




What are the Web Data Challenges for Enterprises?
Web scraping didn’t suddenly get harder in 2026. It got less forgiving. Most pipelines fail now not because of one big blocker, but because of many small ones stacking up quietly. Anti-bot systems that adapt mid-session. JavaScript that changes per user. Layouts that mutate without warning. Compliance rules that vary by geography and intent. If your scraper still assumes fetch, parse, done, you’re already behind.
10 Challenges of Scaling Web Data Pipelines in 2026
Early-stage web data pipelines are forgiving. If a scrape fails, someone reruns it. If freshness slips, the dashboard still looks close enough. If fields drift, downstream teams patch around it. Nobody panics because nothing important is wired directly to the output. That illusion disappears the moment the pipeline becomes enterprise-facing.
Data starts feeding pricing engines. Compliance teams ask questions. Legal wants provenance. Product teams assume availability. And leadership wants guarantees that were never designed into the system.
This is where most pipelines unravel. Not because the scraping suddenly got harder, but because the operating model never caught up. Ownership stays fuzzy. Change management is informal. Monitoring exists, but only for uptime, not correctness. Everyone assumes someone else is watching.
Enterprise scale exposes what experiments hide. Silent failures become business risks. Good enough freshness turns into SLA breaches. Ad-hoc fixes become permanent liabilities.
This article breaks down the real web data pipeline challenges that surface at enterprise scale. Not tool limitations. Not surface-level errors. Structural weaknesses that only show up once the pipeline matters.
We’ll start with the most common one. The moment reliability becomes a promise instead of a hope.
Trusted by enterprise data teams across retail, finance, and AI platforms processing billions of records annually.
“PromptCloud helped us transition from fragile ingestion scripts to SLA-backed web data infrastructure within one quarter.”
VP Data Engineering
Global Marketplace
Get clean, structured, compliance-ready web data on the cadence you need, with nothing to maintain.
Many of these failures trace back to issues first seen in scraping systems themselves. As outlined in our breakdown of web scraping challenges in 2026, instability at the source compounds rapidly at the pipeline layer.
Challenge 1: Pipeline Reliability at Enterprise Scale
In experimental pipelines, reliability is implicit. The job usually runs. When it doesn’t, someone notices. That’s enough. No one asks what “reliable” actually means because nothing critical depends on it yet.
Enterprise systems don’t get that luxury. Once web data feeds business logic, reliability stops being binary. It’s no longer “did the pipeline run?” It becomes a matrix of expectations. Did it run on time? Did it complete fully? Did it deliver the same shape of data? Did downstream systems get what they expected?
Most pipelines fail this transition. They were built around scripts and schedulers, not contracts. Retries exist, but without limits. Partial failures pass silently. Upstream instability leaks downstream because isolation was never planned. The result is a fragile equilibrium. Everything works until one source slows down, one schema changes, or one volume spike hits. Then the entire system degrades in ways that are hard to trace.
At enterprise scale, reliability is not an outcome. It’s an architectural decision. You either design for failure containment and predictability, or you inherit chaos with better logging.
This is also where compliance and reliability intersect. When failures happen, teams are expected to explain what broke, when, and why. If your pipeline can’t answer those questions, it’s not enterprise-ready, regardless of how often it runs. We’ll go deeper into that intersection later, because governance pressure tends to surface reliability gaps faster than engineering does.
Next, we’ll look at what breaks once data freshness turns from nice to have into a contractual expectation.
Challenge 2: Data Freshness SLAs in Web Data Pipelines
In the experimental phase, freshness is a suggestion. Data arrives daily. Or every few hours. Nobody checks the exact timestamp unless something looks obviously wrong. If a job runs late, it’s annoying, not dangerous.
At enterprise scale, freshness becomes contractual. Someone depends on it. Often more than one team. Pricing assumes today’s prices. Risk models assume current listings. Analytics assumes no gaps. Suddenly, “the job ran” is meaningless if the data is six hours late or silently stale. This is where many web data pipelines fall apart.
Freshness is rarely enforced as a first-class signal. Pipelines track job success, not data age. A scrape can succeed while returning yesterday’s content because a site throttled, cached, or degraded responses. From the system’s point of view, everything is green.
From the business’s point of view, it’s a breach. The hard part is that freshness is not uniform. Some sources change hourly. Others weekly. Some fields need near-real-time updates. Others tolerate lag. Most pipelines flatten all of this into a single schedule and hope it works.
At scale, hope stops working.
Teams that survive this transition treat freshness as metadata, not timing. They record when data was observed, not just when it was processed. They set expectations per source and per field. And they alert on violations of those expectations, not just on crashes. Once freshness becomes a promise, you can’t bolt it on later. You have to redesign how the pipeline understands time.
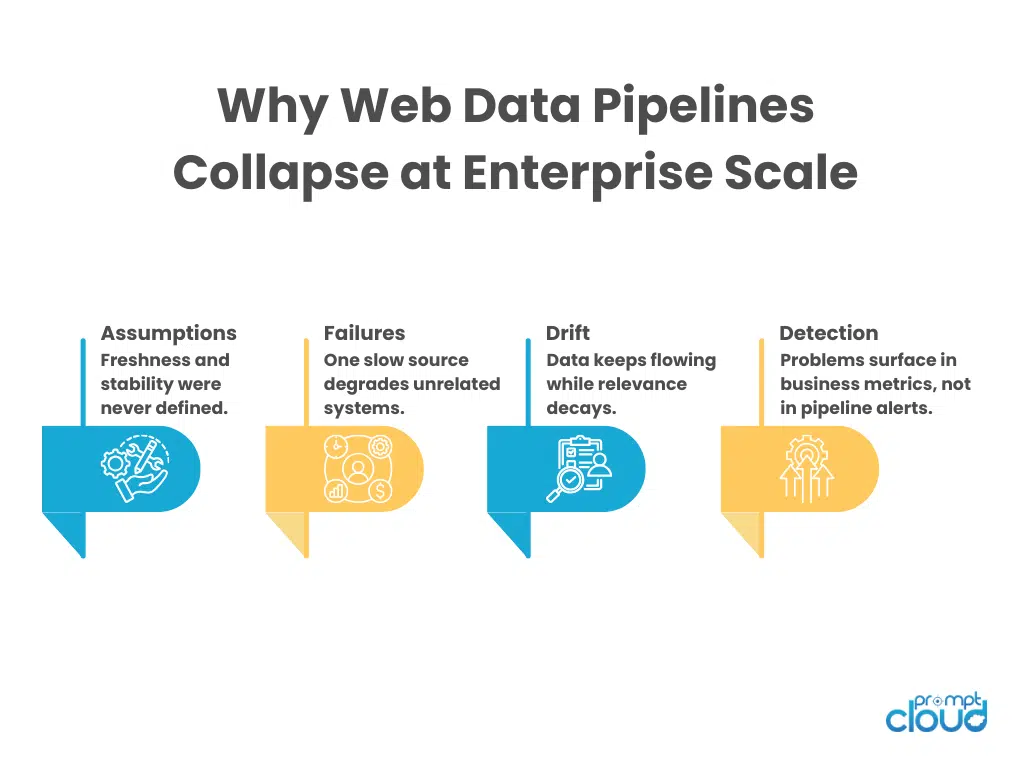
Figure 1: The hidden failure pattern that emerges when experimental web pipelines become enterprise dependencies.
Next up, we’ll get into a quieter problem that causes just as much damage: schema drift that doesn’t break pipelines but breaks trust.
See how PromptCloud builds enterprise-grade web data infrastructure.
Challenge 3: Schema Drift in Enterprise Web Data Pipelines
Schema drift used to be loud. A field disappeared. A type changed. The job failed. Someone fixed it. That failure mode is almost comforting compared to what happens at enterprise scale. In large web data pipelines, schema drift is usually soft.
Fields still exist. Names don’t change. Types remain technically valid. But meanings shift. A “price” field starts including tax. A “status” field gains new values. A nested attribute appears only for certain regions. Nothing crashes, but downstream logic slowly stops making sense. This is why schema drift is one of the most damaging web data pipeline challenges in enterprise environments.
Pipelines validate structure, not semantics. They check that a field exists, not whether it still represents the same concept. As long as records conform to a shape, they flow through. By the time someone notices odd behavior, the drift has already propagated into reports, models, and decisions.
The real problem is ownership. No one owns the schema as a contract. Extraction teams assume downstream teams will adapt. Downstream teams assume upstream changes will be communicated. In practice, neither happens consistently.
At enterprise scale, schemas must be versioned, documented, and defended. Changes need review. Backward compatibility needs planning. And most importantly, pipelines need a way to detect meaningful change, not just missing fields. If your system can’t tell the difference between “same shape” and “same meaning,” trust will erode long before anything fails visibly.
In our analysis of enterprise web data pipelines, schema drift accounts for over 40% of silent downstream data quality incidents. Most were not caused by field removal, but by enum expansion and semantic changes that passed structural validation.
Next, we’ll move into an issue that often gets mislabeled as “infra problems,” but is really about incentives and control: pipeline reliability without clear ownership.
Challenge 4: Ownership Gaps in Enterprise Data Pipelines
This is about who is accountable when reliability breaks.
This is where scaling web data pipelines starts to feel political. In early setups, one team usually owns everything. Scraping, processing, and delivery. When something breaks, the fix is messy but straightforward. Everyone knows who’s responsible.
Enterprise scale shatters that clarity. Scraping lives with one team. Ingestion with another. Storage with a platform. Consumers span analytics, product, and sometimes external clients. Reliability issues surface in one place and originate in another. Nobody has the full context, but everyone feels the impact. This is how pipeline reliability becomes fragile even when the tech is solid.
Alerts fire, but they’re routed to the wrong team. Failures are acknowledged but not acted on because ownership is ambiguous. Fixes get delayed while people debate whether the issue is upstream, downstream, or “expected behavior.” The hidden cost here is latency in response, not just downtime.
Enterprise systems need explicit ownership boundaries. Not just org charts, but operational contracts. Who owns freshness guarantees? Who approves schema changes? Who decides when a source is too unstable to meet delivery SLAs? Without those answers, teams start optimizing locally. Scraping teams push volume. Platform teams optimize throughput. Consumers assume correctness. The pipeline technically runs, but reliability is accidental.
At scale, reliability is not enforced by code alone. It’s enforced by accountability. If no one is empowered to say “this pipeline is out of spec,” then everything slowly becomes acceptable, including failure.
Next, we’ll examine what happens when change management stays informal while the pipeline becomes business-critical, and why most enterprise outages trace back to this gap.
Challenge 5: Change Management in Scaling Web Data Pipelines
This is about how changes are introduced into the system.
This is one of the fastest ways enterprise pipelines get brittle. In experimental setups, change management is informal by design. Someone tweaks the extraction logic. Another adjusts a schedule. A third adds a new field. If something breaks, the same people are usually in the same room or thread.
That stops working the moment the pipeline becomes shared infrastructure. At enterprise scale, every change has a blast radius. A small tweak to parsing logic can affect pricing. A crawl frequency change can violate data delivery SLAs. A new field can break downstream joins. When those changes are communicated casually, or not at all, failure becomes inevitable.
Most pipeline incidents don’t come from bugs. They come from uncoordinated changes. The dangerous part is that nothing enforces discipline by default. Engineers are incentivized to move fast. Product teams push for coverage. Nobody owns the system-wide impact unless something goes visibly wrong.
Strong web data infrastructure treats change as an event, not an action. Changes are logged. Reviewed. Versioned. Rollbacks are planned before deployment, not after. Consumers know what’s changing and when. Without that, pipelines become unpredictable. Not because the web is unstable, but because the organization is.
Experiencing These Scaling Bottlenecks?
Get clean, structured, compliance-ready web data on the cadence you need, with nothing to maintain.
Next, we’ll get into a failure mode that looks technical on the surface but is really about expectations: data delivery SLAs that were never realistic in the first place.
Challenge 6: Data Delivery SLAs and Web Volatility
This is where expectations and reality collide. Enterprise stakeholders often frame web data pipelines the same way they frame internal services. Fixed delivery windows. Consistent volumes. Predictable latency. Clean handoffs. SLAs get written as if the upstream is controlled.
But the upstream is the web. Sites throttle without warning. Layouts change mid-day. Regions behave differently. Content gets cached, personalized, or partially served. None of this violates an API contract because there is no contract. Yet SLAs are still written as if one exists.
This creates chronic tension. Engineering teams spend time defending why an SLA was missed instead of improving the system. Consumers lose trust because expectations were set incorrectly. And leadership assumes the problem is execution, not mismatch. At scale, web data SLAs must be probabilistic, not absolute.
That doesn’t mean “unreliable.” It means explicitly defining acceptable ranges. Freshness windows instead of timestamps. Coverage thresholds instead of completeness guarantees. Degradation rules instead of binary success. Teams that scale successfully make SLAs reflect how the web actually behaves. They document assumptions. They define fallback behavior. And they renegotiate when sources evolve. If your SLAs pretend the web is stable, your pipeline will always look broken.
Next, we’ll move into a challenge that creeps in as volume grows: monitoring pipelines for correctness, not just uptime.
Challenge 7: Monitoring Data Pipelines for Correctness, Not Just Uptime
Most enterprise web data pipelines are monitored. Very few are observed. Jobs have dashboards. Schedulers report success. Alerts fire when something crashes. From an operational point of view, everything looks healthy.
Until someone asks a simple question: “Why does this number look wrong?” This is one of the most expensive web data pipeline challenges at scale. Uptime tells you whether the pipeline ran. It tells you nothing about whether the data still represents reality.
At enterprise scale, correctness degrades gradually. A field becomes sparse. A category overrepresents one source. A timestamp stops updating even though records keep flowing. None of these trip traditional alerts. By the time a human notices, the damage is already downstream. This is why monitoring has to move beyond infrastructure metrics. Pipelines need to observe the data itself. Field fill rates. Distribution shifts. Duplicate growth. Freshness by segment, not just globally.
Teams that scale well define “normal” behavior for their data and watch for deviations. Not because they expect perfection, but because they want early signals. If your monitoring can’t tell the difference between “job succeeded” and “data is trustworthy,” you don’t really know what your pipeline is doing.
Across large-scale enterprise pipelines we’ve audited, over 65% of production incidents were detected by downstream teams, not monitoring systems. Uptime dashboards reported success while data correctness had already degraded.
Next, we’ll look at what happens when legal and compliance requirements hit pipelines that were never built for traceability.
Challenge 8: Compliance and Traceability in Enterprise Data Pipelines
This is usually where enterprise web data pipelines slow down dramatically. Early pipelines collect data first and ask questions later. That works until legal, security, or procurement gets involved. Then the questions change. Where did this data come from? Are we allowed to collect it in this region? What user consent applied at the time of capture? Can we prove that?
Most pipelines can’t answer those questions cleanly. They know how they scraped something, but not why, under what conditions, or with what permissions. Source URLs exist, but lineage is incomplete. Consent signals aren’t stored. Regional rules are applied inconsistently, if at all. At enterprise scale, this becomes a blocker, not a risk.
Compliance teams don’t want assurances. They want evidence. And pipelines that weren’t designed to preserve context struggle to retrofit it. Every request for explanation turns into a manual investigation. Every audit feels like a fire drill. This is also where global scale complicates things further. Rules differ by geography. What’s acceptable in one market may not be in another. Pipelines that treat the web as uniform quickly fall out of alignment.
The fix isn’t more documentation. It’s structural traceability. Pipelines need to carry intent, source, and constraints alongside the data itself. Without that, scaling just amplifies legal exposure.
Next, we’ll look at a problem that sounds purely technical but is actually about incentives: hidden operational debt that accumulates as pipelines grow.
Challenge 9: Operational Debt in Scaling Web Data Infrastructure
This is what happens when ownership and change of discipline remain unresolved.
This is the challenge nobody plans for, because it doesn’t announce itself. Operational debt builds when pipelines grow by addition instead of design. One more source. One more exception. One more special case. Each decision makes sense in isolation. Together, they create a system that only works because a few people know where the bodies are buried.
At enterprise scale, that knowledge becomes a liability. Retries exist, but no one remembers why the thresholds were chosen. Custom parsers live outside the main code path. Certain sources require “gentle handling, which is never documented. When something breaks, the fix depends on tribal memory, not system behavior.
This is why scaling web data pipelines often feels slower over time, not faster. Every change takes longer because it risks triggering unknown side effects. Teams become cautious. Innovation slows. And ironically, reliability suffers because the system is too complex to reason about confidently.
Operational debt is different from technical debt. It’s not just messy code. It’s undocumented assumptions, invisible dependencies, and manual interventions that quietly become permanent. Enterprise-ready pipelines actively fight this. They remove special cases instead of accumulating them. They codify behavior instead of relying on memory. And they treat every workaround as a temporary failure, not a feature. If scaling your pipeline makes your team afraid to touch it, the system has already crossed a dangerous threshold.
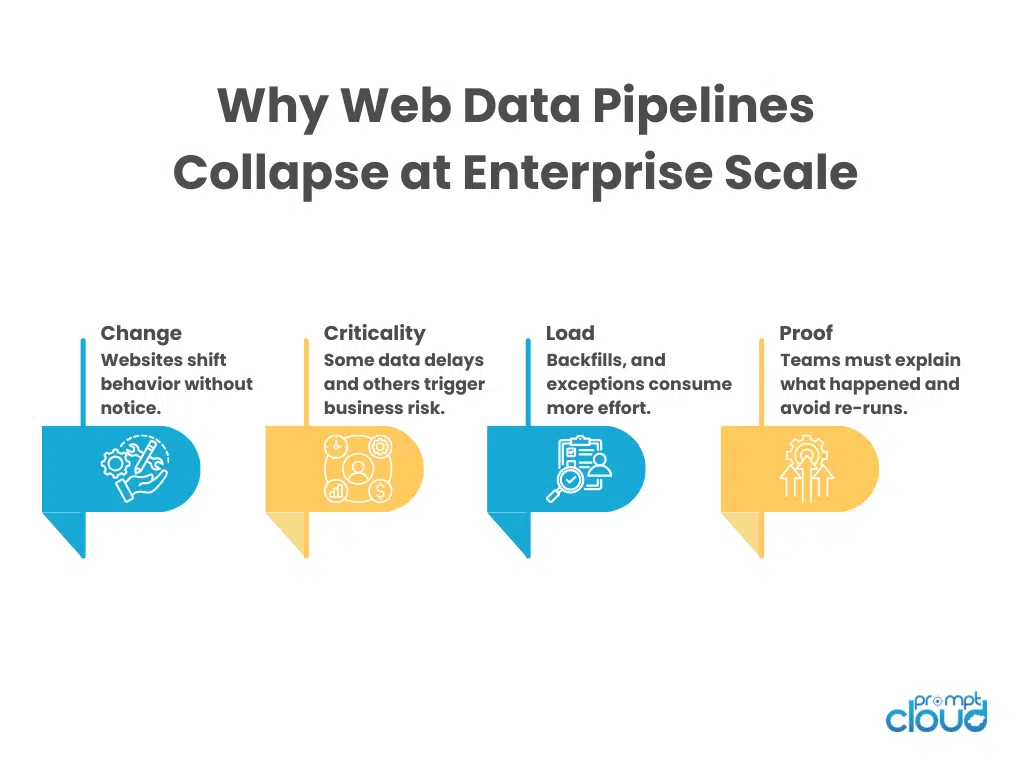
Figure 2: The operational realities enterprise web data pipelines must absorb once they support SLAs and decision systems.
Next, we’ll close with a challenge that sits above all the others: web data infrastructure that outgrows its original purpose without being rethought.
Challenge 10: Redesigning Web Data Infrastructure for Enterprise Reality
This is the quiet, structural failure behind most others. Many enterprise web data pipelines are still running on foundations designed for a very different job. They started as a research tool. Competitive analysis. One-off reporting. Something flexible, fast, and good enough.
Then the use cases changed. The architecture didn’t. Data moved from dashboards into production systems. From analysts to automation. From internal teams to customers. But the pipeline still assumes manual oversight, informal coordination, and forgiving consumers.
At that point, every other challenge compounds.
Reliability gaps hurt more. Freshness issues escalate faster. Schema drift becomes political. Compliance becomes blocking. Monitoring becomes reactive. Operational debt turns toxic. This is where enterprises hit a wall. You can keep patching. Add alerts. Add retries. Add process. Or you can acknowledge the real issue: the system was never designed to be infrastructure. It was designed to be a tool.
Enterprise-scale web data requires a different mindset. One where change is expected. Where failure is isolated. Where data carries context, not just content. And where ownership and accountability are as explicit as the code itself. If you don’t make that shift, scaling will keep feeling like firefighting, no matter how much capacity you add.
| # | Challenge | What breaks at enterprise scale | Early warning signal |
| 1 | Reliability was assumed, not designed | Partial failures leak downstream, retries spiral, “green runs” still miss coverage | Success rate stable, but record counts fluctuate |
| 2 | Data freshness becomes an SLA | Data arrives “on time” but is stale, segments lag, SLA breaches become constant | Record age drifts upward while jobs still succeed |
| 3 | Schema drift breaks trust silently | Fields keep flowing, but meanings, enums, and nesting change | New values appear, null spikes, type stays “valid” |
| 4 | No clear ownership for pipeline reliability | Incidents bounce between teams, MTTR explodes | Alerts acknowledged but not resolved end-to-end |
| 5 | Change management stayed informal | Unreviewed changes create cross-team outages and regressions | “Small” tweaks correlate with downstream anomalies |
| 6 | SLAs assume the web behaves like an API | Absolute commitments become impossible, constant exception handling | Misses cluster around specific sites/regions/time windows |
| 7 | Monitoring tracks uptime, not correctness | Data degrades while dashboards stay green | Distribution shifts, fill-rate drop, duplicate growth |
| 8 | Compliance demands traceability; you don’t have | Audits turn into fire drills, and delivery slows under reviews | Missing provenance fields, unclear collection conditions |
| 9 | Operational debt compounds faster than throughput | System becomes unchangeable, tribal knowledge becomes a dependency | Fixes require specific people, undocumented “special cases.” |
| 10 | Infrastructure was never redesigned for enterprise reality | Every new source increases fragility, and scaling feels like firefighting | Release fear, rising incident frequency, brittle dependencies |
Explore more
If you’re dealing with these challenges in real systems, these pieces go deeper into the specific pressure points enterprises usually hit next:
- How global data laws quietly reshape web data pipelines – Why scaling across regions forces legal logic, provenance, and controls into pipeline design, not just policy docs: Web scraping and global data laws explained
- What GDPR compliance actually breaks in enterprise data workflows – Where pipelines fail when consent, purpose limitation, and retention were never encoded into the system: GDPR compliance for web data pipelines
- Why robots.txt is not enough at enterprise scale – How relying on access rules alone creates false confidence and downstream compliance risk: robots.txt and scraping compliance guide
- How consent awareness changes data ingestion at scale – What breaks when pipelines can’t track user consent signals alongside collected data: Automating user consent in scraping systems
Martin Fowler’s breakdown explains how operational complexity and unclear ownership, not tooling, cause most enterprise pipeline failures.
What This Means in Practice
Scaling web data pipelines is not about increasing throughput. It is about upgrading assumptions.
- Reliability must be designed, not observed.
- Freshness must be defined, not implied.
- Schemas must be versioned, not assumed stable.
- Ownership must be explicit, not cultural.
- Monitoring must measure trust, not uptime.
Most enterprise pipeline failures are not caused by scraping difficulty. They are caused by infrastructure that never evolved beyond experimentation. When data becomes contractual, architecture must follow.
What separates resilient data teams is infrastructure maturity. They treat web data pipelines as governed systems, not experimental workflows. This is why enterprise Data-as-a-Service for web data requires built-in monitoring, structured delivery, and contractual SLAs. Organizations reaching this stage often evaluate whether continuing internal scaling efforts supports enterprise-grade reliability and compliance demands.
FAQs
Why do web data pipelines fail when they move to enterprise scale?
Because they were designed for experimentation, not guarantees. Assumptions around freshness, ownership, and change control break once data becomes business-critical.
Is pipeline reliability mainly an infrastructure problem?
No. Most failures come from unclear ownership, weak change management, and missing contracts, not from compute or tooling limits.
Why is schema drift so dangerous in enterprise pipelines?
Because it rarely causes hard failures. Meaning changes silently propagate and erode trust long before anyone notices.
Can enterprises realistically enforce SLAs on web data pipelines?
Yes, but only as ranges and thresholds. Guarantees assume the web behaves like an API, which it does not.
What’s the hardest thing to retrofit into an existing pipeline?
Traceability. If lineage, consent context, and intent were not captured early, adding them later is slow and disruptive.
Turn Web Data Pipelines into Defensible Infrastructure
Get clean, structured, compliance-ready web data on the cadence you need, with nothing to maintain.















