




AI models are only as good as the data they learn from. But what happens when these companies run into a wall with their in-house data? Many AI teams reveal difficulties to train AI models due to restrictive, incomplete, or conceptually outdated data. This limitation is referred to as AI data bottleneck, which significantly hinders sustained performance and innovation.
The solution? External data. Incorporating data from outside the company mitigates obsolete internal datasets and enhances the accuracy and scalability of AI models. In this guide, we will take you through the process of how to train AI models with external data, examine their benefits, and present the most effective ways to maximize efficiency.
What is AI Data Bottleneck?
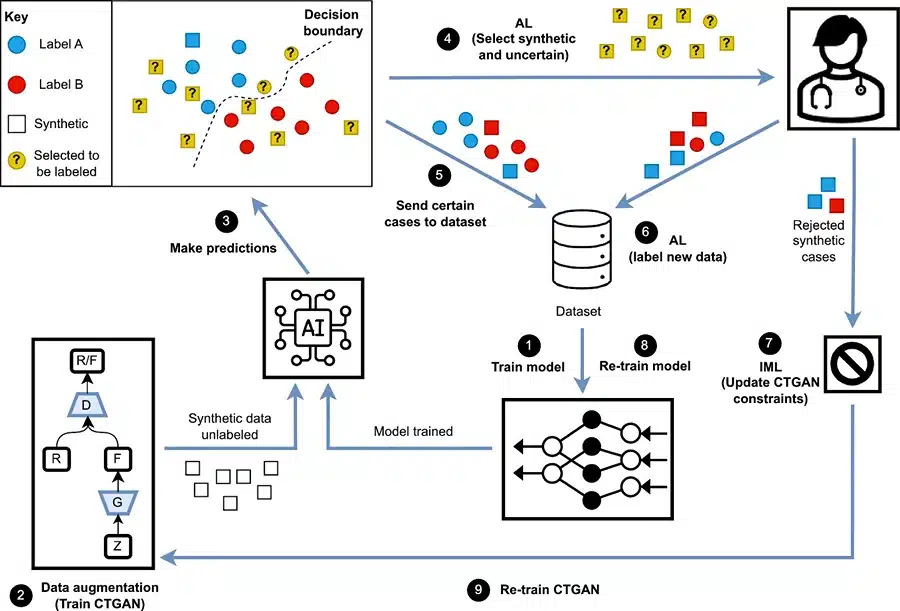
Image Source: Springer
Having extensive datasets available for training is central to the success of an AI model. An increasing volume of data helps AI models learn to detect meaningful patterns, make reasoned decisions, and progressively improve their performance and accuracy.
The unfortunate reality, though, is that most companies are constricted by an abysmal lack of data, compounded with incompatibility with AI technology that reduces their ability to train AI effectively. These constraining factors consist of:
- Limited internal data: Many organizations are not able to generate enough value data within themselves, which can train AI models. This phenomenon is more common among emerging businesses venturing into different geographies, such as startups.
- Data bias: An incomplete source of known data often has training data that comes from a single source. This type of training data is said to suffer from bias due to inaccurate prediction or poor generalization.
- Outdated information: AI models need data for relevancy. Models that operate best on outdated data because they do not positively adapt to changes are said to rely on changing data.
- Compliance and privacy concerns: There are some sectors like health care and finance where data management laws and policies are stringent on how data is collected and utilized. This creates a restrictive environment for adequate access to adequate data for training purposes.
Failure to address such concerns exposes the AI team to the risk of developing models that pass all the testing scenarios yet underperform in reality. In this case, external data is of great importance.
How External Data Helps Train AI Models
To scale AI model training and break through bottlenecks, companies can leverage external data sources. These datasets can:
- Expand data volume: Supplementing datasets aims to increase the amount of training data that a model has. This helps in making the AI models more efficient.
- Improve data diversity: Utilizing many sources to train AI ensures that there is enough reduction of scope as well as enhancement in the strength of the model.
- Keep AI models updated: Regularly incorporating fresh external data helps AI models stay relevant in dynamic industries like finance, retail, and healthcare.
- Enhance real-world applicability: AI models perform better in different environments and with varying behaviors from users when trained on multi-faceted datasets.
But where can companies find the right external data for AI training?
Best Sources of External Data for AI Training
In order to successfully train AI models, reliable and quality external data is a necessity. Some of these include:
1. Public Datasets
Data sets that are collected and released by research bodies, government agencies, and other organizations can be instrumental when training AI. Some of these datasets include:
- Google Dataset Search – A search engine for public datasets.
- Kaggle Datasets – A compilation of datasets enlisted for the purpose of machine learning.
- Open Data Portals –Datasets released by different governments and institutions and pertain to areas such as economics, demographics, climate, and many more.
2. Web Scraping
Collecting data in the form of web scraping enables a company to have access to real-time information from social media, news pages, e-commerce data, and websites. This is very helpful in:
- Training AI models on NLP(s) algorithm with tons of text data from the internet.
- Teaching computer vision models advanced image datasets from different platforms.
- Enhancing e-commerce recommendation systems by evaluating trends and changes in product pricing.
3. Data Marketplaces
Companies purchase data from data marketplaces such as AWS Data Exchange, Snowflake Data Marketplace, and Quandl. These platforms provide structured and pre-cleaned datasets for different industries.
4. Crowdsourced Data
Some companies gather labeled data through crowdsourcing. Amazon Mechanical Turk and Figure Eight provide businesses with human-annotated data meant to train AI.
5. Industry-Specific Data Providers
Several industries have specialized data providers offering tailored datasets aimed at AI training. As an example, consider the following:
- Healthcare: Medical imaging datasets for AI-powered diagnostics.
- Finance: Market data for predictive analytics.
- Retail: Consumer sentiment and purchasing trends.
By leveraging various sources, AI teams can maintain a consistent supply of high-quality data for training purposes.
Challenges of Using External Data (And How to Overcome Them)
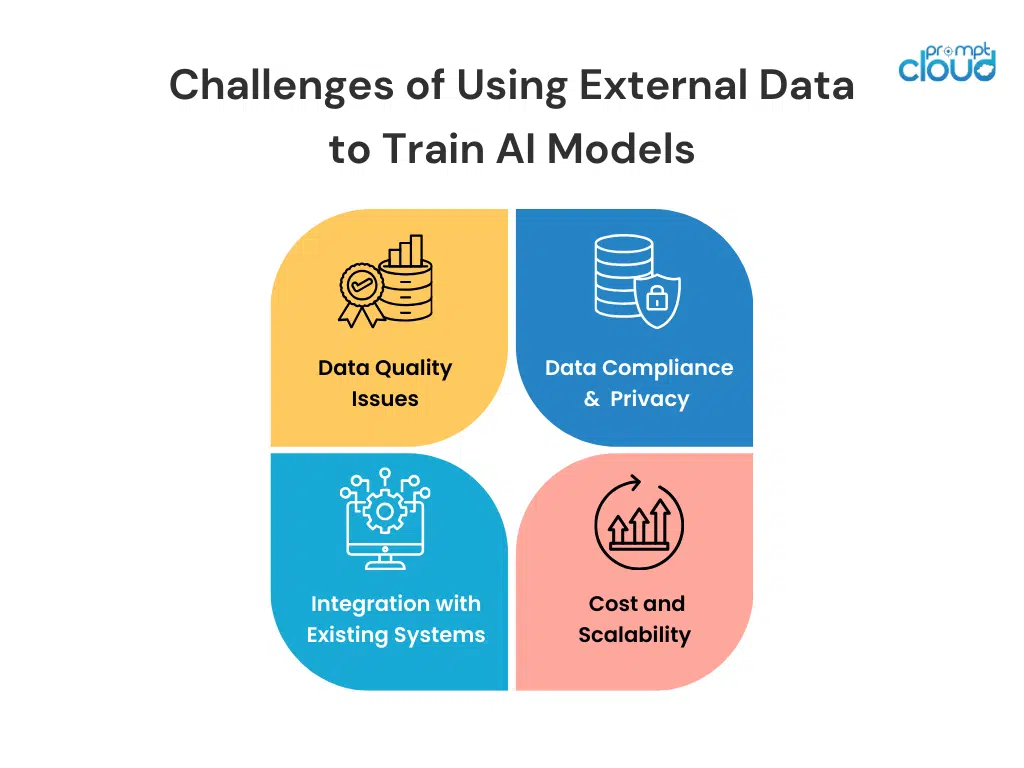
Despite the benefits external data provides to training AI, it comes with its own set of complications. Here is how to deal with them:
1. Data Quality Issues
In some and most cases external data is not useful and comes unorganised. Poor-quality datasets can negatively affect the outcome of model performance.
Solution: Using data preprocessing methods for cleaning, normalizing, and removing duplicates improves the consistency and accuracy of data prior to application in AI models.
2. Data Compliance and Privacy Concerns
When external data is used, there’s a possibility of breaching regulations like GDPR, CCPA, and other data privacy laws.
Solution: Partner with trusted data vendors that are compliant with set regulations. Confirm the anonymization and encryption of sensitive information.
3. Integration with Existing Systems
Pre-existing external datasets could differ in structure from the internal data, which creates challenges for integration.
Solution: Use ETL (Extract, Transform, Load) tools to first structure external data to fit the internal datasets before AI model training.
4. Cost and Scalability
Costs may rise significantly when dealing with large volumes of external data for acquisition and processing.
Solution: Use more budget-friendly data. Also, leverage cloud-based infrastructure to expand AI training resources without raising capital infrastructure expenditures.
How to Train an AI Model with External Data
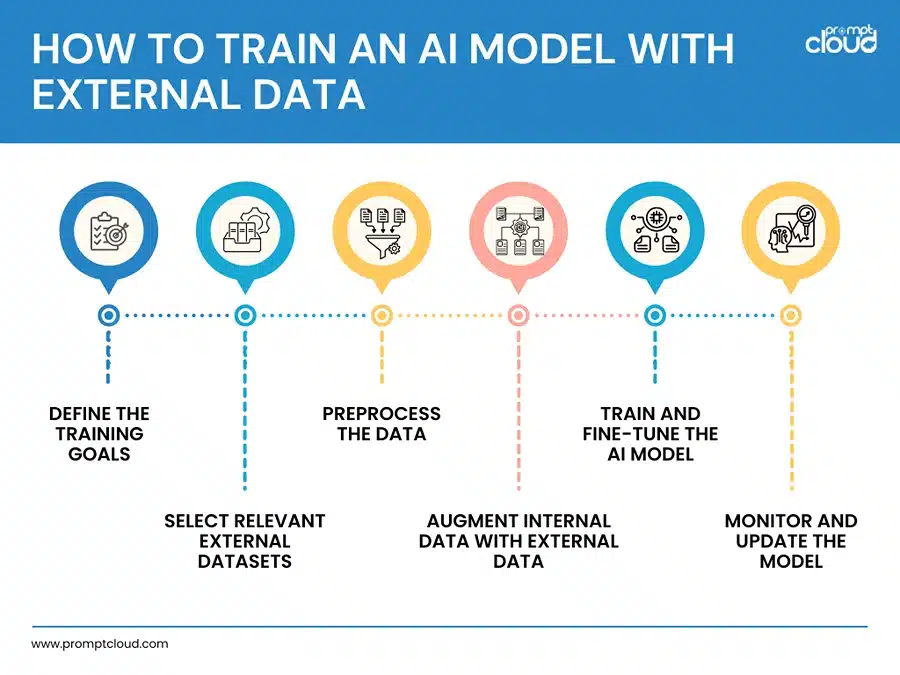
Once you have access to external data, the next step is integrating it into your AI training pipeline. Here’s a streamlined approach:
Step 1: Define the Training Goals
Identify what you want the AI model to achieve. Be it image recognition, language processing, or prediction, and outline all necessary steps to take including data sourcing externally.
Step 2: Select Relevant External Datasets
Pick selected datasets that aid in achieving primary AI goals. Ensure these datasets are of wide scope, up-to-date, and maintained to remove chances of bias or inaccuracies.
Step 3: Preprocess the Data
For optimal performance, structure and clean any external data before feeding it to the AI. Remove duplicate entries, fill any gaps, and standardize the differing data formats for consistency.
Step 4: Augment Internal Data with External Data
The model’s performance is improved by merging both the internal and external datasets. This practice enhances generalization and mitigates the likelihood of overfitting.
Step 5: Train and Fine-Tune the AI Model
Use the augmented dataset to train AI models. Cross-validation with diverse model instantiations is applied to ensure accuracy, tuning parameters where necessary.
Step 6: Monitor and Update the Model
There is a need to ensure constant learning feedback loops with the AI models. Updating the training data with fresh outside datasets at frequent intervals helps keep the model relevant and accurate.
Conclusion
For businesses that aspire to design high-performing models, uncloging the bottleneck created by the data silo is imperative. The efficiency with which AI can be trained, as well as the biases surfaced, and the accuracy in practical applications is improved through the use of external data.
Acquiring data from public datasets, web scraping, data marketplaces, and industry-specific data providers allows businesses to overcome data constraints, efficiently accelerating the process to train AI.
With continuous development in AI technologies, the ease with which a company can access and integrate different data sources will influence its innovative capacity. Should your company intend to enhance the efficacy of AI algorithms with sophisticated external datasets, then developing a robust data acquisition plan is essential.Looking to train AI models with high-quality external data? PromptCloud can help you collect, clean, and structure large-scale datasets tailored to your AI needs. Contact us today!















