




**TL;DR**
robots.txt was built for a simpler web. Today, bots include LLMs, AI agents, price trackers, SEO crawlers, and more. To manage this traffic, the web is moving to a layered access stack—robots.txt for hints, sitemaps for freshness, signature headers for verification, and bot auth tokens for control. This article breaks down how each layer works, what standards are emerging (like HTTP message signatures), and how to implement them to protect your site and enable responsible machine access.
Why robots.txt Alone Isn’t Enough in 2025
The robots.txt file was never meant to be a gatekeeper. It was a handshake agreement—a text file bots could voluntarily read to know which pages to skip. But the modern web doesn’t run on handshakes.
Crawlers today aren’t just polite search bots. They include:
- LLM agents auto-indexing for summarization
- Price trackers scanning marketplaces by the hour
- SEO scrapers harvesting metadata and reviews
- Competitive tools probing sitemaps, feeds, and JS APIs
- AI agents simulating user behavior for decision-making
All of them bypass traditional crawl rules unless enforced at deeper layers.
Limitations of robots.txt Today
- No identity check: Anyone can pretend to be Googlebot.
- No rate limits: A crawler can ignore crawl-delay and hit you with 500 RPM.
- No enforcement: You will not be able to reject traffic just because it violates robots.txt.
- No versioning/audit trail: You will not be able to know how to track who scraped what or when.
What’s Has Changed Since 2020?
- APIs and dynamic content now carry more business logic than HTML pages.
- Scrapers use headless browsers and residential proxies, ignoring User-Agent-based rules.
- Real-time access by machines—not humans—is shaping search, recommendation, and pricing systems.
The result: robots.txt is now just one part of a much larger stack. Alone, it’s silent. With support from headers, auth, and verification layers, it becomes enforceable.
Want verified bot access that respects your crawl rules and delivers structured data at scale?
If you're evaluating whether to continue scaling DIY infrastructure or move to govern global feeds, this is the conversation to have.
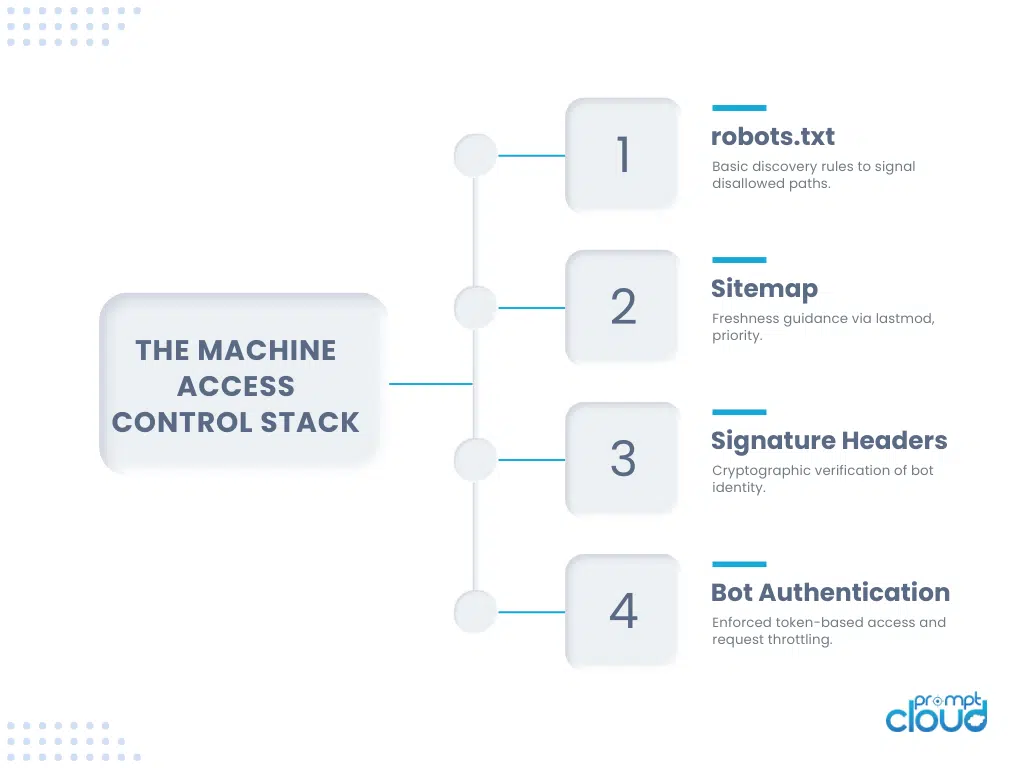
Meet the Modern Access Stack: 4 Layers to Control Bot Traffic
If robots.txt is the front door, modern websites now have locks, cameras, intercoms, and visitor badges. Bot traffic today needs layered control—not just polite guidance.
Here’s what the new machine-access stack looks like:
| Layer | Purpose | Example |
| robots.txt | Signals allowed/disallowed paths | Disallow: /checkout/ |
| sitemap.xml | Indicates what and when to crawl | lastmod, priority, changefreq |
| Signature Headers | Verifies bot identity with signed headers | Signature, Signature-Input |
| Web Bot Auth | Grants crawl access via tokens or headers | API key, OAuth token, JWT |
Each layer handles a different risk:
- robots.txt → Visibility control
- sitemap → Freshness & coverage guidance
- Signature headers → Bot authenticity
- Bot auth → Rate limits, quotas, and permissions
Why a Stack?
Because bots aren’t one-size-fits-all. You might want:
- Googlebot to crawl your public PDPs,
- A partner to access your API with strict quotas,
- And unknown bots to get blocked or served dummy data.
A flat allow/deny list won’t cut it anymore. The stack lets you treat different bots differently—based on who they are, what they want, and how they behave.
If you’re building real-time controls for AI and commercial crawlers, this breakdown of how LLM agents use real-time data pipelines shows how queueing, backpressure, and structured delivery apply directly to bot access governance.
What Are Signature Headers (and Why They Matter for Bots)
Crawlers used to rely on user-agents and IP reputation to signal identity. Both are unreliable. Today’s bots can spoof any agent string and rotate IPs across geographies in seconds.
Signature headers solve that. These are cryptographic headers—defined in the IETF HTTP Message Signatures draft—that let a bot sign its HTTP request, proving it came from a known source and wasn’t modified in transit.
Key Headers
- Signature-Input: declares what parts of the request are being signed
- Signature: carries the actual signature (generated using a private key)
Servers can then verify the signature using a known public key associated with that bot.
What This Enables
- Confirm if the request actually came from a specific bot
- Reject traffic that doesn’t carry a valid signature
- Rotate keys, assign permissions, and track abuse per signing identity
Example (Header Block)
Signature-Input: sig1=(“@method” “@path” “user-agent”); created=1695379200
Signature: sig1=:dGVzdHNpZ25hdHVyZQo=:
This pattern allows you to treat bots like clients—with verified identity, TTL-bound permissions, and revocable credentials. Signature headers form the verification layer in the bot access stack, working alongside tokens, IP filters, and rate rules.
Read more: For ecommerce teams focused on dynamic pricing and catalog protection, this guide to pricing intelligence with event-triggered scrapers shows how bot control impacts pricing alerts, MAP enforcement, and SKU repricing.
Web Bot Authentication: Going Beyond Robots Directives
Verification is not the same as control. Signature headers tell you who a bot claims to be. Authentication tells you what that bot is allowed to do. Web bot authentication uses tokens or API keys to grant access based on identity, path, and rate limits. It works like OAuth or API auth, but for structured crawl access.
This layer solves problems that robots.txt and signature headers cannot:
- You want Googlebot to crawl your public catalog, but not your search endpoint.
- You want a partner’s bot to access only your price API, 50 requests per minute.
- You want to cut off access for a bot exceeding error thresholds or violating quotas.
How It Works
A bot requests access with a token or key attached in the header. The server checks:
- Is the token valid?
- What is this bot allowed to access?
- How fast can it access?
- What region or paths are restricted?
If all checks pass, the request proceeds. If not, it’s throttled, denied, or routed to a fallback.
Header Example
Authorization: Bearer abc123xyz
X-Crawl-Scope: /products/
This method lets you differentiate between verified access and general scraping traffic. It also creates an auditable trail for monitoring usage, abuse, and SLA compliance.
How to Signal Crawl Policy with Transparency and Control
Controlling bots doesn’t mean blocking them all. It means setting clear rules, publishing them in machine-readable formats, and enforcing them across layers.
Robots.txt still plays a role, but it needs support from sitemaps, headers, and real-time policy endpoints.
Components to Implement
Robots.txt sets default permissions. Include:
- Crawl-delay settings
- Disallow paths
- Contact email for crawl issues
Sitemap.xml: Indicates priority pages, last modified timestamps, and change frequencies. Make it dynamic so it reflects updates in near real time.
Signature Headers: Require bots to sign requests. Use IETF draft standard http message signatures for cross-compatibility. Include request method, path, and timestamp.
Bot Auth Token: Grant access via signed tokens. Use short TTLs and limited scopes to restrict usage. Rotate keys regularly.
Policy Endpoint: Publish a real-time access policy at a known location. Format: JSON.
Example:
GET /.well-known/crawl-policy.json
Response:
{
“requires_signature”: true,
“token_required”: true,
“allowed_agents”: [“PromptCloudBot”, “TrustedLLMBot”],
“rate_limit”: “60rpm”,
“contact”: “crawl-admin@yourdomain.com”
}
Publishing this makes your rules visible to bots and transparent to teams consuming your data. It shifts the conversation from scraping to access negotiation.
Managing bots means setting clear rules. This post on the top 10 traps in news scraping outlines how broken robots.txt and weak selector logic fail when bots ignore governance.
Implementing the Stack: A Step-by-Step Bot Access Blueprint
Controlling bot access requires more than a robots.txt update. This stack needs coordination between infrastructure, application logic, and policy. Below is a deployable plan.
Step 1: Update robots.txt for Minimum Baseline
- Block paths you never want indexed
- Allow bots only where required
- Add a contact email and crawl-delay
Example:
User-agent: *
Disallow: /checkout/
Crawl-delay: 10
Contact: crawl-admin@example.com
Step 2: Serve a Dynamic Sitemap
- Include lastmod and priority fields
- Refresh frequently using your CMS or inventory system
- Submit to search engines and partners
Step 3: Enable Signature Header Verification
- Use IETF draft: HTTP Message Signatures
- Accept headers: Signature, Signature-Input
- Validate requests against your bot registry
- Rotate keys every 7–30 days
Step 4: Authenticate Verified Bots
- Issue short-lived API tokens
- Attach permissions per endpoint
- Enforce rate limits at the CDN or load balancer
- Audit token usage with logs and metrics
Example:
Authorization: Bearer pc-crawler-123
Step 5: Publish a Crawl Policy File
Serve a structured JSON file at a known endpoint.
Path: /.well-known/crawl-policy.json.
This file tells bots what’s expected: identity, rate, signature, token.
Step 6: Monitor, then Adjust
- Alert on unknown bots exceeding thresholds
- Rotate keys on compromise
- Track most active bots by volume, success rate, and endpoint
- Use honeypot URLs to detect abuse
Note: Signature headers are based on the IETF HTTP Message Signatures draft.
What the Stack Solves (and What It Doesn’t)
The new bot access stack doesn’t eliminate scraping. It separates acceptable machine traffic from abuse. Each layer has a purpose, and together, they allow teams to shape crawl behavior with precision.
Problems This Stack Solves
- Unauthenticated scraping: Only verified bots with proper headers or tokens can access sensitive endpoints.
- Impersonation: Signature headers confirm the bot is who it claims to be.
- Rate abuse: Auth layers enforce RPM limits and burst control.
- Unauthorized access to hidden APIs: Bots without tokens or signatures are denied or rerouted.
- Policy transparency: Publishing crawl rules in a JSON schema removes ambiguity.
What It Doesn’t Solve
- Human scraping: A human with a browser can still save a page manually.
- Botnet behavior: Malicious actors can rotate IPs and ignore all rules.
- Credential misuse: If a verified bot’s token is leaked, abuse is possible until revoked.
- Zero-day vulnerabilities: Crawlers that exploit public endpoints or use outdated pages might still bypass logic if enforcement is not strict.
Reference Table: What Each Layer Handles
| Control Layer | What It Solves | What It Can’t Prevent |
| robots.txt | Basic discovery rules | Signature spoofing, silent scraping |
| Sitemap | Update frequency, crawl hints | Over-crawling stale paths |
| Signature headers | Bot identity verification | Token theft, key compromise |
| Bot auth/token | Access control, rate limits | Human scraping, session hijack |
| Policy endpoint | Clear machine-readable rules | Enforcement without backend logic |
Governance starts with visibility. The stack lets you track bot behavior, respond to breaches, and shape access in real time.
Best Practices: Crawl Control for LLMs, Scrapers, and Partners
Not all bots are equal. Some power product search. Some scrape aggressively. Others are partner services under contract. A one-size-fits-all access policy doesn’t work. Here’s how to handle each class of machine traffic with control and precision.
For Public LLMs and Aggregators
Examples: GPTBot, PerplexityBot, ClaudeBot
- Require signature headers to verify origin
- Limit access to high-level pages only (e.g., /blog/, /category/)
- Monitor for repeated requests from unverified UAs
- Enforce TTL on signed requests to reduce replay risk
- Publish your policy at /.well-known/crawl-policy.json
For Commercial Scrapers
Examples: SEO tools, price aggregators, review extractors
- Whitelist known partners by issuing API tokens
- Attach token to all crawl requests
- Enforce per-token rate limits (e.g., 60 RPM per endpoint)
- Rotate keys every 30 days
- Log all activity by token for audit and billing purposes
For Internal Bots and Partners
Examples: Internal monitoring, authorized catalog partners
- Use signed tokens scoped to paths (e.g., /api/prices/)
- Create sandbox environments for QA
- Require full header and token chain: Authorization, Signature-Input, Signature
- Serve full diffs, not deltas, where needed for accuracy
For Unknown or Abusive Bots
- Block by default unless they present identity
- Honeypot URLs to detect scraping attempts
- Rate-limit based on IP fingerprinting
- Challenge-response options like CAPTCHA or TLS client auth for sensitive endpoints
When you separate bots into these types and enforce layered control, you keep your systems open to legitimate use and closed to everything else.
What to Publish in /crawl-policy (Example Schema)
Modern crawlers need more than a text file. They need structured, machine-readable instructions about what is allowed, what’s restricted, and how to authenticate. Publishing a crawl policy in JSON format makes your rules transparent and enforceable.
Serve this file at: /.well-known/crawl-policy.json
Example JSON Schema
{
“allowed_agents”: [“PromptCloudBot”, “TrustedLLMBot”],
“disallowed_paths”: [“/checkout”, “/user-data”, “/internal-api/”],
“signature_required”: true,
“token_required”: true,
“auth_endpoint”: “https://yourdomain.com/api/get-crawl-token”,
“rate_limits”: {
“PromptCloudBot”: “60 rpm”,
“TrustedLLMBot”: “30 rpm”,
“Unknown”: “5 rpm”
},
“ttl_seconds”: 180,
“contact”: “crawl-admin@yourdomain.com”
}
This schema gives verified bots everything they need:
- Which user agents are allowed
- Which paths are blocked
- Whether a signature is required
- Where to request a token
- How fast they can crawl
- Who to contact if something breaks
Publishing this reduces confusion, enables good actors to comply, and lets you enforce violations clearly.
The Future of AI Crawl Governance in 2025 (and How to Prepare)
The shift from “scraping” to “structured access” isn’t theoretical—it’s already underway. As more traffic comes from bots, agents, and LLM-powered services, the web needs stronger standards, real-time control, and machine-readable policies. This isn’t about stopping crawlers; it’s about managing them like any other integration.
The Web Is Now Machine-First
Large Language Models (LLMs) are reshaping how users find, summarize, and act on information. Instead of visiting your site directly, users are increasingly relying on:
- AI summarization tools
- Conversational interfaces
- Shopping and price comparison bots
- Research assistants trained on real-time content
These tools don’t browse. They crawl, extract, summarize, and route. Some use APIs. Others parse your HTML. Many ignore robots.txt unless explicitly challenged.
Governance, Not Blocking
AI crawl governance doesn’t mean cutting off bots. The stack helps enforce this through:
- Signature headers to verify identity
- Token-based auth to assign permissions
- Real-time rate limits for fairness
- JSON policy files to declare expectations
Together, these components give you the tools to grant, adjust, or revoke access on your terms—not theirs.
Where This Is Going
Expect these trends to accelerate:
- Standardization of bot auth: Just like OAuth became the default for API identity, signature headers are becoming the default for bot verification.
- Machine-readable policies: More domains will publish /crawl-policy.json as a standard endpoint, especially in ecommerce and content-heavy sites.
- Contracts and monetization: Expect to see commercial bot licenses, usage-based fees, and crawl SLAs negotiated with third-party scrapers and aggregators.
- More intelligent blocking: Honeypots, anomaly detection, and behavior scoring will replace static IP blocks and UA filters.
- Bot access logs becoming KPIs: Understanding which bots are accessing what content—and how it impacts traffic and revenue—will become part of SEO, product, and data science dashboards.
What You Can Do Today
- Start by implementing signature header checks and basic token auth for high-risk paths.
- Publish a crawl policy JSON file for transparency and discoverability.
- Monitor bot activity separately from user traffic in your analytics pipeline.
- Create a contact channel for verified bot operators to request access, keys, or tokens.
- Begin to categorize bots as partners, AI agents, or unknowns—and build logic around each.
Machine access to the web isn’t optional anymore. It’s a core part of how information moves, how decisions are made, and how value is created. Governance is no longer a technical detail. It’s a business requirement.
Want verified bot access that respects your crawl rules and delivers structured data at scale?
If you're evaluating whether to continue scaling DIY infrastructure or move to govern global feeds, this is the conversation to have.
FAQs
1. What’s wrong with just using robots.txt?
robots.txt is a guideline, not enforcement. It can be ignored, spoofed, or misunderstood. It also lacks rate limits, authentication, or identity verification. It should be one part of a larger access control stack—not your only line of defense.
2. How do signature headers verify bot identity?
Signature headers use public-private key cryptography. The bot signs key parts of the request, and the server verifies the signature using a known public key. This confirms the request came from who it claims to—and wasn’t altered in transit.
3. Can I create crawl policies specifically for LLMs?
Yes. You can publish machine-readable JSON policies at known paths like /.well-known/crawl-policy.json. These can declare rate limits, required headers, tokens, and disallowed paths—giving compliant LLMs clear rules to follow.
4. What if a bot ignores my rules?
If a bot disrespects robots.txt, signature requirements, or crawl policies, you can throttle, block, or serve alternate content. Use fingerprinting and honeypots to detect and log abuse. Governance is about controlling what you allow—not stopping all access.
5. How do I track and throttle verified bot traffic?
Use tokens, signature headers, and logs to trace requests by bot identity. Set per-token rate limits, monitor TTL expiration, and alert on misuse. Push verified events into your observability stack for SLA compliance, abuse prevention, and trend analysis.















