




Deep learning models have significantly improved accuracy in object recognition. A “machine” can now identify and categorize images with astonishing precision. Nevertheless, these models only perform exceptionally well given one factor—data. In the absence of high-quality, data-rich, diverse, and well-categorized image datasets, even the most sophisticated deep learning models will falter at achieving accuracy. This gap is filled by image scraping.
AI engineers and data scientists can now utilize a website image extractor to scrape countless pictures from the internet for use in their models, enhancing precision. In this article, we will delve into how website image extraction contributes to training deep learning models in object recognition, the challenges it solves, and ethical as well as optimal practices for effective image scraping.
What Is a Website Image Extractor?
Image source: Image Extractor
A website image extractor refers to a software tool or script that automatically extracts images from different web pages. Instead of manually downloading images one at a time, data scientists and AI engineers can now use these tools for bulk collection, simplifying the process of building large datasets for deep learning models.
How Does a Website Image Extractor Work?
Most website image extractors function by scanning web pages and identifying image URLs. These tools typically follow this process:
- Crawling the Website – The extractor accesses web pages and searches for images.
- Identifying Image URLs – It detects embedded image files such as JPEG, PNG, and GIFs within the page’s HTML structure.
- Downloading Images in Bulk – The tool saves the images locally or in a cloud storage system for further processing.
Many AI teams use free image extractors from websites to gather training data, while businesses handling large-scale AI projects often invest in customized web scraping solutions for better accuracy and efficiency.
What Are The Types of Website Image Extractors
There are different types of website image extractors, depending on the complexity of data collection:
- Basic Image Downloaders – Extract static images from simple web pages.
- Advanced Web Crawlers – Use AI and machine learning to extract images from dynamic websites with JavaScript.
- Custom Image Extractors – Built specifically for industries such as healthcare, retail, and autonomous vehicles to collect niche datasets.
With a well-designed website image extractor, deep learning teams can collect millions of labeled and unlabeled images, improving model accuracy and training efficiency.
Why High-Quality Image Data is Essential for Object Recognition
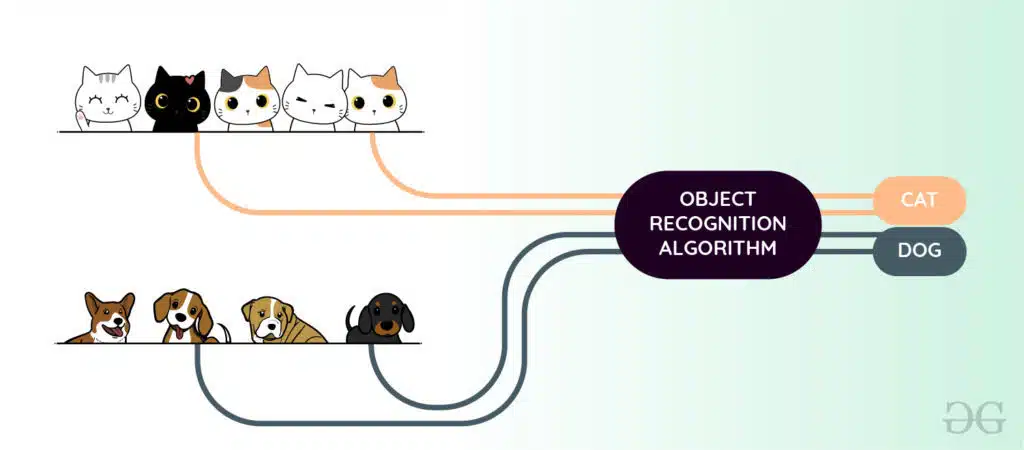
Image Source: GeeksForGeeks
Object recognition models rely on deep learning techniques employing deep neural networks and require a vast number of images to teach the program, each image having a corresponding label. Models critically evaluate the sequence of images to learn the patterns, contours, colors, and distinguishing characteristics, ranging from simple to complex, that make an object unique.
Trained models may encounter a dataset that is too compact, unrepresentative, has little variety, or lacks depth. For example, a self-driving automobile learns to recognize stop signs using images from a single country. Trained sign recognition is great until one day the automobile is faced with a physically identical sign in a different country that happens to be slightly different.
This is why AI engineers need massive and diverse image datasets. A website image extractor allows data scientists to gather millions of images from the internet, making it easier to create high-quality training data.
The Data Problem in Deep Learning
Studies show that deep learning models perform significantly better when trained on diverse datasets. For example, the ImageNet dataset, which contains over 14 million labeled images, has played a crucial role in advancing computer vision research.
Nonetheless, obtaining such datasets is almost impossible. The process of downloading and labeling images is inefficient, costly, and impractical for large-scale AI projects. This is where automated image scraping technology becomes useful.
How Image Scraping Powers Deep Learning Models
1. Automated Image Collection at Scale
A website image extractor helps AI engineers gather images in bulk from various online sources. Unlike manual image collection, which is time-consuming and inconsistent, automated image scraping can:
- Extract thousands of images per minute from different websites.
- Ensure data diversity by collecting images from multiple sources, reducing biases in training data.
- Retrieve images from niche datasets, such as medical scans, satellite imagery, or product photos.
If a company is developing an AI model for facial recognition, an image extractor helps collect demographic images to guarantee the representation of all skin tones and facial features.
2. Enhancing Model Accuracy with More Data
Imagine a neural network trained with images of cats, say 1,000; it will perform reasonably well. Now, provide it with an additional 99,000 images of varying angles, lighting, and settings, and the performance is transformed; it will vastly outperform expectations and will be anticipated to outperform by a more than performing on the sole training set.
By using a website image extractor, data scientists can:
- Improve object detection accuracy by training on a wide range of object variations.
- Reduce false positives and misclassifications by exposing models to diverse data.
- Improve generalization, allowing the model to recognize objects in different lighting conditions, angles, and settings.
3. Reducing Overfitting in Object Recognition Models
One major challenge in deep learning is overfitting—when a model learns patterns specific to the training data but fails in real-world situations.
For example, if an AI model is trained only on bright, high-resolution images, it may fail when analyzing blurry or low-light images.
Using an image from website extractor, data scientists can collect varied images, ensuring the model:
- Learns to recognize objects in different environments (indoor, outdoor, low-light, etc.).
- Adapts to different image qualities, making it more robust.
- Becomes more generalizable, reducing the risk of failure when exposed to new data.
4. Fine-Tuning Pre-Trained Models with New Data
Many AI engineers rely on pre-trained models, which are deep learning based, including ResNet, VGG, or YOLO, that have undergone extensive dataset training. With such extensive training, these models require fine-tuning in regard to specific tasks.
Take, for example, an e-commerce store. If they want to implement an AI system to detect fashion trends, they would need an up-to-date dataset of recent fashion styles. A website image extractor enables them to perpetually augment their training data with fresh and pertinent images.
Overcoming Challenges in Image Scraping for Deep Learning

1. Handling Duplicate Images
Since web scraping gathers data from multiple sources, duplicates are common. Training a model with redundant images can:
- Waste computational resources during training.
- Bias the model toward repeated patterns.
- Reduce dataset quality by lowering its diversity.
To overcome this, AI engineers use image deduplication techniques, such as hashing algorithms and feature-based matching, to filter out identical images.
2. Ensuring Ethical and Legal Compliance
Scraping images from the web raises ethical and legal concerns. Many websites have copyright restrictions, and using copyrighted images without permission can lead to legal issues.
To ensure ethical data collection, businesses should:
- Scrape only publicly available images and respect website terms of service.
- Use licensed datasets or seek permission when necessary.
- Anonymize sensitive images, especially in facial recognition projects.
3. Managing Data Quality Issues
Not all images scraped from the web are useful. Some may be:
- Blurry or low-resolution images make them unsuitable for training.
- Misclassified or mislabeled, leading to poor model performance.
- Irrelevant to the intended AI task.
To improve dataset quality, AI teams implement automated filtering techniques, such as:
- Image resolution checks to filter out low-quality images.
- Metadata analysis to confirm the image’s relevance.
- Human-in-the-loop verification to improve dataset accuracy.
Best Practices for Using Image Scraping in AI
1. Use Reliable Image Extractor Tools
AI engineers should use high-quality image extractors from websites to ensure data accuracy. Open-source tools like Selenium, Scrapy, and BeautifulSoup can help automate image collection.
2. Preprocessing Images Before Training
Raw images often need preprocessing, such as cropping, resizing, color correction, and data augmentation, to improve deep learning model performance.
3. Balance the Dataset
Ensure your dataset has equal representation of object categories to prevent biases in AI predictions.
4. Monitor Model Performance Regularly
Even with high-quality image datasets, models need continuous evaluation. AI teams should track accuracy, false positive rates, and misclassifications to refine the dataset.
The Future of Image Scraping in AI
The domains of medicine, self-driving cars, and even e-commerce are tapping into the potential of AI technologies. This means that the demand for high-quality image datasets is at an all-time high.
The future of deep learning will benefit from improvements in automated web scraping, synthetic data creation, and AI-powered image classification. Computer vision and object recognition technologies will continue to evolve thanks to AI engineers making use of website image extractors.
Conclusion
When it comes to models designed for object recognition, the quality of the provided data is the only thing that matters. Image scraping helps in creating diverse datasets that fuel AI systems, therefore having a significant impact on the overall result.
With the help of a website image extractor, AI teams can automate the process of collecting images, thus increasing the precision of the model and decreasing the chances of overfitting. However, there are still many challenges that need overcoming, like ensuring ethical use of data, addressing duplicate and data quality, and maintaining ethical standards.For AI-driven businesses looking to enhance their deep learning models, leveraging web scraping for large-scale image extraction is a game-changer. If you need a reliable data extraction partner, PromptCloud is a trustworthy partner for those who need tailored data extrusion solutions to help build optimal AI models. Schedule a demo today!















