



In most countries, traffic accidents are the leading causes of injuries and deaths. Road Traffic Accidents (RTA) cause more than 1.24 million deaths and 30-50 million injuries worldwide (As per WHO report, The huge number has its associated socio-economic impact that further places a huge burden on any economy – developed or developing. Accidents burden the healthcare system, cause financial loss, and affect the economy indirectly. Hence, steps have to be taken to reduce effects of road traffic accidents.

Already, governments and road authorities already have installed road signs and traffic lights, and there is ongoing work to improve road conditions in an effort to reduce collisions and vehicular accidents, but more can be done to further bring down the number of injuries and fatalities. But governments cannot work or create comprehensive road safety policies without accurate data and information.
How Data Mining helps?
The automobile industry has been working hard to design and build vehicles that are safer, but traffic accidents are unavoidable part of modern society. Researchers believe if they can detect patterns of serious crashes, they would be in a position to design and develop predictive models that automatically inform the type and severity of an injury for different kinds of traffic accidents. This, in turn, would help governments and road safety authorities from preventing and controlling vehicular accidents.
This is where data mining in road traffic plays a crucial role. Data mining extracts patterns from large databases to help insightful decision making capabilities. However, analyzing, interpreting and using that data optimally is not only difficult, it requires a lot of skilled resources. This is because these databases are huge and have seen exponential growth in recent years. Experts reckon the world’s database increases 100 percent every 20 months. Hence, data mining and using machine learning in data mining could prove to be useful tools to sift through massive data and gather information that is useful.
Rather than focusing on existing hypotheses, data mining looks at creating new hypotheses. This, in turn, helps in finding and recognizing overlooked and unrecognized facts to improve road traffic safety.
Understanding Data Mining and Machine Learning
Data mining refers to the process of extracting patterns from data. This data is stored in large databases and hence, require special techniques and methodologies. Big data analysis is used in a variety of practical applications including marketing, scientific discovery, surveillance and fraud detection.
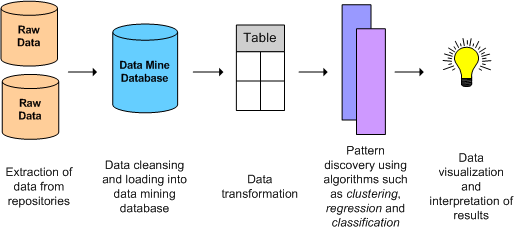
Machine learning deals with designing and developing algorithms that let computers devise insightful learnings based on data input. This data could be huge databases or sensor data. Using machine learning in data mining allows computers to automatically recognize complex patterns and make intelligent decisions based on these patterns.
Road accident analysis show there are various complex patterns involved in accidents. Therefore, using big data analysis and an array of data mining tools, various roadway patterns can come to the forefront, thereby paving way for a more effective and efficient traffic safety control policy.
Functionalities of Data Mining
Typically, the tasks in data mining are categorized into two types – descriptive and predictive. In the former, general properties of the data are characterized; while in predictive analysis, the available data is used to make predictions.
The key functionalities of data mining are:
- Data Characterization: This is a summary of the target class, or the class that being studied
- Data Discrimination: The target class is compared to other sets of class
- Association Analysis: This analysis look for association rules, wherein attribute and value occur frequently in the data
- Classification: Here, researchers look for a set of model that separates concepts and/or data classes so that they can be used for prediction
- Prediction: When there numerical data is missing or unavailable, researchers use prediction
- Cluster Analysis: Here, data objects are analyzed without referring to a known class label. The focus is to maximize intra-class similarity, while reducing inter-class similarity
- Outlier Analysis: Typically, databases have objects that do not fit into general behavior or data model. These objects are referred to as outliers
- Evolution Analysis: This analysis deals with models or trends of objects that alter their behavioral patterns over a period of time
Data Mining & Predictive Analytics
Researchers have turned to data mining and predictive analytics to reduce the effects and occurrences of road traffic accidents. This analysis allows them to gauge the causes of the accidents as well as severity of injuries to design and develop ways not only make roadways safe, but also minimize severity of injuries.
In this effort, researchers use a range of data mining algorithms on a set of reliable data. This data set typically has information or labels across various features/characteristics, some of which are as follows:
- Severity of injury
- Weather
- Natural light conditions
- Road conditions
- Vehicle movements
- Type of collision
- Number of vehicles involved in the collision
- Number of casualties
- Age of casualty
- Gender of casualty
- Role played by the casualty in the accident
- Degree of injury
- Junction control
- Driver gender
- Driver age
- Year of manufacture of vehicle
- Vehicle class
- Pedestrian action
Using data mining techniques and tools, researchers then try and develop machine learning that can predict severity of injuries in a more accurate manner. This allows researchers to understand the association between driver, vehicle, environment, roadway and severity of driver injury. Accurate result analysis is important, as the results can provide much-needed information to prevent or reduce road accidents.
Determining Factors Leading to Road Analysis
Researchers use a number of different approaches to determine factors that affect severity of injury. Some of these approaches are as follows:
Naïve Bayesian Algorithm
This is one of those data mining algorithms that uses Bayesian theorem with valid and strong independent assumptions. It is a simple probabilistic classifier. This algorithm is popular because it allows fast, scalable linear model with a range of predictors.
J48 Decision Trees
This machine learning model is predictive in nature. It determines that target value of a completely new sample. It uses a range of attribute values available in the data to build a binary tree.
AdaBoostM1 Classifier
Often it has been seen dataset can have a weak classifier. This can lead to errors in data mining & predictive analytics. By using the AdaBoostM1 algorithm, researchers can improve the state of the weak classifier, so that the chances of classification errors reduce.
Genetic Algorithm
This type of algorithm is used for feature selection problem. Basically, it makes use of Darwin’s theory of evolution and generates chromosomes, which are viewed as solutions to the feature selection problem.
Partial Decision Trees (PART) Classifier
This rule-based algorithm is used to generate ‘if and then’ rules that are used for data classification. This algorithm takes certain strategies from both C4.5 decision tree and RIPPER algorithm to come up with the rules.
Future of Data Mining in Road Traffic
There is no doubt data mining algorithms and data mining tools have a crucial role to play in reducing the causes and effects of road accidents. However, with advances in technology and more widespread use of Internet, the way data is extracted and analyzed is gradually changing.
Today, websites are knowledge dispensers that provide valuable information to visitors. They are vast and untapped repositories of information and knowledge. Hence, it has become important to discover useful information from this source, so that marketing strategies can be molded and optimized to the usage of web servers, so that they can handle growth in future. The tools for web server analysis currently offer just statistical information and not genuine, useful knowledge. This is where web scraping may prove to be extremely useful in extracting data from websites.
There is a lot of useful data available on the Web. Using web scraping, this data can be extracted, classified and be used to design an alert system that provides alerts to drivers. Predictions of web traffic trends, such as grievously injured people, material damage, fatal accidents and slight injuries can be used to ensure drivers get real-time information about prevailing traffic conditions in different locations. So, it appears that at some point or the other, researchers will look to web scraping to replace data mining.
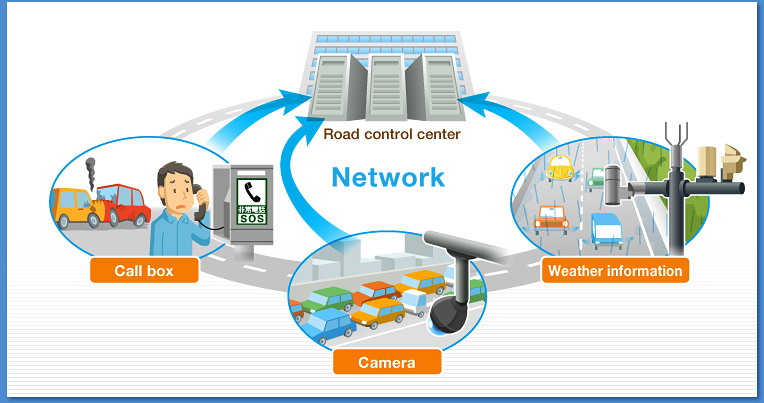
Modern-day traffic networks already make use of several measurement devices, such as radar sensors, inductive loops and video sensors, which provide real-time information on traffic conditions. However, if researchers can come up with a data mining model that sends alerts to drivers the moment they enter a danger zone on how to react and what to do when he gets an alert, will be one of the various ways to prevent road accidents.
The Bottom Line
There is no doubt data mining tools and techniques are proving to be valuable assets in harnessing information in big databases, there should still be a concerted effort to update road and traffic index annually. This will allow researchers access to current and up-to-date information. Using data mining techniques and current data, researchers will be able to design and develop more accurate models to improve road safety. Data mining & predictive analytics help in creating newer methods to reduce road accident injuries and fatalities.















