




What Are Proxies and Why Do You Even Need Them for Web Scraping?
Let’s be real, web scraping sounds straightforward at first. You write a script, point it at a website, and boom, data comes pouring in. Except… that’s not how it usually goes. Most sites don’t like being scraped, especially at scale. They’ll throw up roadblocks fast, IP bans, CAPTCHAs, or just flat-out block you without warning.
That’s where proxies come in.
Think of proxies as different faces you can wear on the internet. Instead of sending all your scraping requests from your real IP address (which gets noticed and flagged pretty quickly), you send them through a bunch of other IPs. That way, all those requests come from different people in different places.
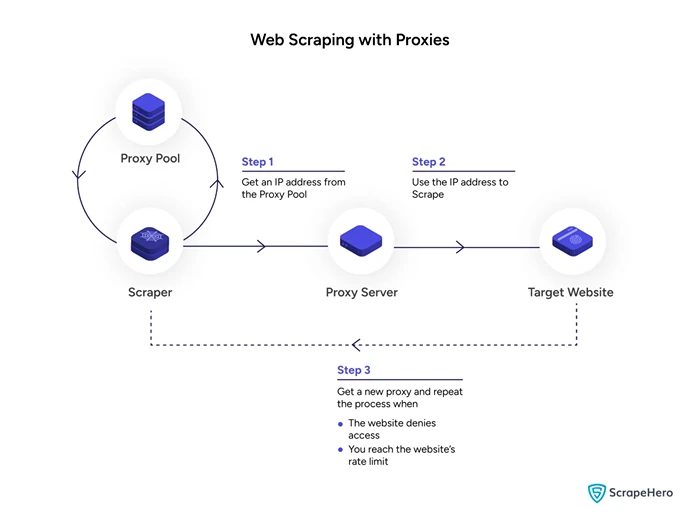
Image Soure: scrape hero
It’s not just about hiding your tracks. Sometimes you need to look like you’re in another country to see local prices or search results. Or maybe you just want your scraper to run smoothly without interruptions. Either way, proxies make that happen.
Bottom line: if you’re scraping at scale and not using proxies, you’re asking for problems. You’re going to get blocked. You’re going to waste time. And eventually, you’ll hit a wall. Proxies are what help you scale scraping without constantly putting out fires.
Why Proxies Matter When You’re Scraping at Scale
So now that we’re on the same page about what proxies are, let’s talk about why they’re so important when you’re scraping large amounts of data.
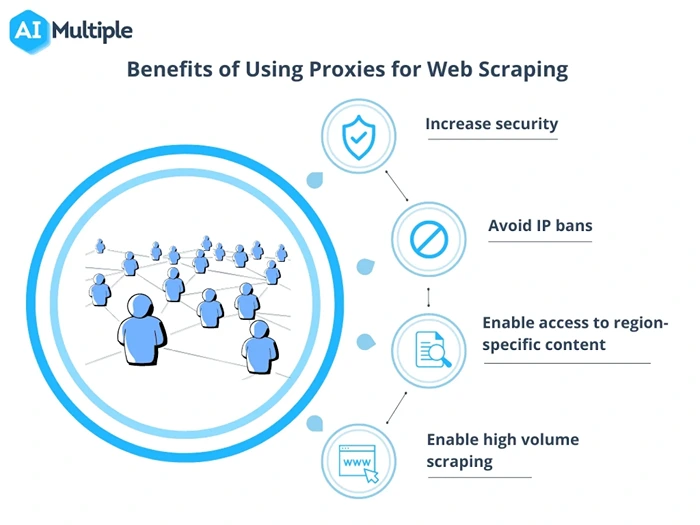
Image Source: AI Multiple
First off, your IP address has limits
Every time you send a request to a website, your IP address is basically your digital name tag. If that IP starts hammering a site with hundreds or thousands of requests, the site’s security systems take notice. And when that happens? You get blocked. No warnings, no second chances—just blocked.
Using proxies spreads your requests across many different IPs, so you don’t trip those alarms. It’s like dividing the work among a team instead of one person doing everything and getting exhausted.
Geo-targeted content? You’ll need proxies for that
Let’s say you’re tracking flight prices, hotel listings, or local e-commerce deals. A site might show totally different results to someone browsing from New York versus someone in Berlin. If you’re only scraping from one IP in one location, you’re missing the full picture.
Proxies for web scraping let you act like you’re in different parts of the world, so you can pull geo-specific data. This is huge for businesses doing price comparisons, market research, or competitive analysis across regions.
They help keep things stable
When you’re running scrapers at scale—millions of rows of data, thousands of pages—uptime matters. You don’t want to keep restarting jobs or troubleshooting blocks. Proxies help smooth things out by reducing failures, avoiding bans, and keeping your scrapers alive longer.
In short, without proxies, scaling your scraping operation is like trying to run a marathon in flip-flops. You might get somewhere, but it won’t be pretty.
Types of Proxies You’ll Run Into (and Which Ones Work for Scraping)
Not all proxies are created equal. Some are fast but easy to block. Others are super reliable but way more expensive. So if you’re thinking, “Alright, I get that I need proxies—but which kind?”, this is where it gets interesting.
Let’s break down the main types you’ll come across.
1. Datacenter Proxies
These are the most common and the cheapest. They come from cloud providers, not from real people’s devices. That means they’re fast, easy to get in bulk, and great when you need to send a ton of requests quickly.
But there’s a catch: websites can spot them a mile away. Because they don’t belong to real users, sites know they’re coming from data centers. So if the site you’re scraping is strict about blocking bots, datacenter proxies might not cut it.
Still, they work fine for less protected websites or quick one-off scraping jobs.
2. Residential Proxies
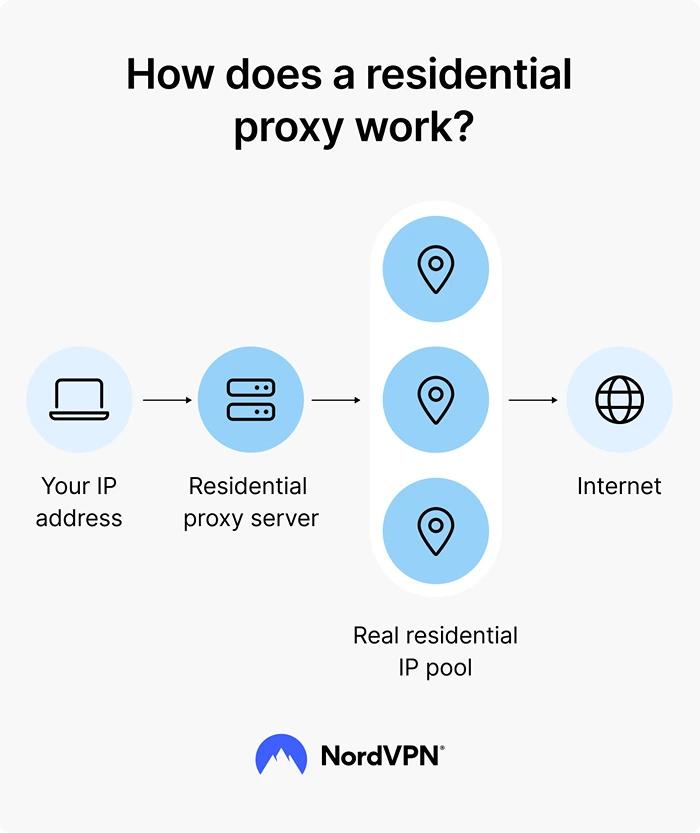
Image Source: NordVPN
These come from actual devices, think home Wi-Fi connections. So when your scraper uses a residential proxy, it looks like a normal person browsing from their laptop or phone.
That’s a big deal. Sites are way less likely to block these because there’s no easy way to tell they’re part of a scraping operation. If you’re dealing with tougher targets—like travel sites, e-commerce platforms, or search engines- residential proxies give you a much better shot at staying under the radar.
The downside? They’re pricier. But for serious scraping projects, they’re usually worth it.
3. Mobile Proxies
These are like residential proxies, but they come from mobile networks. That makes them even harder to detect, because mobile IPs are often shared across users and change frequently.
They’re crazy effective but also expensive and a bit slower. Most people don’t need mobile proxies unless they’re scraping mobile-specific content or getting blocked even with residential IPs.
4. Rotating Proxies
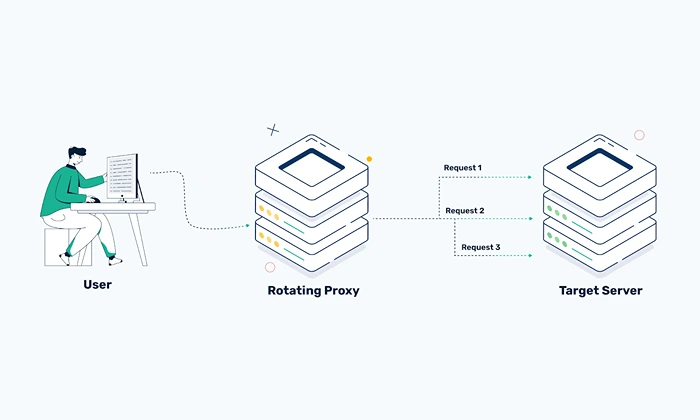
Image Source: webshare.io
This isn’t a different kind of proxy, it’s more about how you use them. With rotating proxies, your IP changes automatically after every request or every few minutes. That makes it way harder for sites to detect patterns and block you.
You can rotate datacenter IPs, residential IPs, or even mobile ones. Rotation is basically a must-have if you’re scraping at scale. It’s the difference between sending 500 requests and getting blocked, or sending 50,000 and flying under the radar.
How to Choose the Right Proxies for Web Scraping (It Depends on What You’re Scraping)
Okay, so you’ve got a few proxy types to pick from—datacenter, residential, mobile, rotating. Now the big question is: which one should you actually use?
The answer depends on what you’re scraping, how much of it you’re scraping, and how much friction you’re running into.
Scraping an e-commerce site?
If you’re pulling product listings, prices, or inventory data from online stores, especially big ones like Amazon, Walmart, or Flipkart, residential proxies are usually the way to go. These sites are super sensitive to bot activity. If you show up with a datacenter IP, you’ll probably hit a CAPTCHA or get blocked almost immediately.
Rotating proxies also help here. A fresh IP on every request makes your scraper look more human, especially if you’re crawling thousands of SKUs.
Need location-specific data?
Let’s say you’re comparing hotel prices or checking how a product ranks in search results across different cities or countries. In that case, you’ll want proxies with geo-targeting. This is where residential and mobile proxies shine. You can pick IPs from specific regions so your scraper sees exactly what a user in that location would see.
Datacenter proxies won’t help much here unless you get lucky and find ones in the right country and even then, they might not be trusted by the site.
Focused on speed and volume over stealth?
If you’re scraping a site that doesn’t fight back too hard, maybe a public directory or a lightly protected news site, datacenter proxies are probably good enough. They’re fast, affordable, and you can send a lot of requests without burning a hole in your budget.
Just be ready to rotate them and expect occasional bans. These are your “get the job done, quick and cheap” options.
Watching your budget?
Look, not every project has deep pockets. If you’re still in the early stages or doing some proof of concept work, it’s okay to start with datacenter proxies and test the waters. But once you start scaling or hitting roadblocks, you’ll likely need to upgrade to residential.
TL;DR (but still readable): Match your proxy type to your goal
- If you’re scraping heavily protected sites, go residential or mobile.
- If you’re scraping at high volume, go datacenter but rotate often.
- If you need local content, use geo-targeted residential or mobile proxies.
- And always think ahead—cheap proxies might work today, but can crash your scraper tomorrow.
How to Use Proxies for Web Scraping Without Wasting Time or Getting Banned
So now you’ve picked the right type of proxies for your scraping project. Nice. But the work doesn’t stop there. If you don’t use those proxies the right way, you’ll still end up running into problems—bans, bad data, broken scrapers.
Let’s talk about how to avoid that.
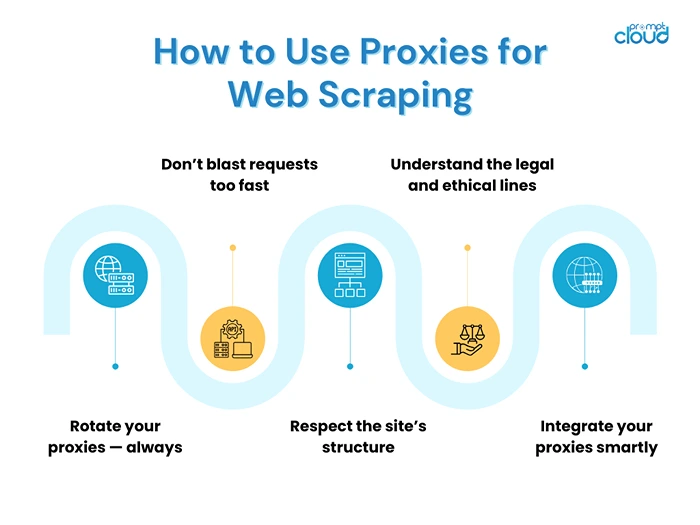
Rotate your proxies — always
You wouldn’t visit the same store every five seconds wearing the same clothes and expect not to get weird looks, right? The same logic applies to scraping.
If you keep hitting a site from the same IP again and again, even the best proxy in the world won’t save you. That’s why rotating proxies are so useful—they keep switching out your IP so it looks like different users are browsing. You can rotate after every request, or every few minutes, depending on how aggressive the site is.
Pro tip: if you’re seeing CAPTCHAs or weird error pages, it probably means your rotation strategy needs work.
Don’t blast requests too fast
Websites don’t like getting hammered with 50 requests per second. That’s not how normal users browse, and it sets off alarm bells. Spread out your requests a bit. Add random delays between them. Some scraping frameworks let you control this with throttling settings, it’s worth using.
Even with proxies, sending too many requests from the same IP too quickly is asking for a ban. Pace yourself.
Respect the site’s structure
Scraping shouldn’t feel like smashing your way through a wall. If a site has an obvious layout, say, paginated product pages, follow that structure instead of brute-forcing every URL. It’s easier on the site and more efficient for you.
And while we’re on it: always check if there’s an API first. If a site offers a public or paid API, that might be a cleaner option than scraping. (Of course, APIs can be limited, which is why scraping still matters.)
Understand the legal and ethical lines
Here’s the deal web scraping isn’t illegal, but there are lines you shouldn’t cross. Don’t scrape personal data. Don’t overload servers. And always double-check the site’s Terms of Service. Some platforms explicitly say scraping isn’t allowed. That doesn’t mean you can’t do it, but you should know the risks and tread carefully.
PromptCloud, for example, focuses heavily on compliant data extraction, meaning we only scrape publicly available information, and we follow best practices to avoid unnecessary strain on websites.
Integrate your proxies smartly
Some people plug proxies into their scrapers like an afterthought. Don’t do that. A good setup lets you manage proxies cleanly—rotate them, retry failed requests with a new IP, and monitor which ones are performing best.
If you’re using tools like Scrapy, Puppeteer, or Selenium, some libraries and middlewares help with this. If you’re working at a serious scale, you’ll probably want a proxy provider that offers a management dashboard or API access so you’re not manually babysitting everything.
Why Proxies Aren’t Optional for Web Scraping
Here’s the thing—if you want to scrape data at scale and not have your efforts shut down by a bunch of technical roadblocks, you need proxies. It’s as simple as that.
Proxies are like your secret weapon to stay anonymous, keep your IP from getting banned, and access content without those annoying rate limits or CAPTCHAs. Whether you’re tracking prices, gathering market data, or just pulling down tons of content, proxies are what keep your scrapers running smoothly. Without them, you’re basically just asking for trouble.
But it’s not just about using proxies. It’s about choosing the right ones for what you need. Residential proxies, rotating proxies, datacenter proxies—each has its strengths, and you’ll need to match them to your scraping goals. Otherwise, your operation might slow down, or worse, fail completely.At PromptCloud, we understand this better than anyone. We’ve built our platform to handle large-scale, reliable data extraction with smart proxy management built right in. So, if you’re ready to start scraping without running into roadblocks, we’ve got the tools and the expertise to make it happen. Contact us today!















