



In case you are running a business that is in need of web data and currently exploring various options for scraping the web, you need to be aware of the basics of web data acquisition. Based on our years of experience in web crawling and handling numerous high-volume scraping projects, we have come up with a simple framework that can be used by any organization to evaluate the right options depending on the three elements.
Now, let’s explore the framework.
There are three primary dimensions of web data acquisition –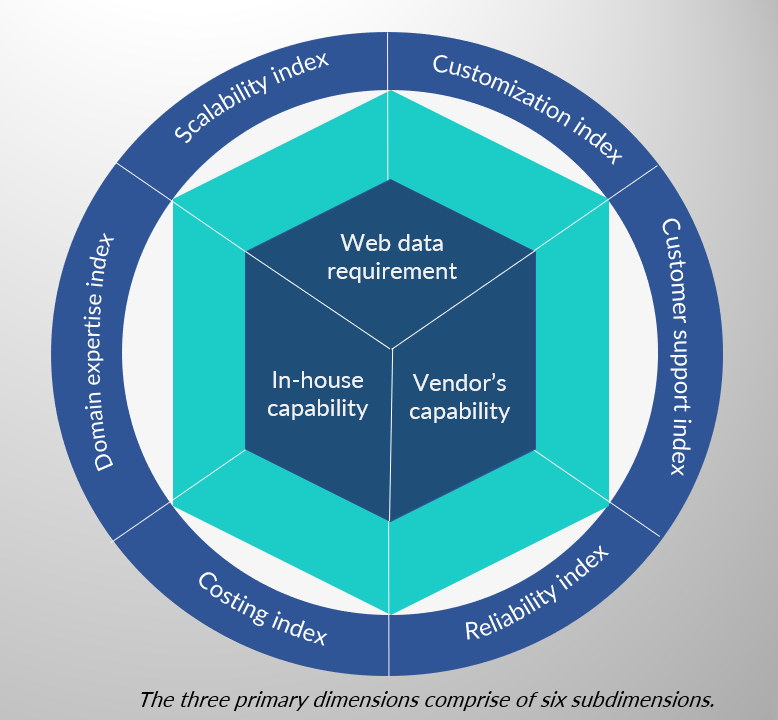
1. Web Data Requirement
- Scalability Index
- Customization Index
2. In-House Capability
- Domain Expertise Index
- Costing Index
3. Vendor’s Capability
- Customer Support Index
- Reliability Index
The three primary dimensions have been further segregated into two sub-dimensions, so as to make estimations and decisions easier for you. The flowchart on page 4 will explain how these dimensions fit into your decision-making model.
Web Data Requirement
This is the most obvious dimension. Without it coming into the picture, you would not have been reading this piece. There are broadly two types of data acquisition requirements:
- One time crawling (from either simple or complex web pages)
- Recurring crawling that results in high volume data
In case your data needs are simple and more of a one-time need for data extraction from a few static web pages, you could use some of the DIY tools available for scraping web pages. However, in case of more serious web-scraping needs, scalability index comes into the picture. Scalability index depends on two factors, how frequently you need data to be scrapped, and the volume – whether you need to crawl ten sites or a thousand. On the other hand, the customization index depends on the complexity of the websites you want to crawl (whether they store all data in basic HTML and CSS or use several layers of data abstraction), whether you want the data to be normalized for ease of usability or one record in the data set comprises of data extracted from several pages. Complexity also increases when you need to download the files (whose links are present in the websites that you are scraping) as well.
Once you are aware of how simple, or challenging your data needs are, your next step should be evaluation of internal teams and their capabilities and decide whether to take the help of an external service provider or not.
In-house capability
This dimension comprises of two indexes, i.e., domain expertise and costing. The domain expertise index requires you to evaluate your team on basis of their ability to study the feasibility (both technical and legal) of data extraction from target sites. In the next step you need to assess whether you can have a dedicated engineering team who would be able to develop a seamless crawling infrastructure and take care of the nuances of web data extraction. Given below are the most common issues:
- Crawling dynamic pages at scale
- Writing polite crawlers adhering to the robots.txt file
- Updating the crawler in case of page structure changes
If you are comfortable with these broader factors, then create a costing plan that would have basic elements such as salary of engineers, cost of software tools, proxy services, server cost along with maintenance and upkeep cost.
Check out the ROI calculator here.
Vendor’s Capability
After evaluating the first two primary dimensions, if you believe that a service provider can provide better value addition, then assess the following indexes:
- Reliability
- Ongoing crawler maintenance at scale
- Quality assurance
- Dedicated customer support
In this segment, we need to ensure reliability, which can be further factored into maintenance and data quality. Essentially the vendor should have a robust mechanism and crawling infrastructure to ensure that whenever the website structure changes, they are able to quickly identify the same and update the crawler. They should also have an internal QA team to ensure that the end result is high quality thereby enabling you to apply the data directly into your business.
Another crucial factor is a dedicated customer support team with a strong Service Level Agreement. This will help you quickly react to changing business cases — for instance, when your requirement changes, the support team should be able to swiftly get the crawler updated.
Over to you
You need to decide whether your company has the capability, budget, and need for an internal data scraping team or whether you want to avail the services of a fully managed web data acquisition service provider like PromptCloud, a pioneer in enterprise-grade web data extraction.















