



How to Scrape Data from Flipkart Using Python
Being one of the largest e-tailers, Flipkart also has a ton of data at the disposal of web scrapers. Be it product information, price details, specifications for electronic items — the website has it all. Whether you are testing an eCommerce scraping tool, trying to find eCommerce data for your market research, or competitor analysis through price comparison; Flipkart is where you need to run your crawlers on to get good quality data. Let us take a look at how Web Scraping Flipkart Using Python.
Today we will focus on how to scrape product pages on Flipkart. You can create a list of webpages and iterate over them to gather data from all the pages, but we will leave that implementation to you.
Steps for Web Scraping Flipkart Python Code
Before we start coding, having Python 3.7, the BeautifulSoup library, and a code editor like Atom is a must like always. Once your setup is ready, you can go ahead and run the code given below.
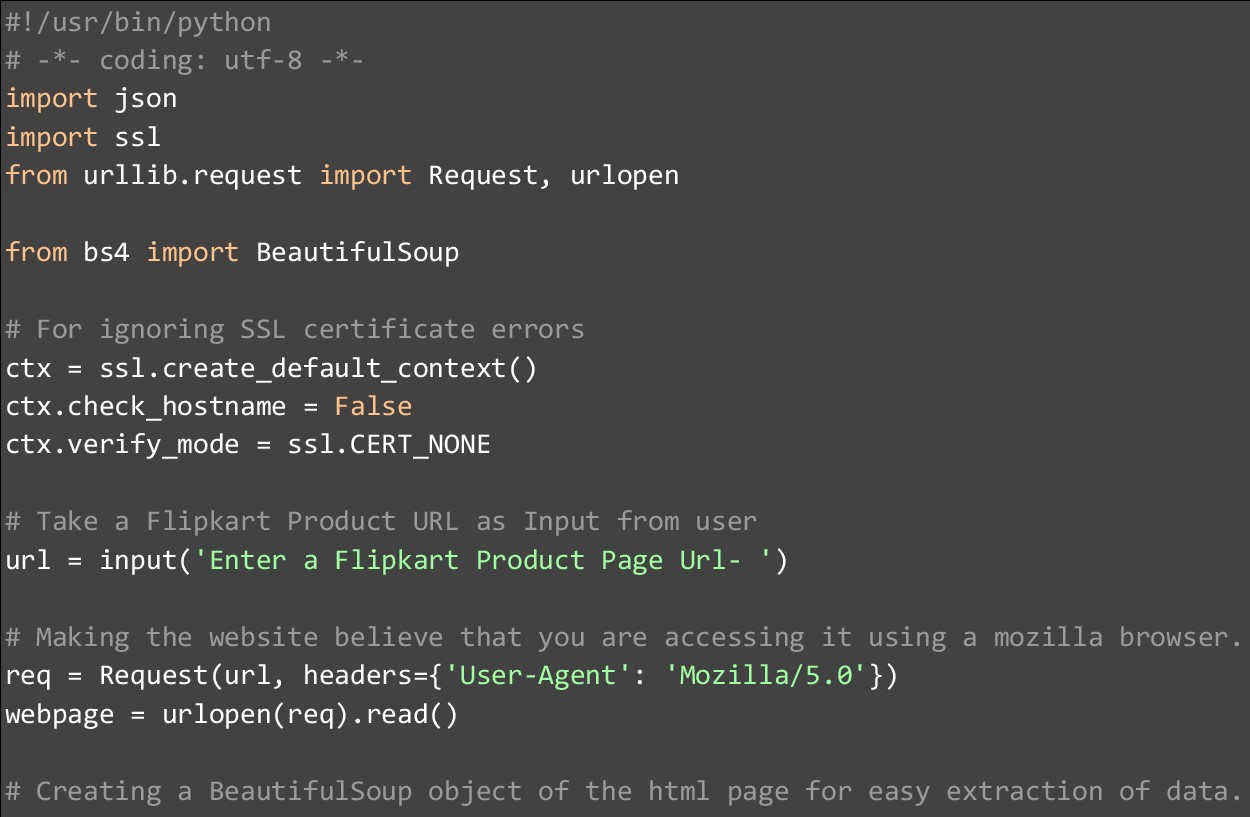
It is important to understand the code so that you can optimize it, use it to iterate over multiple webpages, or change the code to web scrape another eCommerce website. We start by importing the necessary internal and external libraries and ignoring SSL certificate errors. After this, we accept a URL from the user, this should be a product page URL from Flipkart. We have used the URL given in the shell script box below:


After taking the URL and storing it in a variable, we send an HTTP GET request and extract the HTML content. After this step has been performed, we read the webpage and convert it to a BeautifulSoup object. This is done so that the webpage content can be traversed with ease. We also prettify the HTML content and save it to a variable.
Now that we have the HTML data in a BeautifulSoup object, we will create a dictionary with the name “product_details” in which we will store different data points that we extract from the webpage. We start with the first “script” tag with the attribute “id” having value “jsonLD”. Inside this, we find a JSON value from which we extract rating, number of reviewers, brand-name, product-name, and image. After this, we pick up all the “li” tags with the attribute “class” set as “_2-riNZ”. All of these tags contain certain highlights of the product, which we extract one by one and append to the “highlights” attribute in “product_details”.
The Code Used To Extract Data From Flipkart
Price is one of the most important data-points and most eCommerce websites scrape competitor data mainly for this data point. We get this easily from the first “div” tag in the webpage with the attribute “class” having the value set as “_1vC4OE _3qQ9m1”. Lastly, we capture the different descriptions stored in various description headers. These are extracted in key-value format. The description-headers are present in a list of “div” tags with the attribute “class” set as “_2THx53”. The descriptions themselves are stored in “div” tags with the attribute “class” set as “_1aK10F”.
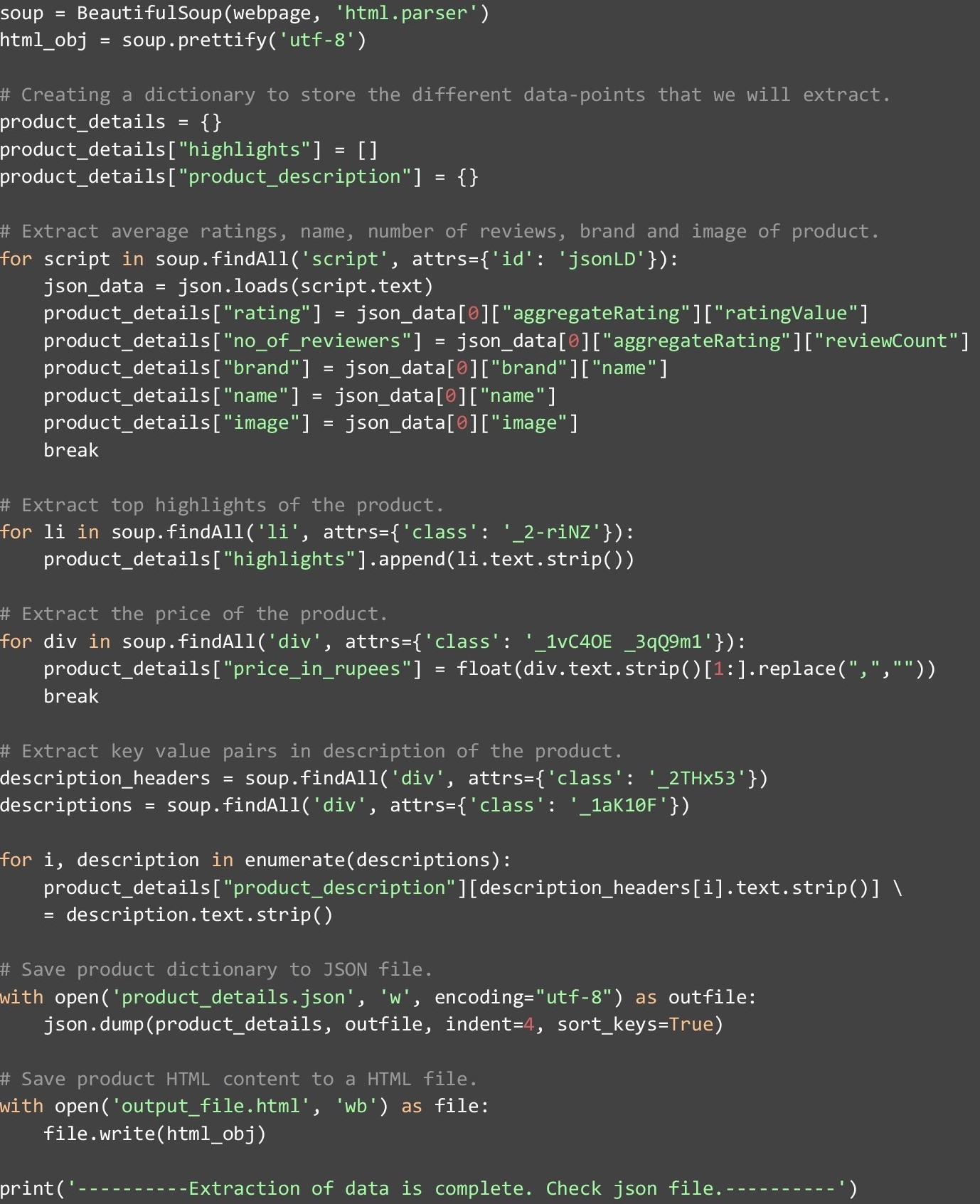
Once all the data has been extracted and stored in the dictionary that we created, we will have to save it to a JSON file with the name “product_details.json”. We also save the beautified HTML in a file named “output_file.html”. This is required so that the HTML can be manually analyzed and new data-points can be found. The data extraction points in this piece of code was also possible through the manual analysis of the HTML content beforehand.
The Data that We Extracted via Web Scraping Flipkart
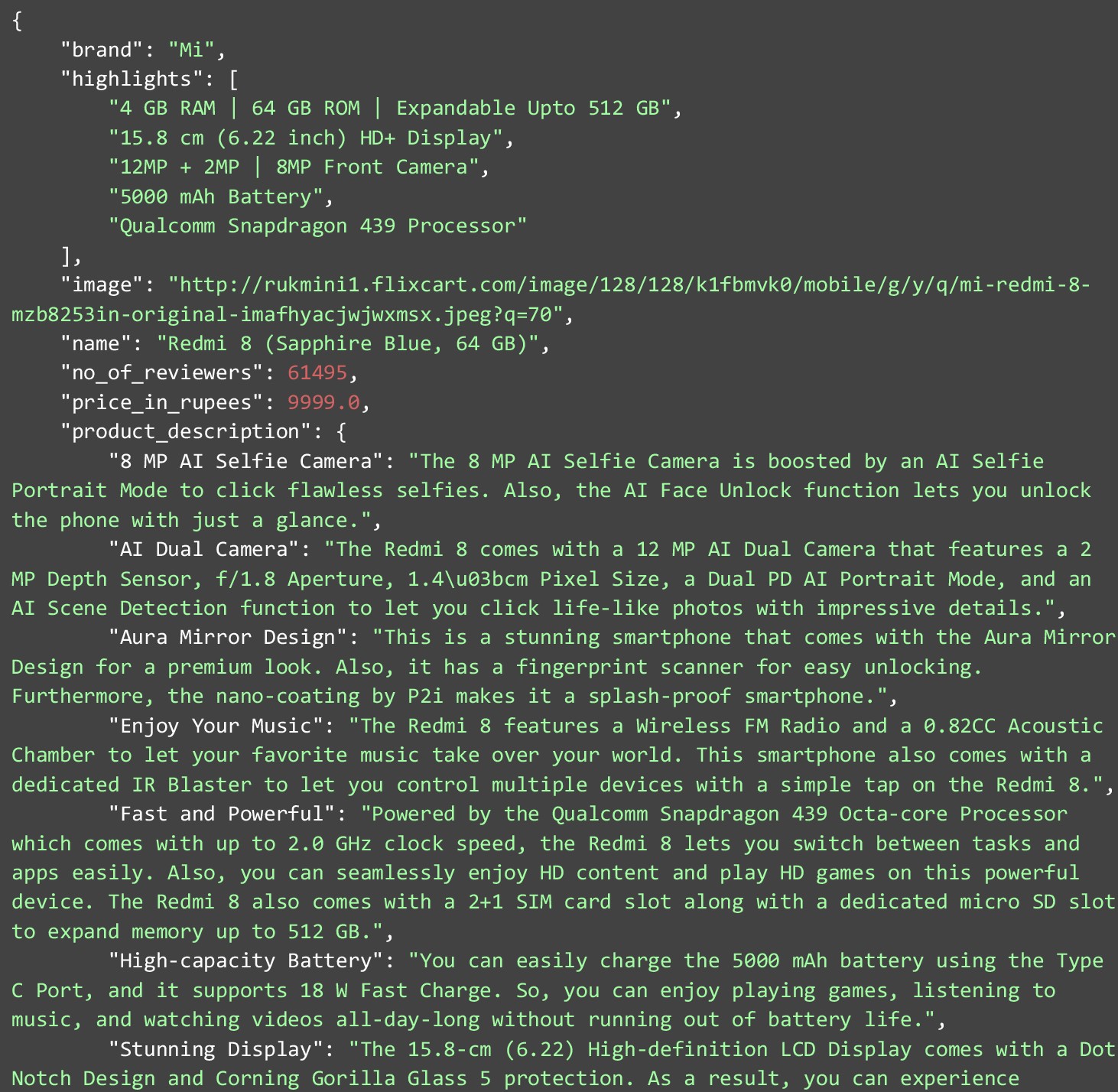
Now that our code has run, let us look at the data that we extracted. With the product URL that we provided, this JSON below is what we got as a result. Let’s analyze it to deep dive into the data. Among data points that have single values, we have-
- Brand
- Image
- Name
- Number of reviewers
- Price in Rupees
- Rating
Among other data points, we have the highlights which contain a list of main details of the product. The product descriptions contain a list of key-value pairs. For better understanding, you can go through the JSON below.

Limitations of Web Scraping
When it comes to enterprise-grade solutions, in no way will this piece of code help you build one? There are multiple constraints that you may face while running this piece of code. First and foremost, when it comes to accepting the URL, in case the input is an invalid URL or not a Flipkart URL, exceptions are bound to get thrown. These need to be handled. On the other hand, even if a valid URL is given, not all products would have all the data-points that we have extracted in this code. All these scenarios need to be handled through exception handling.
In case you need to scrape hundreds or thousands of product web pages, your code needs to be able to run parallelly so that you can make optimum use of the system and get more information in less time. Such implementation is vital for enterprise solutions that have time constraints.
Conclusion
There are also chances of IP blocking when undertaking such large-scale projects, and hence IP rotation is another tool that needs to be integrated into the system. Taking care of the legal aspects of scraping competitor data may also need to be taken care of. Such options are not available in DIY solutions and for these, you will need to build your web scraping team, if you have the resources- or go for a DaaS provider like PromptCloud.
Our team at PromptCloud makes web scraping a hassle-free solution and reduces the massive number of steps in the process into just requirement submission and plugging in the scraped data. We understand that web scraping and injecting data into your business to drive data-driven decisions should not be hard. And that is why our solutions help companies take the digital leap easily.
Please leave us your valuable feedback in the comments section below if you liked the content.















