commerce teams pricing products based on stale competitor data, travel platforms sending customers to hotels that no longer exist, retailers overstocking dead inventory because their forecasts were built on flawed numbers. On paper, everything looked fine. In reality? Money burned, customers lost, reputations bruised.
The scary part is that bad data rarely waves a red flag. It blends in. It sits quietly in your systems, feeding your dashboards, whispering bad advice into every meeting. And because it “looks” official, decisions get made on it. Big ones. The kind that cost millions.
You don’t win on hunches, you win on solid data. The kind that’s accurate, complete, structured the same way end-to-end, and refreshed on time. With that in place, you’re not guessing; you’re acting on a clear picture. Bad data does the opposite: it blinds you while making you think your vision is sharp.
The real challenge? Most businesses think they’re dealing with good data when they’re not. Especially if that data is coming from inconsistent sources, outdated scraping setups, or a patchwork of manual collection methods. This is exactly where the right web scraping service provider becomes a game-changer, not because they collect data (plenty of people can do that), but because they deliver it clean, verified, and ready to plug straight into your decision-making.
In this guide, we’re breaking down the difference between good and bad data, the true cost of poor data quality, and how to spot the warning signs before it eats into your revenue. If you manage or rely on scraped data for your business, what you’re about to read could save you from some very expensive mistakes.
What is “Good Data” and What is “Bad Data”?
Let’s cut through the buzzwords for a second. Good data isn’t some mystical unicorn only data scientists can spot. You don’t need a PhD to tell if the numbers in front of you are trustworthy. You just need to know what to look for.
Good data has a few non-negotiables:
- Accurate: Every number, date, and detail matches the real-world truth.
- Complete: No mysterious blank fields or missing values that leave you guessing.
- Consistent: Formats line up. Addresses follow the same structure. Prices aren’t listed in five different currencies with no labels.
- Timely: It’s fresh enough to reflect today’s reality, not last quarter’s.
- Relevant: It serves the exact business question you’re asking, not something “close enough.”
When you have this kind of data, your decisions hit the mark more often. Your analytics tell a story you can trust. Your forecasts aren’t shots in the dark; a steady beam of reality guides them.
Now, let’s flip the coin.
Bad data can look harmless, even convincing, at first. But dig in, and you’ll see the cracks:
- Outdated: The price of a product from three months ago. A hotel listing for a place that shut down last year.
- Incomplete: Customer records are missing half the contact details. Product listings with no descriptions.
- Inconsistent: Two different spellings of the same city. Dates in multiple formats. Prices are showing up with and without taxes, randomly.
- Inaccurate: Wrong specs, incorrect pricing, and mislabeled products, all of which send your teams in the wrong direction.
Here’s the dangerous part: bad data doesn’t just mess with your reports. It messes with your strategy. If you’re an e-commerce manager and you think your competitors dropped prices when they didn’t, you slash your prices unnecessarily and lose margin for no reason. If you’re in travel and you promote outdated deals, customers lose trust instantly.
The term data discrepancy isn’t just a technical note in a QA report; it’s a flashing warning sign that what you’re working with might be leading you into a costly mistake. And the scary truth? Many businesses only realize the cost of poor data quality when they’re deep in the damage.
That’s why knowing the signs early and working with a web scraping service provider that bakes verification and validation into their process is non-negotiable if you want to avoid the silent bleed that bad data causes.
Common Causes of Bad Data in Web Scraping
Bad data isn’t random; it’s what happens when processes are sloppy, oversight is missing, or your scraping setup can’t keep up over time. If you’ve ever opened a dataset and caught yourself wondering, “Where did this even come from?” or “Why does this look nothing like what’s live right now?”, you’ve already run into the problem.
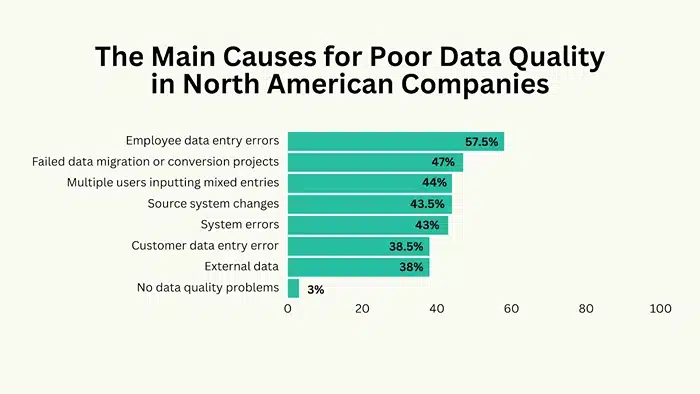
Image Source: edgedelta
Here are the most common culprits:
1. Data Discrepancy from Inconsistent Sources
Pulling data from different websites, marketplaces, or APIs that each follow their own formatting quirks is a recipe for inconsistency. One site lists prices including tax, another doesn’t. One shows stock status in a “Yes/No” field, another uses “In Stock/Out of Stock.” Without normalization, this creates a messy dataset that’s a nightmare for analytics.
2. Outdated Information from Poor Scheduling
Data ages fast, especially in industries like e-commerce, travel, and real estate, where prices and availability change daily (sometimes hourly). If your scraping schedule isn’t aggressive enough, you’ll end up with stale information. That can mean promoting last month’s deals, comparing against outdated competitor prices, or stocking products no one wants anymore.
3. Missing Fields and Incomplete Metadata
In fast-moving industries like e-commerce, travel, and real estate, data can go out of date in hours. If you’re not scraping often enough, you’ll be making calls on outdated information. That’s when you start promoting expired deals, basing your prices on last week’s market, or ordering stock that’s already past its demand peak.
4. Poor Structuring and Formatting
Even if the right data points are scraped, dumping them into a jumbled format ruins their usability. Dates in multiple formats, inconsistent category tags, or a lack of clear relationships between fields all slow down integration into your systems or, worse, lead to wrong conclusions because the data didn’t match up.
5. Duplicate Records and Redundancy
Duplicates might look harmless, but they distort the truth. They can inflate sales figures, manipulate stock counts, and consume unnecessary storage space. Without proper deduplication, scraping the same product from different listings will throw your forecasts way off line.
The frustrating part? Many of these issues happen silently. Your dashboards might still look full of “fresh” numbers, but they’re polluted with inaccuracies. And every decision you make from that polluted pool increases the cost of poor data quality, in wasted marketing spend, lost sales opportunities, and bad strategic bets.
This is why working with a web scraping service provider that proactively checks for these problems is critical. The right provider doesn’t just collect data; they clean, structure, and validate it before you ever see it.
The Hidden Costs of Poor Data Quality
Bad data doesn’t just mess up your spreadsheets; it bleeds money, wastes time, and chips away at your credibility. The scariest part? Most businesses underestimate just how expensive it is until they start adding up the damage.
Let’s break down the three big ways bad data eats into your business:
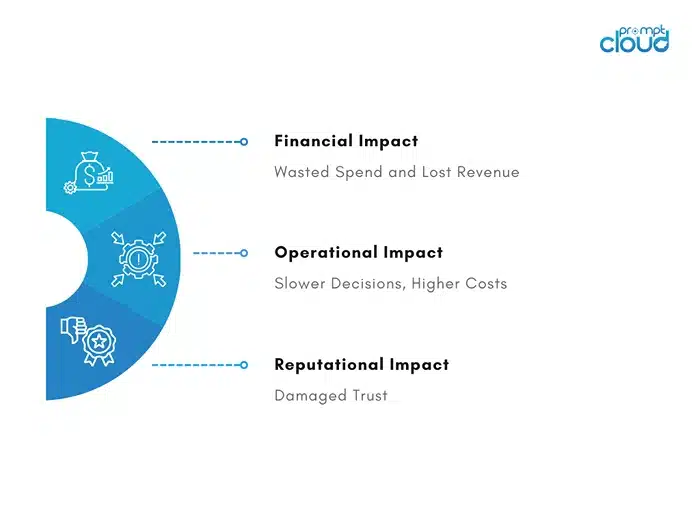
1. Financial Impact: Wasted Spend and Lost Revenue
When your numbers are wrong, your money goes to the wrong places.
- Marketing teams run ads targeting the wrong audience segments because the customer data is flawed.
- Pricing teams slash margins unnecessarily after misreading competitor pricing data.
- Inventory teams order products based on outdated demand signals, tying up cash in stock that won’t move.
We’re not talking hypotheticals here. Gartner pegs the price of bad data at about $12.9 million per year for the average company. IBM’s numbers are just as grim losses of 15–25% of revenue for businesses that don’t manage their data well. That’s revenue you can’t recover.
2. Operational Impact: Slower Decisions, Higher Costs
Bad data creates confusion. Teams spend hours verifying numbers, reconciling conflicting reports, or chasing down missing details. This slows down decision-making and increases the chance of human error.
Think about your analytics team if they’re cleaning data half the week instead of analyzing it, you’re paying for a Ferrari but driving it like a lawnmower. Every delay pushes your response to market changes further behind your competitors.
3. Reputational Impact: Damaged Trust
Customers and partners don’t see your backend systems; they see the end results. If your pricing is inconsistent across channels, product descriptions are wrong, or availability is misrepresented, they don’t think “bad data,” they think “bad company.”
In industries like travel, retail, and finance, trust is currency. Once it’s gone, it’s painfully slow (and expensive) to rebuild. A single mistake can go viral, and it’s not the “source site’s fault” in the customer’s eyes. It’s yours.
The Real Problem? It Compounds
The longer bad data sits in your system, the more damage it does. Forecasts get further from reality. Reports become less reliable. And the business starts making decisions on a foundation of sand. By the time the cracks are obvious, the cost of fixing them is often higher than it would have been to prevent them in the first place.
That’s why prevention through strict data quality checks and a reliable web scraping service provider isn’t just a technical best practice. It’s a strategic necessity.
How to Identify Good Data vs Bad Data: A Practical Checklist
Here’s the truth: you don’t need a data science lab to figure out whether you’re looking at good data or bad data. You just need to know the right questions to ask and to be ruthless in answering them. This isn’t about nitpicking every line of a spreadsheet; it’s about building a quick, repeatable filter that protects your business from the silent bleed of poor data quality.
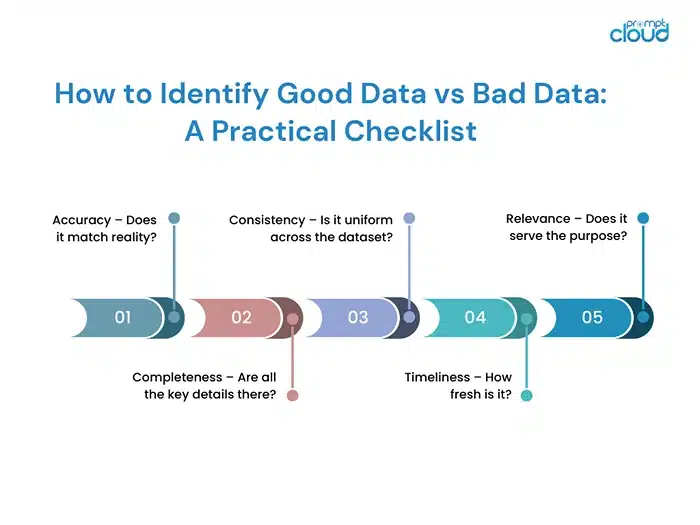
1. Accuracy – Does it match reality?
Check whether the information reflects the real-world truth right now. Are product prices and availability in line with what’s live on the source site? Are names, addresses, and descriptions exactly as they should be? Even small inaccuracies can snowball into big financial mistakes.
2. Completeness – Are all the key details there?
When product data is missing key details like dimensions, materials, or SKU numbers, you’re left guessing on pricing, categorization, and promotion. The same goes for job listings without salary ranges or locations; you’re operating with half the tools you need to get the job done right.
3. Consistency – Is it uniform across the dataset?
Good data follows the same formatting rules from top to bottom. Dates should all follow the same format. Currencies should be labeled and consistent. Units of measurement shouldn’t swap between metric and imperial without warning. Inconsistent data makes automation and analysis far harder.
4. Timeliness – How fresh is it?
Data has a shelf life, and in some industries, it’s shorter than a carton of milk. If your scraped datasets are weeks or months old, they’re already losing relevance. Outdated competitor prices, expired deals, or old product listings all lead to decisions that belong in the “cost of poor data quality” column.
5. Relevance – Does it serve the purpose?
A dataset can be perfectly clean but still useless if it doesn’t match your business needs. If you’re building an e-commerce price tracker, but half the dataset includes unrelated product categories, you’re wasting storage, time, and attention.
Pro Tip:
Don’t treat this checklist like a one-off audit; build it into the way your data flows into your business. That means every new dataset should pass through accuracy, completeness, consistency, timeliness, and relevance checks before it touches your systems. A solid web scraping service provider will have this validation built in, so you get data that’s already vetted and ready to use. If they don’t, you’re not buying a solution, you’re buying another problem to fix.
Good Data vs Bad Data: The Quick Reality Check
| Criteria | Good Data | Bad Data |
| Accuracy | Facts match the real world: product prices, specs, and availability are exactly as they are right now. | Contains errors: wrong prices, incorrect specs, or false availability that mislead your team. |
| Completeness | All key fields are filled: no missing product descriptions, contact info, or category tags. | Gaps everywhere: critical fields are blank, forcing guesswork or manual follow-ups. |
| Consistency | Same formats across the dataset: dates, currencies, and measurements follow a single standard. | Chaotic formats: dates in multiple styles, prices in different currencies without labels. |
| Timeliness | Data is fresh and reflects current market reality, updated on a reliable schedule. | Outdated entries: information from weeks or months ago, long after the market has shifted. |
| Relevance | Directly tied to your business question or use case: no irrelevant clutter. | Filled with noise: unrelated, off-topic, or outdated information that adds confusion. |
Examples of Good Data vs Bad Data in Real Datasets
It’s one thing to talk about good data and bad data, it’s another to see it. Below are two quick examples from industries where data accuracy and structure can make or break decisions.
Example 1: E-commerce Product Pricing Dataset
| Product Name | Price (USD) | Availability | Category | Last Updated |
| Running Shoes X100 | 79.99 | In Stock | Footwear | 2025-08-10 |
| Trail Sneakers Z20 | 89.50 | In Stock | Footwear | 2025-08-10 |
| Marathon Elite Pro | 120.00 | Out of Stock | Footwear | 2025-08-10 |
Why this is good data: Prices are accurate to the current market, categories are consistent, all fields are complete, and the update date shows freshness.
| Product Name | Price | Availability | Category | Last Updated |
| Running Shoes X100 | 75 | YES | Sportswear | 2024-11-02 |
| Trail Sneakers Z20 | NA | In Stock | Footwear/Sports | 2025-02-15 |
| Marathon Elite Pro | Available | — | 2024-09-18 |
Why this is bad data: Prices are outdated or missing, availability is inconsistent (“YES” vs “In Stock”), categories don’t follow a standard format, and some rows have blank fields.
Example 2: Travel Accommodation Listings Dataset
| Hotel Name | City | Room Type | Price Per Night (USD) | Availability | Last Updated |
| Oceanview Inn | Miami | Deluxe King | 250 | Available | 2025-08-11 |
| Mountain Escape Lodge | Denver | Standard Queen | 150 | Limited Rooms | 2025-08-11 |
| City Central Hotel | New York | Suite | 300 | Available | 2025-08-11 |
Why this is good data: Consistent formatting, complete details for each listing, accurate pricing, and up-to-date availability.
| Hotel Name | City | Room Type | Price Per Night | Availability | Last Updated |
| Oceanview Inn | Miami, FL | — | $250 | Yes | 2024-10-05 |
| Mountain Escape Lodge | — | Queen | NA | Sold Out | NA |
| City Central Hotel | New York City | — | 300.00 | Vacant | 2024-06-12 |
Why this is bad data: Missing room types, inconsistent city naming, outdated prices, mismatched availability terms (“Yes” vs “Available” vs “Vacant”), and missing update dates.
This kind of side-by-side makes it easy to spot the data discrepancy issues that creep into scraped datasets. When you can see the difference in black and white, it’s clear why working with a reliable web scraping service provider pays off; they prevent these errors from ending up in your decision-making pipeline.
How a Web Scraping Service Provider Helps Maintain Data Quality
Here’s the thing: collecting data is easy. Dozens of DIY tools and scripts can pull content from websites. But collecting good data? That’s a whole different game. That’s where a professional web scraping service provider earns their keep.
In-house scraping can feel like whack-a-mole. One day the script’s fine, the next a layout change wipes out half your fields. By the time you notice, you’ve got a CSV filled with empty cells and repeated records, and it’s being used to plan next quarter’s numbers.
A good provider prevents this mess before it happens. Here’s how:
1. Built-In Quality Checks at Every Stage
Instead of handing you raw, unfiltered data, a professional provider runs automated and manual validation before delivery. This means every field gets checked for accuracy, completeness, and consistency. Errors get fixed before they ever hit your system.
2. Smart Deduplication and Data Normalization
Duplicate entries and mismatched formats are two of the most common data quality issues in scraping. A strong provider removes duplicates automatically and ensures that formats, from dates to currency values, are standardized across the dataset. That way, your team doesn’t waste days cleaning before they can even start working.
3. Timely Updates with Flexible Scheduling
Freshness is non-negotiable. The right provider adapts scraping frequency to your industry’s pace. For e-commerce pricing, that might mean daily or even hourly updates. For real estate listings, it could be weekly. They make sure you’re not making decisions on outdated snapshots of the market.
4. Handling Data Discrepancy at the Source
When pulling from multiple websites, formatting conflicts are inevitable. A good web scraping service provider cleans and aligns the data so that “In Stock” on one site and “Yes” on another both map to the same standardized field. This prevents reporting chaos later.
5. Structured Delivery That Fits Your Workflow
Clean data isn’t just about accuracy; it’s about usability. Providers like PromptCloud deliver structured datasets (JSON, CSV, XML, or API feeds) that slot directly into your systems, dashboards, or analytics tools without extra transformation work.
When you’re comparing providers, this is what you should be looking for. If they’re just giving you a dump of raw scraped HTML, you’re buying yourself a clean-up project, not a usable dataset. The real value of a web scraping partner is in their ability to guarantee data quality, so your business decisions are based on reality, not on guesswork.
Real-World Example: The Difference Good Data Makes
Let’s put this into perspective with a scenario that plays out more often than most businesses care to admit.
The E-commerce Pricing Trap
A mid-sized online retailer decides to adjust prices based on competitor data scraped from various marketplaces. They’re using an in-house script that runs twice a week. Everything looks fine on the surface until sales start dipping.
Why?
Half of their “competitor price drops” were false. Some prices were scraped during flash sales that ended hours later. Others came from outdated listings or mismatched product variants. The result? They slashed their own prices unnecessarily, eroding margins and training customers to wait for constant discounts.
The Financial Hit: Over a single quarter, they lost an estimated 12% in potential revenue.
Now, the same scenario with good data:
They switch to a web scraping service provider that:
- Updates competitor data daily.
- Normalizes variants to match like-for-like products.
- Flags temporary promotions separately from standard pricing.
- Delivers structured data directly into their pricing engine.
This time, pricing adjustments are based on accurate, verified information. They undercut competitors strategically without triggering a price war. Margins stabilize, and profits climb back.
The Gain: A 9% margin improvement in the first 60 days, without losing competitive edge.
The Lesson?
The cost of poor data quality isn’t theoretical; it’s measurable, and it hits your bottom line fast. Bad data creates reactionary decisions. Good data gives you control. And in industries moving at the speed of e-commerce, travel, or finance, that control is the difference between winning the quarter and writing it off as a loss.
Data Quality Decides Who Wins
In business, speed matters, but only if you’re running in the right direction. Bad data pushes you to move quickly in the wrong direction. It blurs your perspective, skews your reports, and quietly drains your resources before you notice the damage.
With good data, it’s like navigating with a map you can actually trust. Pricing decisions, growth strategies, all of it is tied to reality, not to blind assumptions. The difference between the two isn’t luck; it’s process, discipline, and choosing the right partner to deliver data you can trust.
If you’re scraping data at scale, the risk of poor data quality isn’t a small technical hiccup; it’s a strategic threat. And the fastest way to turn that threat into an advantage is by working with a web scraping service provider that doesn’t just collect data but delivers it clean, accurate, and ready for action.
Because at the end of the day, the question isn’t whether you can afford good data.
It’s whether you can afford the cost of bad data.
Stop letting bad data make expensive decisions for you. Talk to us today and get clean, structured, and reliable datasets that put you in control.
FAQs
1. What are the most common signs of bad data in business datasets?
You’ll usually spot bad data through obvious gaps or mismatches, missing fields, outdated prices, inconsistent formats, or numbers that don’t line up with what’s live online. Sometimes it’s subtler: your reports start telling conflicting stories, or your team keeps double-checking the same details. Those are red flags that the foundation you’re working on might be shaky.
2. How does poor data quality impact ROI?
Bad data isn’t just an annoyance; it directly eats into ROI. Marketing spend gets wasted targeting the wrong audience. Inventory dollars get tied up in products nobody wants. Pricing adjustments happen based on outdated competitor info. Each bad decision chips away at returns, and the effects add up fast.
3. Can a web scraping service provider guarantee accurate data?
No provider can promise perfection 100% of the time, but a good one will come close. They’ll build in validation, deduplication, and formatting checks so most errors are caught before you ever see the data. The right partner also adjusts scraping frequency to keep information fresh, a big factor in overall accuracy.
4. How often should data be updated to avoid quality issues?
There’s no magic number; it’s about how quickly things change in your world. In e-commerce or travel, prices can move by the hour, so scraping once a week is basically serving leftovers. In slower industries, weekly or even monthly might be fine. The rule? Update often enough that your decisions are based on today’s reality, not last month’s.
5. What’s the best way to check for data quality issues after scraping?
Start small, pick a handful of entries, and compare them directly with the source. Do the details match? Are any fields missing? Any duplicates? If you keep seeing the same errors, the scrape setup probably needs tweaking. And if you’re paying a web scraping service provider, make them show you their quality checks; you’ll see right away if they’re catching problems before they hit your desk.















