



Having ready access to relevant data is becoming more and more crucial with the increasing need for data-backed decision-making in today’s business scene. While there is a wide variety of options when it comes to web data extraction, most of them are either too much work for the user or give little to no control.
With CrawlBoard, our aim was to strike a perfect balance between a fully managed service and a customizable tool that can be used for controlling all aspects of a web crawling project. We’re happy how things turned out and CrawlBoard indeed has the goodness of both. While all the technically complex aspects of web data extraction is taken care of by our skilled engineers in the backend, you as a user can add new sites, check for feasibility and get a bird’s eye view of the whole flow including data uploads and more using CrawlBoard.
We’ve been working on giving more power to you via CrawlBoard and have implemented some new features aimed at just that. Here’s a quick look at the newest feature additions on CrawlBoard.
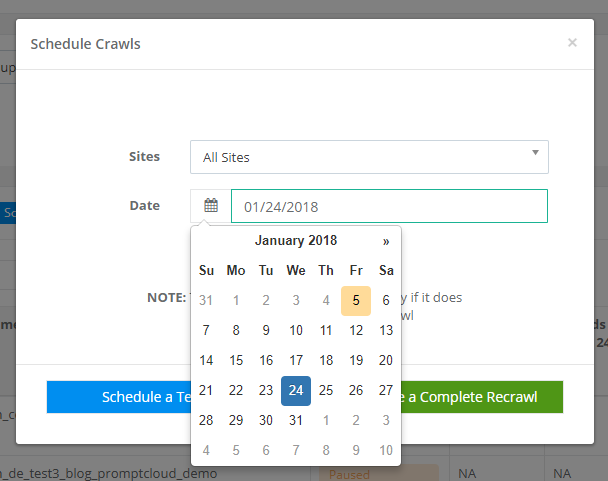
Schedule crawls anytime
The frequency of crawls is something that our users would define during the initial crawler setup phase. While the regular crawls will continue to run according to this frequency, there might be instances where you require a random crawl to be done. With the new “schedule crawls” feature, users can initiate crawls at any time as per the requirement. This will come really handy if you want the data delivery to be expedited. The crawl scheduling can be done for a select set of sites or all sites as per your needs.
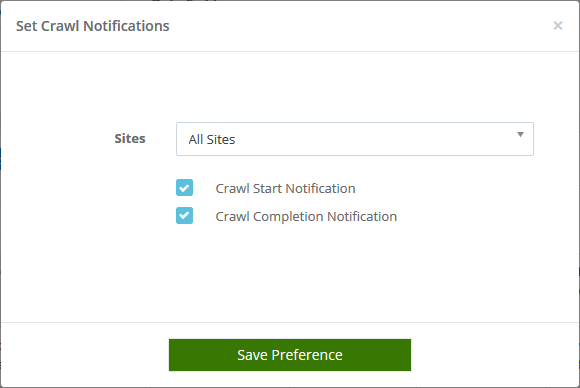
Crawl notifications
So you have a crawl project running and would like to receive updates as and when the crawl starts or stops. This can be done by selecting the sites for which you would like the crawl notifications to be sent and choosing start/stop notifications using the radio button. Crawl notifications can help you stay updated to the crawl timings and prepare your internal data systems for the incoming data beforehand. To enable, go to the Sites option on the left pane, select the desired sites and click on Set Crawl Notifications from the bulk actions menu.
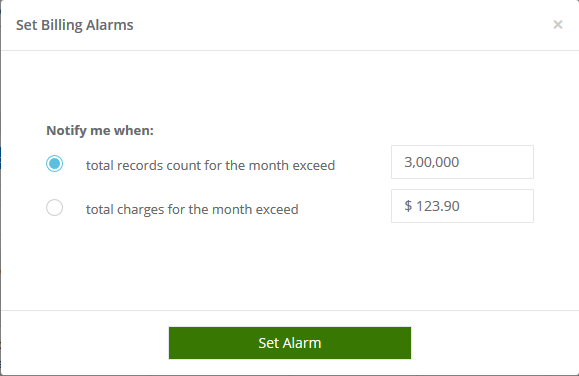
Billing alarms for more control
There can be instances when your internal data storage systems are inadequate for the amount of data being extracted. Another scenario is when the billing amount goes above your budget for data acquisition. Since it’s not possible to predict the exact data volumes you will be receiving, we implemented billing alarms which can be set up to alert you when the data volume or billing amount goes above a set threshold. With this in place, you can have more control over the project and take swift actions.
With the increasing complexities associated with big data and its implementation, we hope these nifty features that we’ve added to our requirement gathering tool will help ease your data acquisition process and help you become more productive while the project is fully automated. We’re excited for you to try them out and hope to get feedback and suggestions.
















