



We’re already in the twilight of this year, and this is the perfect time for us to look back at what we’ve created. Also, worthy to note that during the year closure, the best-of lists ensure that people don’t miss out on anything.
So, this compilation brings you the 10 most popular articles related to web data posted on our blog. This will help you in case anything has slipped.
Without wasting any time, let’s jump in.
Hotel Price Scraping and Optimization Strategy
We started our year with an interesting solution for hotel chains who wanted to maintain competitive pricing and remain profitable at the same time. We spoke about devising the pricing strategy based on the three primary factors — demand forecasting, market response measurement, competitive analysis. All these the factors have several sub-factors which would be weighed for price modelling while accounting for various constraints.
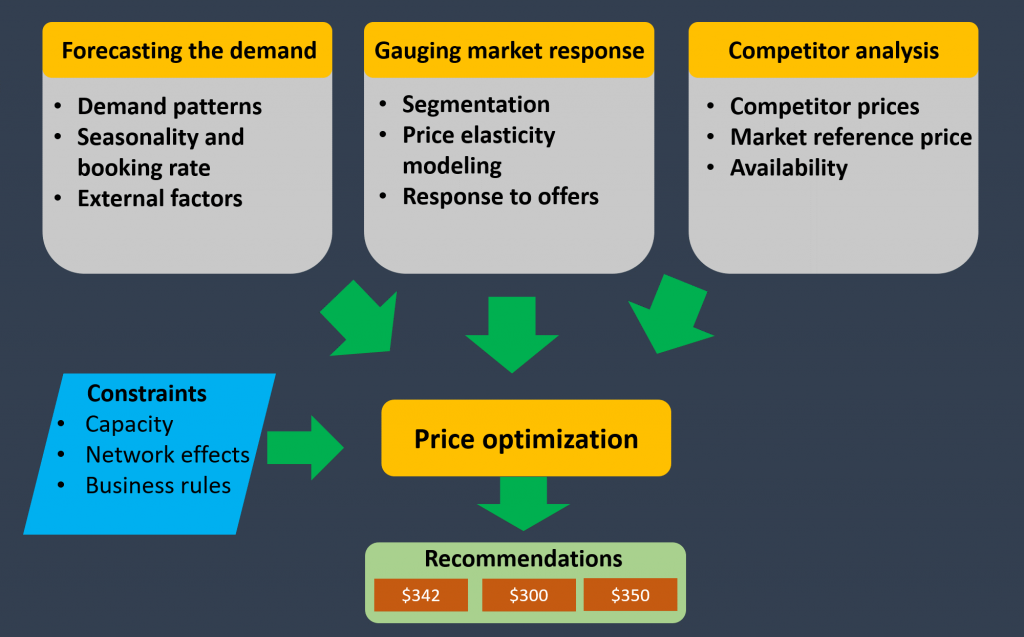
Finally, blending these models with the unique selling points of the hotel business would reveal the pricing which would be compelling for customers.
Visualizing the YouTube Comments on Oscar-Nominated Movie Trailers
In this post, we did an interesting study in the entertainment domain and focused on the Oscars since that’s what the talk was about all around. We extracted the YouTube comments from the Oscar-nominated movies’ trailers and created visualizations.
Here’s what we analyzed:
- Popularity of movies based on comment counts
- Review length distribution
- Top terms used in the reviews
- Sentiment analysis
- Relationship between words – network graph of bigrams
- A word-cloud to find the most commonly occurring words in the comments for “The Shape of Water” trailer.
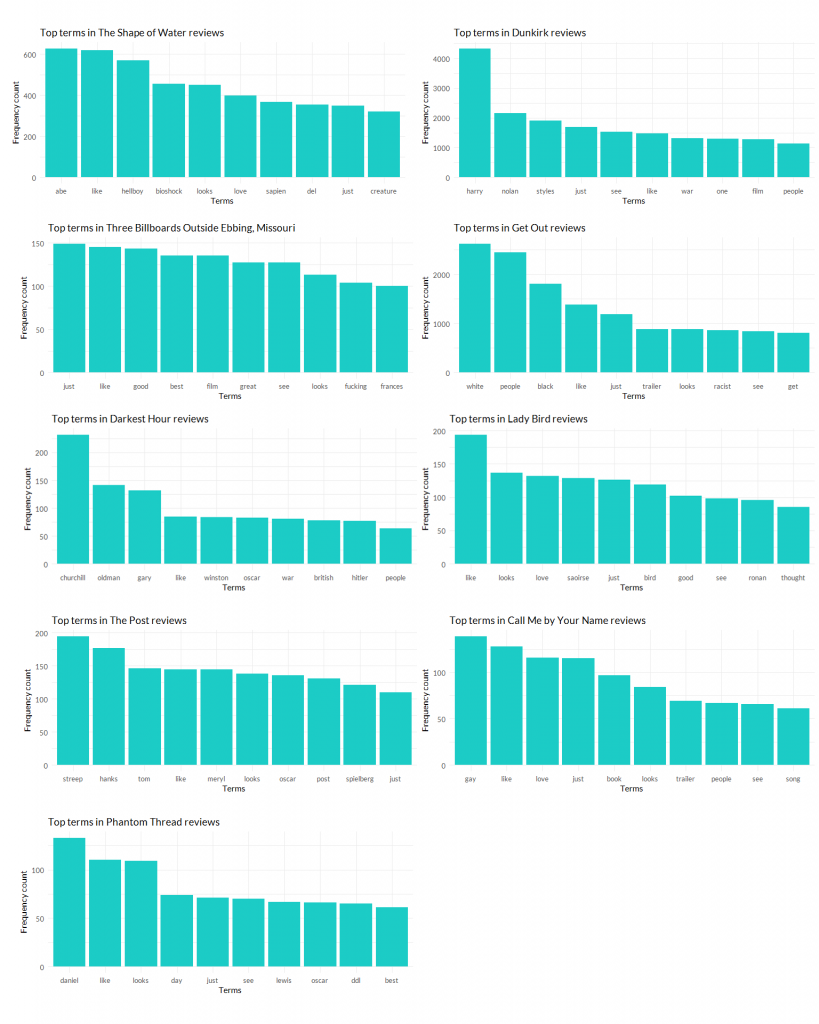
Here is what we uncovered:
- Movie’s popularity isn’t directly tied to winning or nomination
- The Shape of Water got comments with mixed sentiments
- Oscar nomination can change audience’s perception of a movie
How to Convince Your Boss to Collect Web Data
Next we decided to help you convince your boss to collect web data to boost productivity and efficiency of your company. We focused on what you could use in your arsenal and came up with some solid points. You could explain how you could –
- Use data to target Customers better.
- Convert unused data from liability to valuable asset.
- Fuel innovation.
- Boost decision making.
- Increase overall efficiency.
All by using data from web scraping!
The Inevitable Holy Marriage of Machine Learning and Web Scraping
By mid year, when everyone was eating any cake that had “Machine Learning” written on it, we decided to do this piece. We first discussed about web scraping, then about machine learning, and then we actually explained how instead of a human who keeps coming up with new rules for scraping, a machine could keep a scraper running.

Initially a training phase would be required for some time when a real human would keep the scraper going and reward or penalize it depending on its actions to make it learn and relearn.
Is Artificial Intelligence Helping Fast Fashion Grow?
Fast fashion is a contemporary term used by fashion retailers to express that designs move from catwalk quickly to capture current fashion trends. And, currently in the fashion world, the simple algorithms that would suggest trends are obsolete. The data team and design team are using advanced AI to fine-tune the offering — right from finding the color and material to stripe and accessories. We know this, since we’re currently delivering millions of fashions data on daily basis to power some of the fashion-focused AI vendors.

Discovering what customers will fall for next season turns out to be a case of mathematical solution coupled with the creativity of designers.
Data Visualization and Analysis of Taylor Swift’s Song Lyrics
Data analysis can be applied to creative fields like ‘music’ to find out the underlying theme and the changing trend over the years. So, this study was centered on Taylor Swift who has won numerous awards.
Analysis was performed on her 94 tracks to create some fascinating charts and graphs.
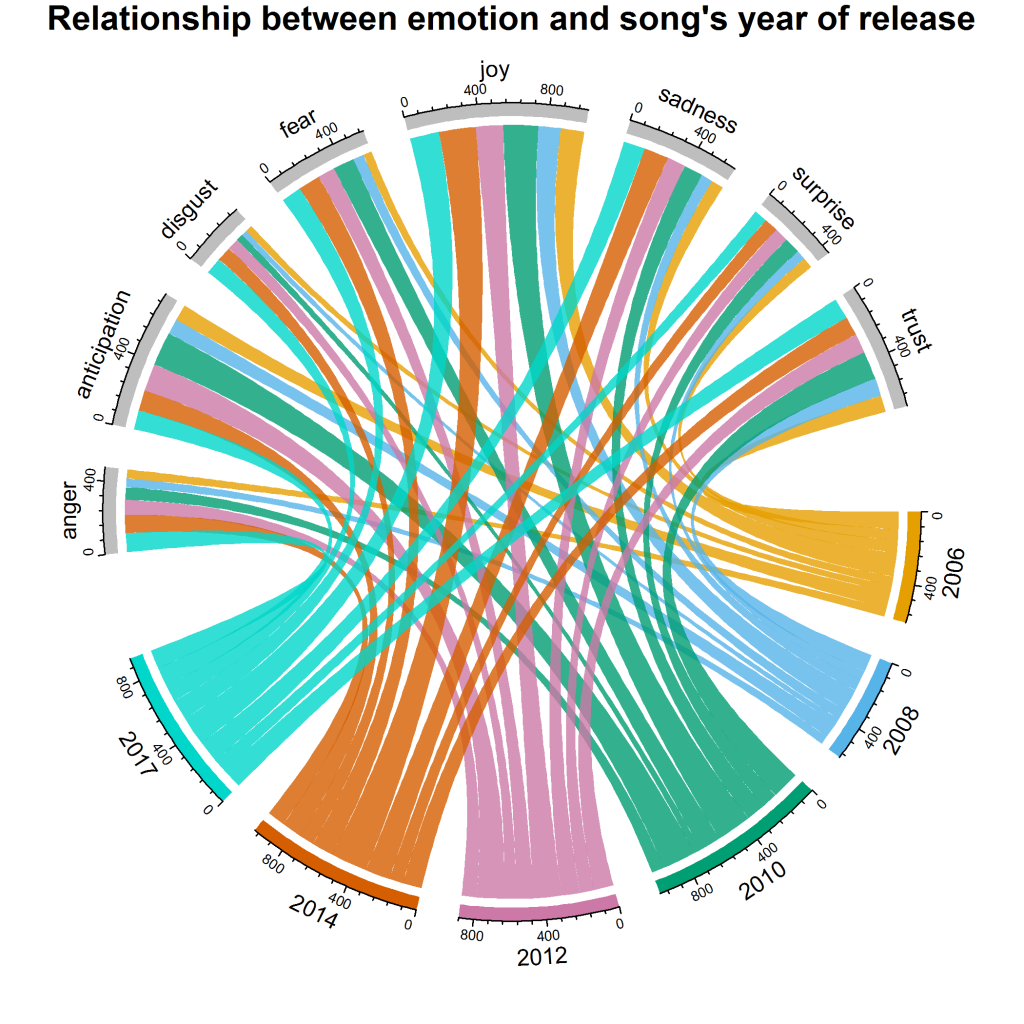
Here is a brief summary:
- Exploratory analysis – we did an analysis of word counts based on individual tracks and albums, time series analysis of the word counts as well as distribution of word counts.
- Text Mining – Here we built a word cloud using all the songs that we explored. We also created a bi-gram network and performed different types of sentiment analysis.
This dataset is available in Datastock for you to play with!
What You Need to Know About Scraping IoT Data
One of the buzzwords of the year has been IoT (Internet of Things), and we decided to explain the opportunities that lies in this field. Although not a popular data scraping environment yet, web scraping can help understand a lot about different IoT devices — how the interaction takes place, and which data might be prone to hacking, etc. Crawling through the data delivered by different hardware devices, as well as their points of connectivity can present huge opportunities for people looking to analyze the entire IoT ecosystem, and create newer and more efficient business processes.
Web scraping in GDPR Era – Impact and Opportunities
With mammoths like Facebook and Google coming under the scanner due to privacy and data security concerns, GDPR, or the General Data Protection Regulation came into effect in Europe. This forced many companies to change operational procedures, data storage and workflow handling, and in some cases, even overhaul the entire infrastructure.
However, this much talked about legislature also brought in a lot of clampdowns and opportunities in the field of Web Scraping. In this article we go deep into what changes will come into effect for data scraping companies and individuals.
Data Analysis Reveals the Spookiest City in the US
During the Halloween month, we decided to go with the spooky spirits and write a piece where we analysed different US cities based on the number of haunted places they had.
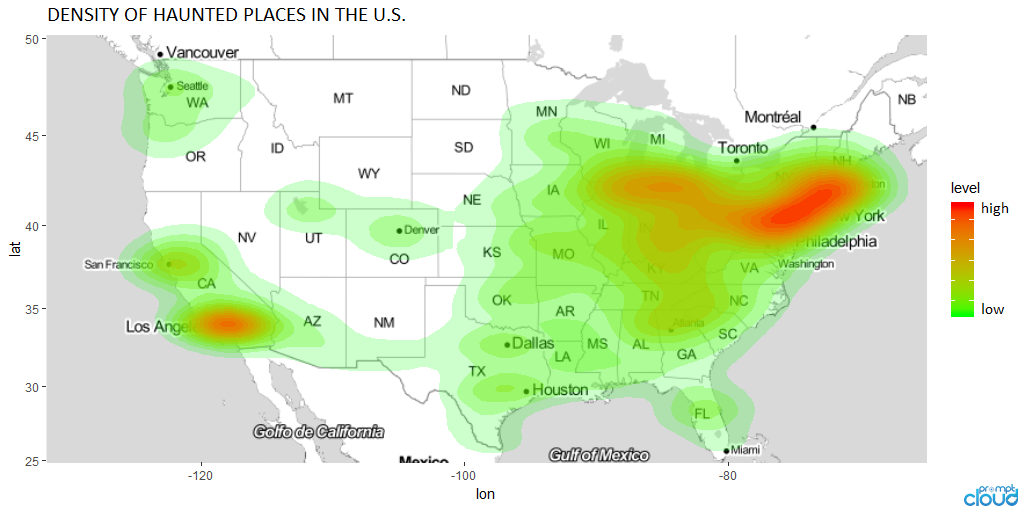
We created a state-wise and city-wise frequency chart as well as a heatmap of the US to make sure that you knew what are the chances of you getting spooked. A word map analysis also helped understand how people describe spooky places and which words are more common in description of these places.
Why is Web Scraping a Better Alternative to APIs?
We kept one of the most debated article for the year end (hoping people would be more merry due to the holiday spirit). Coming to the point, in case you have been using APIs, for your data needs, you must be knowing how easy it is to use them; all you need to do is pass some parameters and you would be getting a JSON/XML in response, which you can then use.

API functionalities generally don’t change frequently and even if a minute change does take place, you will be receiving updated documentation for the same. So, is it better than Web Scraping? Well, as you might have heard, easier is not always the better. Read this end-of-the-year article to find out more.
This wraps up the summary of the articles from the year 2018 that you must read. Comment if you wanted some other article from our blog on this list!
















