




**TL;DR**
Dark web is where privacy advocates and bad actors alike tend to operate. In this guide, we’re breaking down these three layers – how they work, what they’re used for, and why it’s important for businesses to understand them in 2026.
What Is the Surface Web?
The surface web is the public, searchable part of the internet. If a page appears in a search engine when you type a query, it lives on the surface web. Think news sites, open blogs, product pages, documentation, public forums, and most marketing websites.
Key characteristics
- Publicly accessible without a login
- Discoverable by search engine crawlers
- Uses standard HTTP or HTTPS
- Organized through hyperlinks and sitemaps
- Designed to be read by people and indexed by machines
What shows up here
- Product listings and category pages
- Press releases and news stories
- Public knowledge bases and docs
- Open community threads
- Company homepages, pricing teasers, and feature overviews
- Public video pages and transcripts, when indexable
How it gets indexed in simple terms
Common misconceptions
- “The surface web is the whole web.” It is not. It is the visible slice.
- “If it is public, it must be accurate.” Public pages often change, go stale, or contain marketing spin.
- “If Google cannot find it, it does not exist.” Plenty of important content sits behind forms or logins.
Why teams rely on the surface web
- Speed: Data is easy to reach and quick to scan.
- Breadth: You get a wide view of competitors, markets, and topics.
- Awareness: Great for tracking narratives, announcements, and public sentiment.
Where it falls short
- Depth: Public pages rarely expose the full truth about inventory, pricing tiers, or performance.
- Consistency: Layouts change, fields move, and elements may be missing.
- Structure: Content is written for humans, not for analytics, which creates cleanup work.
Practical examples by role
- Category or merchandising: Track visible price moves, promo badges, and new SKUs across retailers.
- Product marketing: Monitor competitor messaging, feature pages, and release notes.
- SEO and content: Map top-ranking topics, on-page patterns, and search intent shifts.
- Analysts and research: Aggregate public reviews, Q&A, specs, and policy changes.
Mini reference table
| Question | Answer |
| Do I need special software | No. Any modern browser works. |
| Can search engines index everything | No. Only what is public and allowed by site rules. |
| Is the data ready for analysis | Not usually. Expect cleaning and normalization. |
| Is it reliable for decisions | Good for signals and trends. Validate before high-stakes actions. |
Data handling tips
- Capture context, not just fields. Note page URL, timestamp, currency, region, and device type.
- Normalize units and formats. Prices, dates, and availability flags vary by site and locale.
- De-duplicate early. Public catalogs and news feeds often syndicate the same content.
- Track change deltas. Storing differences over time reveals real movement, not noise.
- Validate against a schema. Define required fields and reject or flag incomplete records.
Ethical and operational guardrails
- Respect site access rules and rate limits.
- Avoid personal data unless you have a clear, compliant basis.
- Log collection activity and keep an audit trail for stakeholders.
- Align with legal and security teams before building always-on pipelines.
Quick checklist for the surface web
- Clear objective and target fields
- Source list with seed URLs and discovery plan
- Polite crawling settings and retries
- Schema with types and validation rules
- De-duplication and change detection
- Monitoring and alerting for layout shifts
- Storage with versioning and metadata
If the surface web is your storefront window, the deep web is the stockroom and the order system. Ready to go deeper?
Need reliable data that meets your quality thresholds?
Get clean, matched, validated competitor pricing data delivered on your cadence from a managed pipeline built around your catalogue and sources.
Understanding the Deep Web
Let’s be clear, the deep web isn’t some secret underground version of the internet. It’s simply the part that isn’t searchable through Google or Bing. You use it every day without realizing it.
Your email inbox? Deep web.
The checkout dashboard for your online store? Deep web.
That internal analytics portal your team uses? Also deep web.
These pages aren’t shady or illegal. They’re just hidden behind logins, forms, session-based access, or site settings that tell search engines to stay out.
What counts as a deep web?
- Password-protected websites and SaaS dashboards
- Bank accounts, HR platforms, and ERP systems
- Private wikis, internal portals, and CRMs
- Academic journals behind paywalls
- Dynamic content that only loads after user interaction
- APIs that serve real-time data on request
If the content isn’t indexed by a search engine but is accessible to a person or system with the right credentials, it belongs to the deep web.
Why businesses should care
The deep web is where the most accurate and real-time data lives.
Think about this:
- A retailer’s public product page shows list price.
- But behind login, bulk pricing tiers and inventory are revealed.
- The surface web shows you the front. The deep web shows you the reality.
If you’re only scraping the surface, you’re likely missing:
- B2B pricing structures
- Reseller dashboards
- Supplier catalogs
- Private job listings
- Performance benchmarks
- Policy updates before they’re made public
If you’re working with structured data from gated sources like APIs or dashboards, it’s worth reading this breakdown of JSON vs CSV for web crawled data. It’ll help you choose the right format for downstream analysis.
Accessing deep web data
There’s no magic here. You either:
- Use a login-based crawler that mimics real user behavior
- Authenticate via API and fetch structured responses
- Automate browser actions using headless tools like Puppeteer or Playwright
Of course, this all assumes you have permission. Deep web scraping should be ethical, auditable, and compliant with terms of service and data protection laws.
Business use cases
| Use Case | How Deep Web Helps |
| Price Intelligence | Access gated catalogs and volume pricing tiers |
| Workforce Analytics | Scrape login-only job boards or resume platforms |
| Brand Protection | Monitor private seller listings or marketplaces |
| Reseller Oversight | Audit MAP compliance behind restricted portals |
| Competitive Research | View internal tools, content libraries, or changelogs |
| B2B Lead Enrichment | Capture hidden product spec sheets and PDFs |
A few cautions
- Don’t store credentials in plain text. Use secure vaults.
- Rotate IPs and session headers to stay undetected but respectful.
- Implement fallback flows when logins fail or CAPTCHAs appear.
- Get explicit client sign-off if scraping from partner platforms or portals.
The deep web is where serious insights live. If the surface web tells you what’s happening in public, the deep web tells you what’s really driving it behind the scenes.
How Crawlers See the Internet
Web crawlers are the bots search engines use to discover and understand websites. Think of them as tireless readers that follow every link they find, grab a snapshot of the page, and feed it back to the search engine’s index.
But here’s the catch. Crawlers don’t see the web the way humans do. They can’t:
- Log into accounts
- Click buttons or fill forms (unless specifically programmed to do so)
- Wait for JavaScript to load dynamic content
So while a person can navigate a login page and see product availability or custom pricing, most crawlers will hit a wall and move on.
What determines crawlability?
A page gets crawled and indexed if:
- It is publicly linked from another page
- It is not blocked by a robots.txt file
- It does not require login or JavaScript interaction to load content
- It uses standard protocols and loads without excessive redirects
Common reasons pages go unseen
| Blocker | What Happens |
| Requires login | Crawler sees a blank or redirected page |
| Uses JavaScript rendering | Crawler misses out on content loaded after click |
| Blocked by robots.txt | Crawler skips it entirely |
| Rate limited or IP blocked | Crawler is denied access |
Why it matters for your data strategy
If your scraping or monitoring tools rely only on crawling public pages, you will miss:
- Real-time pricing changes that only show up after a user logs in
- Region-specific content that depends on cookies or headers
- Feature announcements buried in internal documentation or changelogs
- Seasonal discount pages that require interaction to display
This is especially true for businesses tracking competitors, ad performance, or product availability. If you are only pulling from what Google can index, your insights are probably incomplete.
Marketers who scrape Google Ads, SERPs, or competitor landing pages know this well. Our guide to Google Adwords Competitor Analysis breaks down how to detect changes in copy, targeting, and funnel behavior using scraping techniques that go beyond crawling.
Crawling vs scraping: the key difference
- Crawling is about discovery. It helps build a map of what exists.
- Scraping is about extraction. It turns visual content into structured data.
Crawlers help you find pages. Scrapers help you understand and use the data on those pages. To build effective data pipelines, you often need both.
What Is the Dark Web?
The dark web is probably the most misunderstood layer of the internet. People often assume it is just a hidden corner where illegal things happen.
Key traits of the dark web
- Not indexed by search engines
- Uses .onion domains that are not listed anywhere public
- Requires a privacy-focused browser like TOR to access
- Designed for anonymity, not visibility
- Used by both privacy advocates and cybercriminals
Legal vs illegal use
Legitimate examples:
- Whistleblowers submitting files to journalists
- Journalists hosting mirrors of news sites for censored audiences
- Privacy-focused services like ProtonMail and DuckDuckGo offering .onion versions
Illegal use cases:
- Selling stolen data or passwords
- Running unlicensed drug marketplaces
- Hosting hacking forums and exploit kits
- Distributing malware, ransomware, or counterfeit documents
The legality depends not on how you access the dark web but on what you do there.
Accessing the dark web: what to know
To access the dark web, you install a browser like TOR that connects through its own network. Each request passes through multiple servers, with each one only knowing the next hop. This is called onion routing. Websites use .onion domains, which look like long strings of letters and numbers. They are hard to remember, hard to guess, and often unstable. Many go offline within days or weeks.
Want to understand how this part of the web behaves from a technical point of view? We covered it in our GeoSurf Alternatives 2026 piece where privacy-focused proxies and access layers play a key role in handling scraping and monitoring on the dark web.
Who uses it in business?
Dark web monitoring is growing quickly across industries like:
- Financial services
- Cybersecurity
- Ecommerce
- Digital products and SaaS
Why? Because this is often where the earliest signs of a problem appear. If a batch of leaked credentials shows up on a TOR forum, it usually lands there before anywhere else. Most companies rely on managed intelligence services or scraping partners who specialize in safe, secure data collection across anonymous networks.
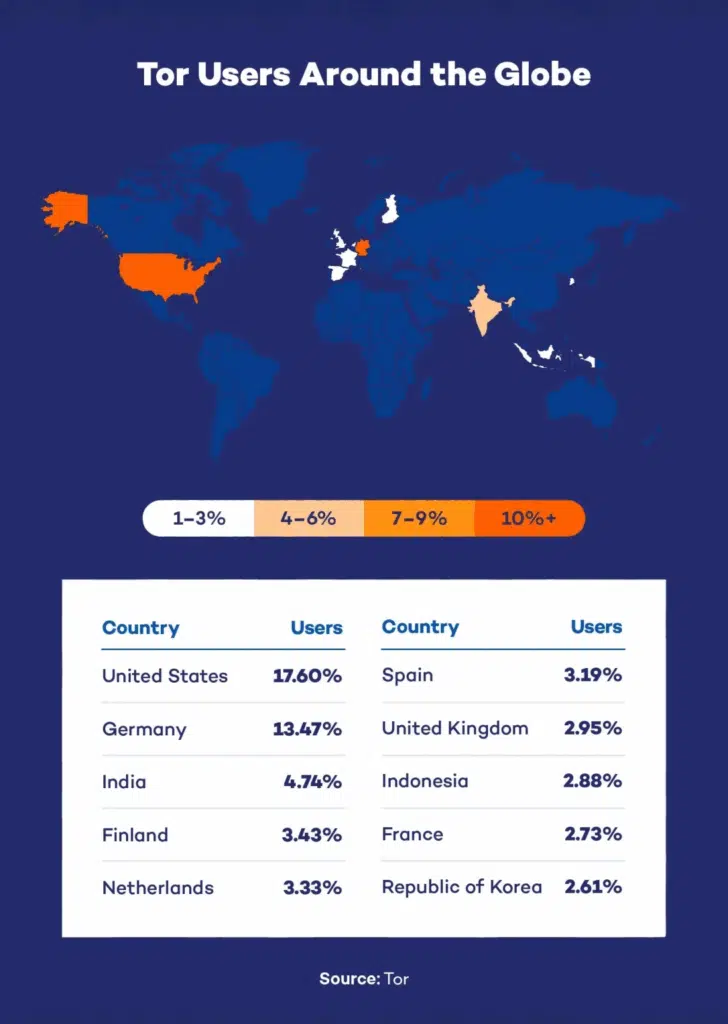
Note: The image has been sourced from: https://www.pandasecurity.com/en/mediacenter/dark-web-statistics/
How the Dark Web Works
The dark web is simply hidden from search engines.
How onion routing works
Imagine you want to send a letter through/across multiple mailboxes, each inside the next like a layer. That is how your request moves through the TOR network.
- First, your message is encrypted multiple times.
- Then, it is sent to the first TOR node, which peels off the outer layer and forwards it.
- Each and every node only knows the previous + next hop, never the full path.
- Eventually, the final node sends the request to the destination site.
The same process happens in reverse when data comes back to you. At no point does any single server know both who you are and what you are doing. That is what makes tracing so difficult.
What .onion sites are
Websites on the dark web do not use domains like .com or .org. Instead, they use .onion addresses. These are not registered in a public DNS system. They are generated cryptographically and often look like random strings, such as:
http://duskgytldkxiuqc6.onion
These domains are not listed on search engines. They are often shared on forums, word-of-mouth, or inside private communities.
Many .onion sites are unstable. They go offline quickly or change addresses to avoid detection. Scraping them requires patience, error handling, and a flexible system that can detect and respond to changes.
Challenges with scraping the dark web
- Speed is slow due to the relay-based routing.
- Uptime is unpredictable. Many sites vanish or move frequently.
- Detection is common. Sites often block bots or scrape attempts.
- Legal exposure is real. Collecting the wrong type of data, or from the wrong source, can put you at risk.
This is why most businesses that want access to the dark web for threat monitoring or data collection do not go it alone. They work with managed data providers who already have the tools, legal vetting, and infrastructure to do it right.
What kind of data appears here
- Leaked databases and credentials
- Stolen payment info or identity documents
- Early chatter about upcoming hacks or breaches
- Brand impersonation or clone websites
- Discussions of exploit kits or malware
- Blacklists or scam directories
- Product reviews and community trust signals for illegal sellers
This data is not just interesting. It can be critical for early warning systems, digital risk protection, and fraud detection.

Note: The image has been sourced from https://www.pandasecurity.com/en/mediacenter/dark-web-statistics/
Comparing Surface, Deep, and Dark Web
By now, you’ve probably noticed that these three layers are not just about visibility. Each has its own logic, purpose, and users. Let’s pull it all together.
At a glance
| Attribute | Surface Web | Deep Web | Dark Web |
| Search engine visibility | Yes | No | No |
| Login required | Sometimes | Often | Often |
| Special software needed | No | No | Yes (TOR or similar) |
| Legal risk | Low | Low to moderate (based on access method) | High (based on activity, not access) |
| Common users | General public | Businesses, professionals | Privacy advocates, criminals, security researchers |
| Example data | Product pages, blogs | Job boards, SaaS dashboards | Leaked data, counterfeit listings, exploit kits |
| Business use cases | SEO, market research | Competitive pricing, inventory tracking | Brand monitoring, threat intelligence |
How they connect in the real world
You might be using all three layers already without realizing it.
- A marketing analyst scrapes product pages (surface), logs into retailer portals for inventory data (deep), and gets alerts about fake resellers on TOR (dark).
- A cybersecurity team monitors news sources (surface), scans partner portals for exposure (deep), and tracks brand mentions in dark web marketplaces.
- A pricing strategist pulls public prices from Google Shopping (surface), logs into B2B buyer tools for volume discounts (deep), and watches the dark web for signs of data breaches affecting customers or suppliers.
Each layer answers a different type of question:
- What is visible to everyone? Surface web.
- What are partners or competitors doing behind the scenes? Deep web.
- What threats are forming out of view? Dark web.
Why clarity matters
When teams confuse these layers, they either:
- Over-simplify their data strategy and miss key signals
- Cross legal or ethical lines without realizing it
- Waste time trying to extract public data with tools built for private systems
On the flip side, teams that treat each layer appropriately tend to build stronger, more reliable pipelines. They know when to crawl and when to authenticate. When to monitor and when to act. When to explore, and when to hand off to experts.
Choosing the Right Layer for the Job
Every team does not need to access every part of the web. It depends on the goal, the data type, and how fast or deep you need to go.
Use this as a simple guide:
Surface web is best when you need
- Broad awareness of public pricing, products, or narratives
- Quick checks on changes in content, tags, or visibility
- External sentiment signals from blogs, forums, or news
Ideal for: SEO, public monitoring, review aggregation, quick scraping setups
Deep web is best when you need
- Accurate, up-to-date information behind logins or portals
- Structured datasets from secure tools or APIs
- A reliable source of truth, not just a snapshot
Ideal for: Pricing intelligence, workforce analytics, policy tracking, product monitoring
Dark web is best when you need
- Early warning about cyber threats, leaks, or brand impersonation
- Exposure monitoring for high-risk data or assets
- Intelligence from less visible sources
Ideal for: Security, compliance, fraud prevention, risk analysis If you try to use surface scraping to do deep web monitoring, or attempt dark web monitoring without safeguards, the results will be messy at best and dangerous at worst. On the other hand, if you know where your data lives and what it takes to extract it properly, the payoff is fast, clear, and scalable.
Need reliable data that meets your quality thresholds?
Get clean, matched, validated competitor pricing data delivered on your cadence from a managed pipeline built around your catalogue and sources.
FAQs
1. What is the difference between surface web, deep web, and dark web?
The surface web is public and indexed by search engines. The deep web includes content that requires login or is not indexed, such as portals or paywalls. The dark web is a hidden, encrypted part of the deep web accessed through special tools like the TOR browser.
2. Is it legal to access the dark web?
Yes. Using TOR and visiting .onion sites is legal in many countries. However, participating in illegal activity on the dark web is not. The legality depends on what you do, not just how you access it.
3. Can search engines see the deep web?
No. If a page is behind a login, form, or blocked using robots.txt, search engines cannot crawl or index it. This is why many business-critical pages are invisible to Google or Bing.
4. How do companies monitor the dark web safely?
Most work with managed providers who specialize in monitoring known threat sources. They use secure proxies, alerting tools, and keyword tracking to surface relevant information without exposing internal systems.
5. Is deep web data useful for AI and machine learning?
Absolutely. Deep web sources often contain rich, domain-specific content that is ideal for fine-tuning models. This includes structured product data, job descriptions, FAQs, policies, and support logs that are more relevant than general surface content.















