




**TL;DR**
Most price trackers still run on a timer—hit every page every few hours and compare later. The problem: ecommerce doesn’t wait. Prices can shift mid‑day, stock can vanish in minutes, and flash promos come and go between cron runs. An event‑driven approach turns that on its head. Instead of crawling everything on a schedule, your scraper listens for change signals—webhooks, lightweight feeds, or on‑page update flags—and only pulls the SKUs that actually changed.
Why “Scheduled” Price Monitoring Is Failing You
If you’re still scraping every 6 or 12 hours on a cron job, you’re already behind.
Most pricing intelligence systems today still run on schedules: a scraper hits the PDP, grabs the price, checks stock, and repeats every few hours. But ecommerce doesn’t work on a schedule anymore. It’s event-driven:
- Competitors roll out flash sales without notice
- Out-of-stock status flips after one influencer post
- Dynamic pricing scripts adjust prices based on user behavior or cart velocity
- Sellers silently undercut MAP policies outside business hours
In a scheduled setup, these events go undetected for hours. By the time your cron job catches the change, your competitor already won the click.
The Cost of Delayed Data
- Late Repricing: Your algorithm uses stale competitor prices and miscalculates margins
- Stock Blind Spots: You recommend or bundle items that are no longer available
- MAP Violations Missed: Enforcement windows pass before you even scrape the evidence
- Crawl Redundancy: You re-scrape thousands of unchanged pages every hour—wasting resources
What’s Changing in 2025?
- Brands are pushing toward real-time SKU intelligence: Price and availability changes are now operational triggers—not just analytics inputs.
- ESLs (Electronic Shelf Labels) and APIs are triggering micro-updates: Some modern ecommerce stacks expose deltas via feeds or content APIs. Scrapers need to plug in and react, not poll.
- Speed matters more than completeness: A partial, fresh diff (just the updated SKUs) is more valuable than a full scrape delayed by hours.
This is where event-triggered scraping pipelines come in.
Want real‑time price & stock alerts without building your own pipeline?
While DIY screen scraping works for small datasets and short-term extraction, enterprise-grade data requirements introduce challenges like anti-bot defenses, schema drift, and continuous data reliability. Most enterprise teams evaluate build vs buy data pipeline models to determine total cost of ownership.
What Is Event‑Triggered Scraping in Price Monitoring?
Event‑triggered scraping flips price tracking from polling on a timer to reacting on a signal. Instead of hitting 50,000 PDPs every 6 hours “just in case,” you listen for change events—then scrape only the SKUs that moved.
Common triggers:
- Webhooks/feeds: Vendor change feeds, sitemaps with <lastmod>, price/stock RSS, or a partner’s content API delta endpoint.
- On‑page deltas: PDP JSON blobs (e.g., window.__STATE__) that expose price_updated_at or inventory.version.
- Observability signals: Spike in “price”/“availability” keywords on a brand’s updates page, or edge logs showing 304→200 flips for SKU URLs.
- ESL/ERP events: Electronic Shelf Label or ERP messages indicating retail price/stock changed (useful for omnichannel parity checks).
Why it wins:
- Faster: Detect within seconds/minutes, not hours.
- Cheaper: Touch 2% of pages that changed, skip the 98% that didn’t.
- Cleaner: Diffs force you to track what, when, and why a value changed—perfect for pricing intelligence and audits.
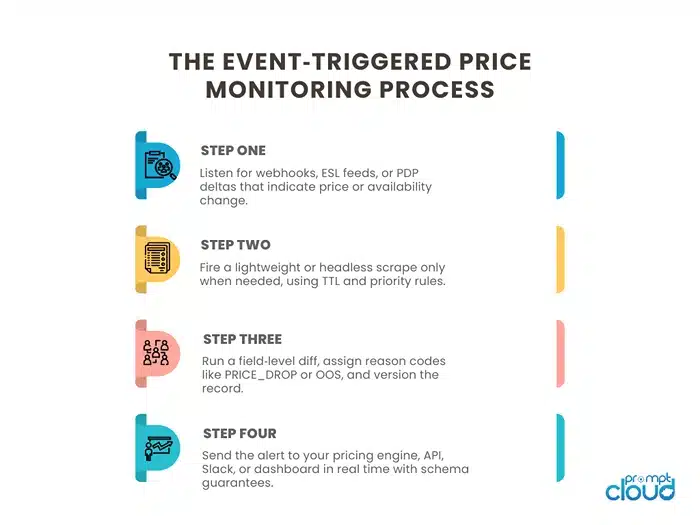
What a Real Event‑Triggered Price Pipeline Looks Like
1) Trigger layer (ingest)
- Accept webhooks (HTTP POST), poll light‑weight feeds, and watch sitemaps’ lastmod.
- Normalize into a common event:
{ sku, url, fields:[“price”,”availability”], change_hint, event_ts }
2) Queue & controls
- Priority: price > availability > metadata.
- TTL: drop events older than, say, 20 minutes for flash‑sale SKUs.
- Idempotency key: hash(sku,url,event_ts_bucket) to prevent duplicate scrapes.
- Backpressure: slow non‑critical brands first when queues surge.
3) Scraper orchestration
- Start cheap: HTTP fetch + JSON parse.
- Escalate on failure: headless render → alt proxy/region → mobile profile.
- Concurrency caps per domain; jittered retries with ceilings.
4) Diff engine
- Compare new fields to last good snapshot:
- price_old → price_new, in_stock_old → in_stock_new, promo_badge toggles.
- Emit reason codes: PRICE_DROP, OOS, BACK_IN_STOCK, COUPON_APPLIED.
5) Delivery
- Hot path: push just the changed SKUs to a webhook/API topic within seconds.
- Cold path: enrich (seller graph, coupon parse), then batch to S3 hourly.
- Publish contracts (JSON schema) with versioning for downstream apps.
6) Governance & QA
- Field validators (price numeric, currency present, stock ∈ {0,1,low}).
- Freshness SLOs (e.g., 95% of price changes delivered <5 minutes).
- Audit trail: scrape_ts, proxy region, selector version, checksum.
If you’re evaluating event‑driven price tracking, this guide to real‑time price tracking software for dynamic pricing breaks down how teams wire alerts into actual repricing moves.
Minimal Event → Action Example (pseudo)
POST /price-events
{
“sku”:”SKU123″,
“url”:”https://brand.com/p/sku123″,
“fields”:[“price”,”availability”],
“change_hint”:”price”,
“event_ts”:”2025-09-21T06:30:00Z”
}
Queue assigns priority=high, TTL=20m, idempotency=SKU123|price|2025-09-21T06:30.
Scraper fetches, finds price: 899 → 799, emits:
{
“sku”:”SKU123″,
“url”:”https://brand.com/p/sku123″,
“diff”:{“price”:{“old”:899,”new”:799}},
“reason”:”PRICE_DROP”,
“scrape_ts”:1695287400,
“schema_version”:”price_v2″,
“provenance”:{“region”:”IN”,”method”:”http”,”selector_rev”:”r14″}
}
Hot‑path delivery posts to your pricing engine; cold path batches to S3 with checksums.
Cron vs Event‑Driven: When Each Fits
- Cron (polling): good for small catalogs, stable sites, or compliance snapshots (e.g., nightly MAP audits).
- Event‑driven: best for competitive categories, flash sales, marketplaces, and omnichannel stock where minutes matter.
Most mature teams blend both: lightweight cron as a safety net (catch missed events), event‑driven for speed and cost.
Event triggers shouldn’t stop at price; this real‑time SKU tracking piece shows how brands act on back‑in‑stock and low‑inventory signals before they become lost sales.
Designing Diff‑Based Alerts That Teams Actually Use
Most “price change” alerts end up muted because they’re noisy or late. The goal isn’t more alerts—it’s actionable diffs that route to the right system with the right priority.
What counts as a useful diff
- Field‑scoped: price, availability, seller, coupon, shipping fee, unit price.
- Magnitude‑aware: ignore ±1 currency unit if your pricing rules don’t react at that granularity.
- Reason‑coded: PRICE_DROP, BACK_IN_STOCK, MAP_VIOLATION, COUPON_ADDED, PRICE_PER_UNIT_CHANGE.
- Contextualized: include last verified time, region, seller type (1P/3P), and promo window if visible.
Suppression and routing
- Deduplicate: idempotency keys like sku|field|ts_bucket.
- Coalesce: collapse n updates in 5 minutes into one event with min/max and first/last snapshot.
- Thresholds: only alert if price delta ≥ X% or if availability flips state.
- Routing: send high‑priority diffs to pricing engine; low‑priority to analyst Slack; compliance events to a MAP inbox.
Minimal diff schema (hot‑path JSON)
{
“sku”: “SKU123”,
“url”: “https://brand.com/p/sku123”,
“region”: “IN”,
“diff”: {
“price”: {“old”: 89900, “new”: 79900, “currency”: “INR”},
“availability”: {“old”: “in_stock”, “new”: “in_stock”}
},
“reason”: [“PRICE_DROP”],
“seen_at”: “2025-09-21T06:35:12Z”,
“idempotency_key”: “SKU123|price|2025-09-21T06:35”
}
Webhooks, Content APIs, and ESL Signals: How to Wire the Triggers
Event sources vary by brand, marketplace, and vendor. Treat them as interchangeable triggers that all normalize to the same internal event.
Common trigger sources
- Webhooks/feeds: vendor or partner notifies “SKU updated.”
- Content APIs: delta endpoints expose updated_since cursors.
- Sitemaps: <lastmod> changes for PDPs or offer pages.
- ESLs/ERP messages: store or DC systems emit price/stock changes.
- Observer probes: lightweight HEAD/GET checks on known hot SKUs.
Normalization pattern
# Pseudocode: normalize any trigger to a common event
def normalize_trigger(payload):
return {
“sku”: payload.get(“sku”) or infer_sku(payload),
“url”: payload.get(“url”),
“fields”: payload.get(“fields”, [“price”,”availability”]),
“change_hint”: payload.get(“hint”,”unknown”),
“event_ts”: payload.get(“ts”) or now_iso()
}
Push the normalized event to your queue with priority, TTL, and an idempotency key. From there, the scraper orchestration and diff engine do the heavy lifting.
Sample: Lightweight Webhook Receiver + Diff Check
Below is a compact example you can adapt. It accepts a webhook, fetches a PDP JSON blob first (cheap path), falls back to headless scraping only if needed, then emits an actionable diff.
# requirements: fastapi, httpx, pydantic, aioboto3 (optional for S3)
from fastapi import FastAPI, Request
from pydantic import BaseModel
import httpx, time
app = FastAPI()
class PriceEvent(BaseModel):
sku: str
url: str
fields: list[str] = [“price”,”availability”]
event_ts: str
def last_snapshot(sku): # replace with your store
# return most recent known record
return {“price”: 899.0, “availability”: “in_stock”, “seen_at”: 1695287000}
async def cheap_fetch(url):
# try to read embedded JSON without headless
async with httpx.AsyncClient(timeout=10) as client:
r = await client.get(url, headers={“User-Agent”:”Mozilla/5.0″})
r.raise_for_status()
# naive parse for on-page JSON; replace with your logic
# return {“price”:…, “availability”: …}
return {}
def diff(old, new):
d = {}
if “price” in new and new[“price”] != old.get(“price”):
d[“price”] = {“old”: old.get(“price”), “new”: new[“price”]}
if “availability” in new and new[“availability”] != old.get(“availability”):
d[“availability”] = {“old”: old.get(“availability”), “new”: new[“availability”]}
return d
@app.post(“/webhooks/price”)
async def receive(ev: PriceEvent):
snapshot = last_snapshot(ev.sku)
data = await cheap_fetch(ev.url)
if not data:
# enqueue fallback: headless render job (not shown)
return {“status”:”queued_headless”}
d = diff(snapshot, data)
if not d:
return {“status”:”no_change”}
out = {
“sku”: ev.sku,
“url”: ev.url,
“diff”: d,
“reason”: [k.upper() for k in d.keys()],
“scrape_ts”: int(time.time()),
“schema_version”: “price_v2”
}
# deliver hot-path (webhook, Kafka topic, etc.)
return {“status”:”delivered”, “event”: out}
This pattern keeps costs down by avoiding headless unless necessary, while still producing reason‑coded diffs fast enough for pricing engines.
Service Level Objectives (SLOs) for Price Monitoring
Define explicit freshness and accuracy targets so commercial decisions aren’t made on stale data.
- Freshness: 95% of price changes delivered within 5 minutes; 99% within 15 minutes.
- Completeness: ≤1% of changed SKUs missed per day (caught by safety‑net cron).
- Accuracy: Price fields must be numeric with currency; availability ∈ allowed states.
- Reliability: Queue wait <60s at p95 during peak events; retry cap 3 tiers.
Tie alerts to SLO breaches, not just scraper errors. For example, page success might be 200 OK, but if freshness p95 slips beyond target, that’s an incident.
For a retailer’s view (cadence, coverage, workflows), see why every retailer needs an ecommerce price monitoring tool—it maps neatly to the trigger‑first model we’re outlining.
When to Blend Cron with Events
Use low‑frequency cron as a safety net:
- Catch missed events or vendor webhook outages.
- Re‑verify hot SKUs nightly to reset drift.
- Rebuild baselines after promotions.
Keep it light—cron should sample, not redo your entire catalog. Event triggers carry the workload; cron guards your blind spots.
Read more: W3C WebSub (formerly PubSubHubbub)—a spec for distributing change events over HTTP webhooks. It’s a clean reference for “event‑driven updates” as a web primitive.
Switching to Event‑Triggers: How to Make the Move
Many teams feel stuck in scheduled scrapes because that’s what their stack is built around. Moving toward event‑triggered monitoring means re‑architecting around signals & alerts, not fixed cron schedules. Here’s a step‑by‑step plan:
- Map all available event sources: Identify any vendor webhooks, sitemaps/feeds, content APIs, or ESL/ERP signals. Even if they only cover part of your catalog, they’ll reduce load and latency.
- Build lightweight ingestion + normalizing layer: Normalize triggers from different sources into a consistent schema: SKU or identifier, URL, fields expected to change, and timestamp.
- Set up a diff engine: Store last known snapshots of price/availability. When an event arrives, fetch current data, compare to snapshot, and emit reason‑coded diffs (price up/down, back in stock, out of stock, etc.).
- Choose hot vs cold paths
- Hot path: immediate dispatch of critical diffs via webhooks or streaming channels.
- Cold path: batch enrichment, analytics, or fallback cron to catch misses.
- Optimize observability and SLAs: Track freshness (how long from actual change to detection), delivery latency, error rates (failed fetches, blocked pages), and downtime of event sources.
If you already ingest Shopping data, this walkthrough on optimizing your Google Shopping feed and tracking prices shows how teams pair feed changes with webhooks for faster diffs.

Common Failure Modes in Event‑Driven Price Monitoring (and How to Prevent Them)
Even with real-time pipelines, failure is still possible. But it’s usually preventable—if you know what to watch for. Here’s a breakdown of the most common issues that break event-triggered price monitoring systems and what to do about them:
Failure Mode Table
| Failure Type | Trigger | Symptoms | Root Cause | Prevention | Detection |
| Template Drift | Site layout change, JS bundle update | Empty fields, wrong field values, parser fails | Hard-coded selectors, brittle CSS paths | Use visual/semantic selectors; run sentinels | Monitor selector coverage, diff null rates |
| Pagination Broken | Load more button changes, offset param changes | Missing SKUs, partial catalog scrape | No fallback; relying on static page counts | Fallback to inferred count; loop detection | Track SKU count variance vs baseline |
| Price Encoding Issues | Currency symbol/image, script-wrapped price | “N/A” or 0 price; wrong format in output | Didn’t parse HTML-to-text layers properly | Normalize all price fields; add regex fallback | QA field length, unit presence, decimal check |
| Overwrites / Old Data | No TTL, duplicate jobs, bad version merge | Old price overrides fresh one | No idempotency or timestamp in record | Use TTL, idempotency keys, crawl_ts | Compare timestamps in delivery log |
| Missed Diffs | Partial field change, cosmetic-only HTML diff | No alert fired despite actual change | Diff engine not field-aware | Field-level diffs, not DOM hash diffs | QA alerts vs known updates (control SKUs) |
Bonus Resource: Full Pipeline Architecture from LLM Agent Blog
For a broader view of real-time, event-driven scraping (especially when routing via queues, backpressure systems, and retry trees), refer to this detailed breakdown from PromptCloud’s article on LLM data pipelines – Real Time Web Data Pipelines for LLM Agents: Event driven scraping architectures. It covers:
- Canary triggers
- Shadow releases
- TTL + escalation chains
- Dead letter queues
- Proxy-aware routing
- Structured delivery to S3/API
The architecture is nearly identical to what pricing teams need—just swap the LLM agent for a repricing engine or MAP compliance monitor.
The Real Shift: Pricing Intelligence as a Live Signal, Not a Report
The biggest mistake ecommerce teams make with price monitoring? Treating it as a reporting tool instead of a live input into revenue decisions. Pricing intelligence isn’t just a dashboard you check at the end of the day. It’s becoming a triggering mechanism for automated actions:
- Dynamic repricing rules fire when competitors drop below threshold
- MAP enforcement tickets open when a SKU dips under minimum pricing for more than X minutes
- OOS back-in-stock alerts route to paid campaigns or merchandising ops to resume promotions
- Price-based segmenting routes real-time SKUs to different LLM-based product descriptions or storefronts
This is where static CSVs and fixed cron scraping cannot compete. You don’t need “all the data later.” You need the right changes now.
Teams That Are Doing This Well
Forward-looking brands are already adapting:
- Consumer electronics teams use ESL integrations and webhook-triggered scraping to reroute bundles and accessories dynamically.
- Grocery & quick commerce players are tracking OOS signals + price shocks (e.g., onion price spikes) to flag loss-leader strategies or reduce ad spend waste.
- Fashion retailers use real-time stock drops to kill paid ads or pause influencer traffic.
They’re not checking this data at end-of-day. They’re wiring it into live systems that adapt.
Final Word
You don’t need to rip out your current system to get started. Even 10% event coverage—on your highest-margin SKUs or most-volatile categories—can improve pricing response times dramatically. Let the rest run on cron until your pipelines catch up.
The goal of Pricing Intelligence 2.0 isn’t just faster alerts. It’s actionable change, embedded where decisions are made—in pricing engines, promotion rules, ad budgets, and competitive strategy.
Want real‑time price & stock alerts without building your own pipeline?
While DIY screen scraping works for small datasets and short-term extraction, enterprise-grade data requirements introduce challenges like anti-bot defenses, schema drift, and continuous data reliability. Most enterprise teams evaluate build vs buy data pipeline models to determine total cost of ownership.
FAQs
1. What is event-triggered price monitoring?
Event-triggered price monitoring uses webhooks or change signals to detect price and availability changes in real-time, instead of relying on scheduled scraping.
2. How does diff-based price alerting work?
Diff-based alerts compare the latest scraped data to a prior snapshot. Only meaningful changes—like price drops or stock flips—trigger alerts with reason codes.
3. Why are cron jobs no longer enough for ecommerce scraping?
Cron jobs often miss flash sales, MAP violations, or stock changes that happen in between runs. Event-driven scraping responds instantly to changes as they happen.
4. Can I blend event-based triggers with scheduled scraping?
Yes. Many teams use cron jobs for coverage and event triggers for speed. This hybrid approach ensures you catch both known and unexpected changes efficiently.
5. What’s required to implement real-time pricing intelligence?
You need event sources (like feeds or ESLs), a diff engine, a queue with TTL and retries, and structured delivery (via S3/API/webhooks) for downstream use















