




Over the past two decades, PromptCloud, we witnessed the growth of social media from merely a medium of communication with our friends and family to the central storehouse of our digital memories. Every fun-filled vacation, visit the favorite travel destination, family get-togethers including random thoughts flashing through the mind get logged into our favorite social media site.

Sometimes, the digital world that has become intertwined with our real lives can completely erase the precious memories if the site decides to shut down (which is actually quite common on the internet). This was exactly the case when we received an unusual yet interesting requirement from San Francisco recently.
We received an email from Ms. Gail Williams in which she mentioned how she wanted to rescue her mom’s memories posted on a photo-sharing website called eternity in the form of images, stories, and comments. Gail’s 86-year-old mom has been using this site as her medium to share travel photos and stories which makes up most of the content she wanted to extract. As eternity faces shutdown unless new ownership arises in the next days and weeks, she was looking for a way to extract and save this data before it’s lost forever.
Now, PromptCloud being a web crawling solution particularly suitable for large scale and recurring requirements, a one-time crawl like this is not something we would normally take up. However, the unique nature of the requirement and the emotional motive behind it forced us to make an exception. We decided to send out our army of crawlers to rescue MeadowMom’s memories from the soon to be shut down eternity, once and forever.
Here is a screenshot from one of her albums:
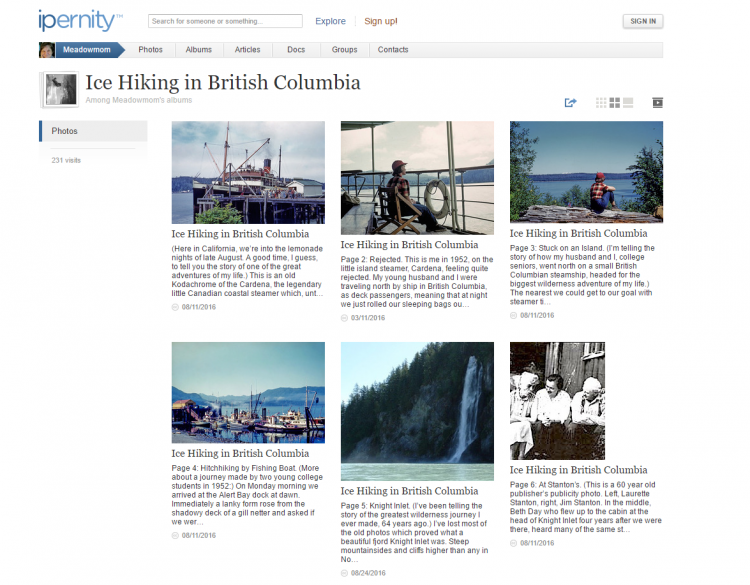
Emails were exchanged and our team collected all the bits of information from Gail that was required to get started with the setup process. It won’t be an exaggeration to say that we were all really excited to work on this unique project.
Finally, our tech team deployed the crawler bot army and successfully rescued about 4700 albums each containing images, stories, and comments from eternity, within the next few days. Finally, the data was delivered in CSV format.
Here is the picture of a PromptCloud bot getting ready for the rescue mission.

At the end of the day, it was all about the satisfaction that we derived from helping someone save the memories that are so dear to them. Currently, Gail is working on building a new home for this data – a website which we will update in this article as soon as it’s up and running.















