



The pre-digital state of classified ads was extremely monolithic; requiring a pair of reading glasses even for the normal eyes.

Then came the internet with the explosion of websites. Digitization of classifieds too was happening and Craiglist was the pioneer. What followed is evident to all. There were more players rushing to this zone, and given the large size of the market, many availed spots. Trends hence changed, advertisers could easily post their ads (at free or minimal costs) without having to spend heavily on traditional advertising media and users looking for classifieds easily found what they wanted. Buying/selling properties, renting vehicles, searching jobs, hiring professional services- all became a virtual affair. With the penetration of smart phones in the market, people could search or post ads even when mobile.
Even as an established classifieds site, there are gaps in datasets and amount of data that can be generated on the site itself is limited. A lot of these digital classified ads sites hence aggregate data from

other websites to increase community outreach and span all possible categories of interest. Classifieds has been one of the prominent domains we have worked with so far.
So what goes into designing a big data solution for a classifieds engine?
The goal is to powerfully and scalably collect ads from multiple sources, which our DaaS platform facilitates. It’s not just site scraping, but deep crawling of the sites to continuously gather fresh content along with relevant attributes in order to keep the client’s portals updated too. If client requirements want to focus on ads from specific regions, we use a geo-intelligence API that can only search within certain geographies. All these terabytes of data is then indexed using our hosted indexing solution to enable searches.
The end result?
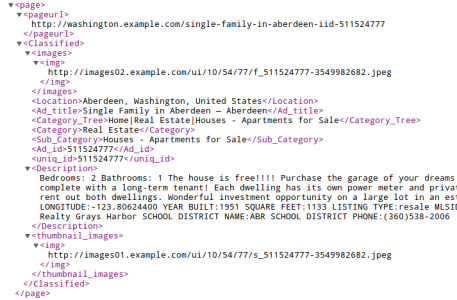
Continuous feeds of data get uploaded to our data API in near real-time from where the classified engine providers can download and later repurpose it for their use cases. Data is structured before delivery into an XML/CSV- whatever the importer can process at the client’s end. So on a whole, this big data solution is comprised of scraping as many sites as you like, from as many categories, confining to certain geographies if needed, and picking all attributes related to an ad- all this without letting any unrelated data element slip in. Accuracy is 100% and coverage is between 95%-99% on these source sites.
What essentially happens in the process is that more people see these ads and hence more needs get served via these engines. Needless to say that with such solutions, more such businesses can enter the market and fulfill greater needs of their users.















