




**TL;DR**
Web scraping isn’t new. It’s everywhere now, from tracking competitors to analyzing markets. But there’s one thing too many teams brush past: security. Or worse, compliance.
Think about it. You’re pulling data from sources you don’t own. Maybe even personal data. If that data leaks? If what you pulled wasn’t meant to be collected, it’s not just a technical oversight; it could be the start of a legal headache or the beginning of a bigger credibility problem.
Laws like GDPR and CCPA aren’t vague anymore. Regulators are watching. And customers? They’re paying attention to how their data is handled. No one wants their name or behavior scraped without permission.
The smart move? Treat scraping like you’d treat any other data pipeline. With guardrails. With ethics. With care. The best web scraping companies today don’t just pull data fast. They do it right. That’s what this piece is about.
The Cost of Overlooking Data Security in Web Scraping
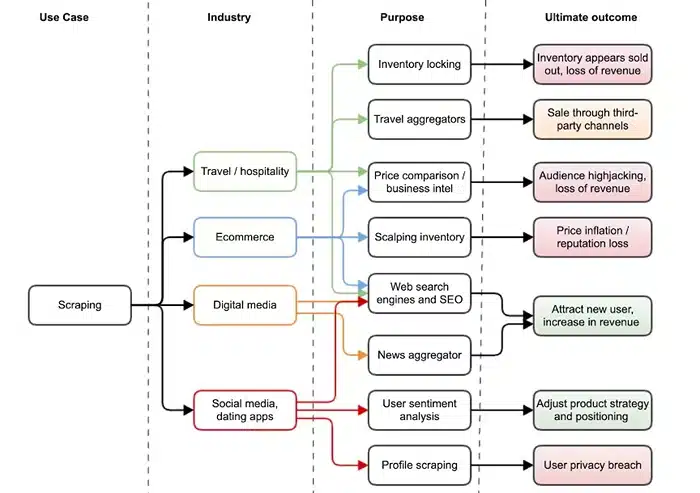
A few years ago, a mid-sized retail company set out to gather pricing data from hundreds of e-commerce sites. The goal was simple: stay competitive. They hired a small scraping vendor. Everything worked—until it didn’t. One day, a partner website flagged them for accessing personal identifiers tucked inside URLs. Things went south fast. What started out as a smart move to gather pricing intel ended up triggering a formal complaint, and before long, legal was in the room, and everything turned into a compliance headache.
This isn’t rare.
Web scraping’s kind of turned into a default move for teams trying to keep up. Want to know what your competitors are charging? Who are they hiring? What are people saying in reviews? Scraping lets you gather all of that without doing it manually.
But there’s a catch—a big one. As the volume and sensitivity of scraped data increases, so do the risks. Data security and compliance aren’t just “nice to have” anymore. They’re essential. The landscape has changed. Governments are writing tighter data laws. Users are demanding transparency. And regulators? They’re enforcing.
If you’re not careful about what you collect—or how you store and protect it—you’re gambling with your business. And let’s be honest: most scraping conversations skip over this. It’s all speed and scale, very little about risk.
That’s why we’re writing this. At PromptCloud, we’ve seen both sides of the story—the innovation scraping enables, and the damage it can do when ethics and safeguards are ignored. Our goal here isn’t to scare you. It’s to level with you. To explain why data security needs to be baked into your scraping strategy from the start, and why working with vendors who take compliance seriously can save you a lot more than just money.
Let’s dig into what security looks like in web scraping and why doing it the right way is one of the smartest business decisions you can make.
Data Security in Web Scraping Isn’t Optional Anymore
When people say “data security,” they often think of locked servers or fancy tools. But in web scraping, it’s more about the entire flow—how you grab the data, where it travels, who can see it, and how you’re keeping it safe at every step.
And here’s the kicker: scraping often feels harmless—after all, you’re pulling public data, right? But public doesn’t always mean safe. Or legal. Or ethical.
Let’s say you’re scraping a product page. Seems clean. But that page might contain metadata you didn’t notice—like user IDs embedded in URLs, or comment threads with personally identifiable information (PII). If your scraper grabs that without filtering it out or encrypting the logs, you’re now holding sensitive data—maybe without realizing it.
Now, imagine your database gets breached. Or a partner tool you use to process the data isn’t secure. Suddenly, you’re not just dealing with a technical hiccup. You’re dealing with exposure, possibly a data leak, and definitely some tough questions from legal.
IBM’s 2023 Cost of a Data Breach Report puts the average breach at $4.45 million. That’s not just a number; it’s a financial gut punch. And many of those breaches start with weak access controls or unencrypted pipelines—issues that can absolutely apply to scraping workflows if you’re not paying attention.
So, what does “secure scraping” really look like?
It means making sure the entire pipeline—from the moment your script hits a URL to the moment that data gets stored—is locked down. That includes encrypted data transfers, role-based access controls, tokenized logging, audit trails, secure cloud environments, and regular reviews.
At PromptCloud, for example, we use end-to-end encryption for all scraped data in transit and at rest. Only approved personnel can access raw datasets. Our clients know exactly what’s being collected, how it’s being stored, and who’s touching it, because that’s what trust looks like in 2025.
If you’re working with a scraping vendor and they can’t walk you through their security protocol in plain language, that’s a red flag. If they say “don’t worry about it,” worry about it.
Because at the end of the day, data security in web scraping isn’t just about protecting what you collect. It’s about protecting your business, your customers, and your future.
What Is Data Compliance? Let’s Talk About the Rules Everyone’s Dodging
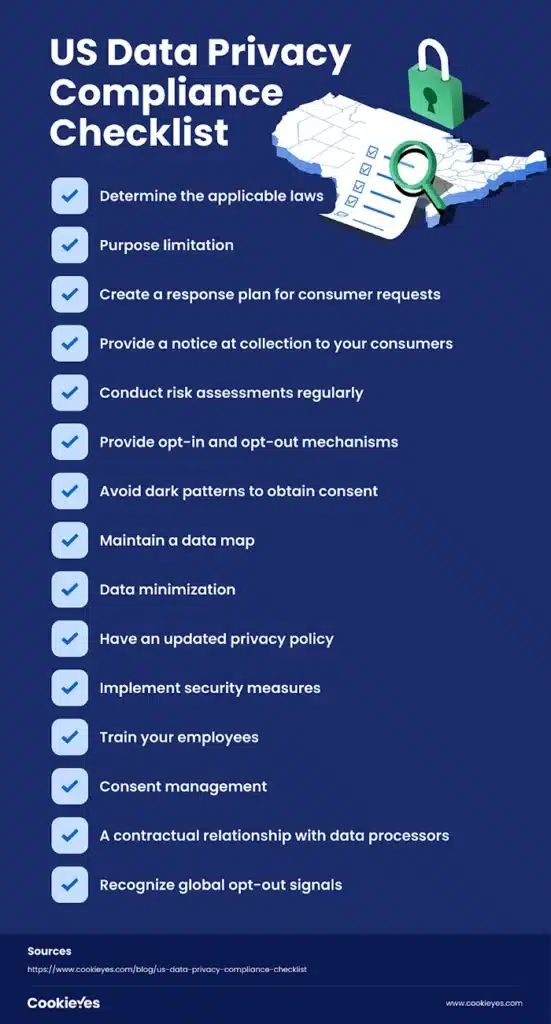
Image Source: Cookieyes
“Wait—aren’t we just scraping public data?” That’s how the conversation usually starts.
You’ve got the tech team trying to move fast, the product team hungry for insights, and somewhere in the middle sits someone from legal or compliance, looking concerned.
“Sure, it’s public. But that doesn’t mean it’s fair game,” the compliance manager says, flipping through a printout of GDPR guidelines.
It gets quiet for a second. Because deep down, everyone knows the truth: most scraping setups don’t stop to check if the data being pulled is personal, sensitive, or even allowed to be collected.
“So what are we risking?” someone asks. A fair question. The short answer: a lot. The longer answer? Fines, investigations, takedown notices, and even bans from sites or platforms. The worst part? You often don’t find out until after the fact.
GDPR, for instance, doesn’t care if you meant to collect personal data or not. If you touch anything that could identify a European user—an email, a location, a user ID—you’re on the hook. And unless you’ve got legal grounds (like consent or a legitimate interest that can be proven), you’re exposed. CCPA is similar, but now with the CPRA in play, the rules are even tighter around profiling and automated decisions.
“Okay, but what if we just avoid collecting personal info?” Easier said than done. When you’re scraping at scale, those little identifiers sneak in. URLs, metadata, comments—it adds up. And if no one is filtering or anonymizing the data before it hits your database, you’re collecting more than you think.
This is where smart companies pause. They ask the right questions before launching a scraping project. Not after a warning letter arrives.
At PromptCloud, we’ve seen this shift firsthand. More clients come to us with one condition: “Keep us compliant.” That means we audit targets, apply filters, hash or exclude personal identifiers, and log every access request. We’ve turned down scraping projects that didn’t feel right. And yes, we’ve lost deals over it. But we’ve never put a client at legal risk for the sake of speed. That’s not what long-term partners do.
“So, compliance isn’t about slowing down?” No. It’s about staying in the game. If you’re scraping data without understanding the rules, you’re building on shaky ground. And the people watching—regulators, platforms, even consumers—they’re not looking the other way anymore.
Ethical Web Scraping Isn’t a Toolset, It’s a Mindset
You can write the cleanest crawler code imaginable and still cross a line. And not just a legal one—a line of trust, intent, or common sense. That’s what makes ethical web scraping more than just a technical discipline. It’s a judgment call. A mindset.

It Starts With One Question: Should We Be Collecting This?
The most overlooked part of scraping isn’t scale. It’s consent. Teams often ask if they can get the data, not whether they should. That’s where things get murky.
There’s a difference between collecting what’s technically accessible and what’s meant to be shared. A product page? Likely fair use. But user-generated content with names, emails, or private discussions? That crosses into risky territory fast.
Not All “Public” Data Is Public in Spirit
This trips up a lot of well-meaning teams. Visibility isn’t the same as permission. A lot of what you see online was shared with a certain audience in mind, even if anyone can technically access it. Think forums, comment threads, social media bios—places where people speak casually, not realizing a bot might be copying their words.
Ethical scraping is about knowing when to stop and ask yourself, “Should we really take this?” Not out of fear, but out of respect for where the data came from—and who it affects.
Ignore Site Boundaries, Invite Trouble
Websites often use things like robots.txt files, rate limits, or scraping-specific clauses in their terms of service to signal boundaries. If your scraper ignores those? That’s not just poor form—it’s potential legal exposure.
Some large platforms have taken scrapers to court over this. And even when the legal dust settles, the PR damage lingers. No client or investor wants to hear that your data came from a source that doesn’t want you there.
Ethics Go Beyond What the Law Requires
Here’s the truth: compliance isn’t always enough. Laws tend to lag behind technology. They’re broad by design. But good scraping practices should go further.
We’re talking about filtering out personally identifiable information (PII), even if you’re not explicitly required to. Respecting data retention limits. Being upfront with clients about where the data came from. Saying no when a request crosses the line—even if it’s profitable.
At PromptCloud, We Build Guardrails In
This isn’t theory for us. We’ve said no to projects that raised red flags. We’ve asked clients to revise targets. We’ve walked away from short-term gains because they didn’t align with long-term trust.
Why? Because we’ve seen what happens when companies chase data recklessly. It never ends well. And our reputation is worth more than a quick scrape.
Ethical Scraping Is Responsible Scraping
People often frame this as an “extra step,” but it’s just the right one. Data isn’t just digital output—it’s often tied to real lives, businesses, or communities. Treat it that way.
If you’re building a scraping pipeline today, build ethics into the process, not after something goes wrong, but from the start. It’s slower, maybe. But better. Safer. And sustainable.
Real Risks: Legal, Financial, and Brand Repercussions of Careless Scraping
Web scraping might feel like a behind-the-scenes operation—something quiet, technical, and invisible to the outside world. But when it goes wrong, the fallout is loud. And expensive.
Let’s talk about what actually happens when data security and compliance aren’t taken seriously.
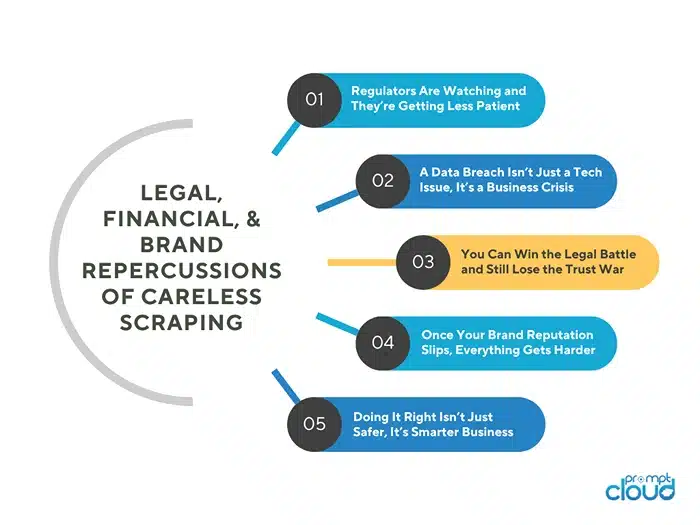
Regulators Are Watching and They’re Getting Less Patient
It used to be that regulators would issue a warning. Maybe a slap on the wrist. That’s changed. GDPR, CCPA, and other data laws now come with teeth. Big ones.
If you’re caught collecting personal data without consent, you could face fines in the millions. Under GDPR, it can go as high as €20 million or 4% of global revenue—whichever is higher. And that’s not just theoretical. Meta, Amazon, and several large data firms have already paid the price.
Even smaller companies are seeing trouble. Startups, mid-market firms, even internal teams at large enterprises—if your scraping touches regulated data, you’re in scope.
A Data Breach Isn’t Just a Tech Issue, It’s a Business Crisis
Here’s a scenario: you’ve scraped thousands of pages, stored the data on a shared server, didn’t encrypt it, and a misconfigured bucket gets exposed. Suddenly, everything’s public—emails, user IDs, session tokens, maybe even internal notes.
IBM’s Cost of a Data Breach Report (2023) puts the average breach at $4.45 million. And that’s just direct costs—response, legal, and customer notifications. Add reputational damage, lost deals, and customer churn, and you start to feel the weight of not locking things down properly.
In scraping, this is more common than you think. The fast-moving nature of the work leads some teams to treat storage and access control as afterthoughts. But all it takes is one unsecured dataset to trigger months of chaos.
You Can Win the Legal Battle and Still Lose the Trust War
Let’s say you scrape within legal boundaries. No violations, no lawsuits. But your customers or partners find out you collected data from questionable sources, or that you scraped content from a site with clear do-not-scrape language.
That can be just as damaging. In today’s climate, trust is currency. And being known as the company that takes shortcuts with data? That’s a stain that doesn’t wash out easily.
The blowback doesn’t always come from regulators. Sometimes it’s a customer walking away quietly. Or a journalist asking questions. Or a competitor using it against you in a pitch.
Once Your Brand Reputation Slips, Everything Gets Harder
It’s easy to underestimate the long-term impact of a misstep. Maybe the fine was manageable. Maybe the legal settlement was private. But your company’s name is now associated with “scraping controversy.”
Good luck hiring top talent after that. Or convincing a cautious enterprise client that you take data security seriously. Or getting approval from internal legal teams for a partnership. These ripple effects linger for years.
And they don’t show up on a balance sheet until they do.
Doing It Right Isn’t Just Safer. It’s Smarter Business
When you treat web scraping compliance and security as core infrastructure—not a patch—you don’t just reduce risk. You gain leverage.
You can work with regulated industries. You can build trust with clients who care about ethical sourcing. You can scale confidently, knowing your systems won’t collapse under scrutiny.
That’s why we’ve built PromptCloud to operate on a foundation of security, transparency, and long-term thinking. Not because we’re risk-averse, but because we’ve seen what happens when others ignore the basics.
Choosing the Best Web Scraping Companies for Secure & Compliant Data Extraction
Not all scraping vendors are built the same. Some will promise the moon—unlimited scale, lightning-fast delivery, no questions asked. But if you’re serious about doing things right, those shouldn’t be the promises that win you over.
Here’s the truth: the best web scraping companies aren’t just fast. They’re careful. They know how to scale and stay in bounds. They make compliance and security part of the process, not a disclaimer at the end.
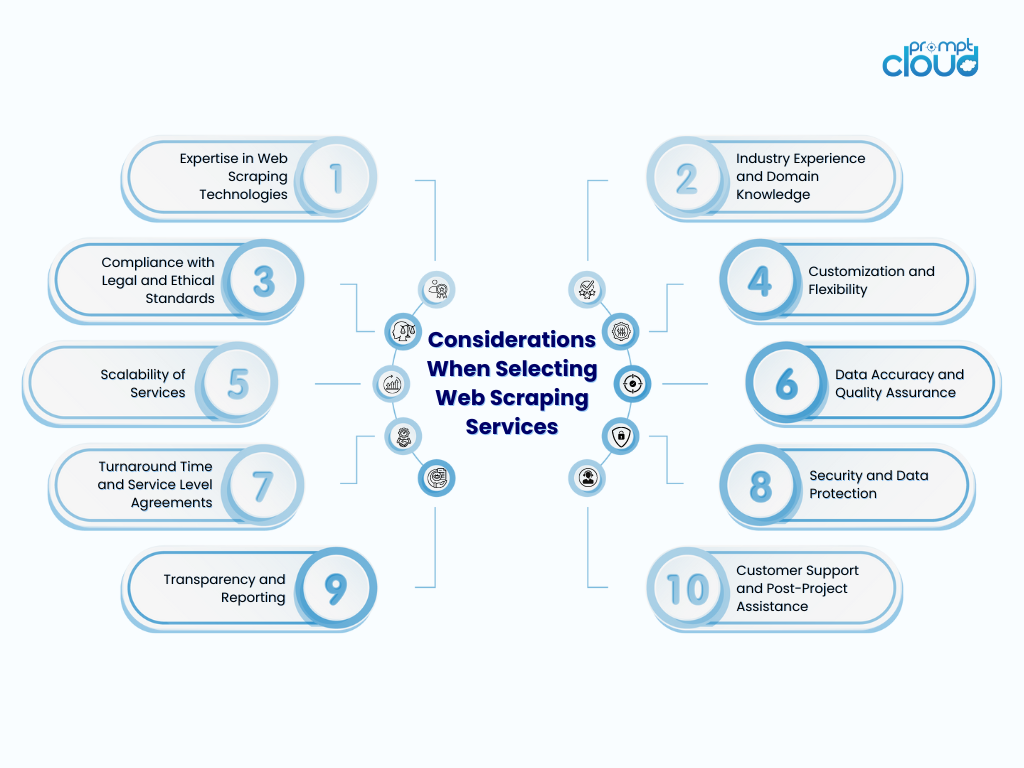
Start by Looking at How They Talk About Compliance
Ask any vendor how they handle data protection. If they get vague, pivot to speed, or say “we haven’t had any issues yet,” that’s a red flag.
A strong vendor should be able to walk you through their compliance workflow. That includes how they review target sites, whether they honor terms of service, what filtering mechanisms they use to avoid collecting personal data, and how they handle data requests from clients in regulated industries.
The good ones won’t just follow compliance, they’ll help you understand it.
Security Shouldn’t Be an Add-On, It Should Be Baked In
How is data transferred? Is it encrypted in transit and at rest? Are access logs maintained? Are environments isolated? Are internal staff subject to access control policies?
You don’t need a security degree to ask these questions. You just need a vendor who can answer them clearly.
At PromptCloud, we take compliance seriously, not because clients ask, but because we assume every dataset we handle is sensitive, even if it’s not labeled that way.
Ask for More Than a Demo, Ask for Their Decision-Making Process
A slick demo tells you how well their tech works. But what you really want to know is how they make decisions when things get tricky.
- What happens if a target site changes its terms?
- Will they scrape a site that has a robots.txt block?
- Do they pause to review edge cases or rush delivery?
At PromptCloud, we’ve built internal checkpoints where compliance, legal, and data teams come together to review gray areas. This doesn’t slow things down—it prevents rework, disputes, and long-term risks.
Transparency Shouldn’t Be a Feature, It Should Be the Standard
You should never have to guess where your data came from or whether it was ethically collected. The best vendors will give you a full trail—what was scraped, when, from where, under what conditions, and with what restrictions.
We provide our clients with:
- Site source lists
- Scrape frequency reports
- Data lineage summaries
- Alerts when the terms of service change
That’s not overkill, it’s clarity. And in this space, clarity is a competitive advantage.
When in Doubt, Ask Them What They’ve Said No To
Here’s a test: ask your potential vendor to share an example of a scrape request they turned down.
If they say “none,” be careful.
The best web scraping companies will have lines they won’t cross. Whether it’s sites that explicitly ban automation or data that veers into personal territory, saying no is a sign of discipline, not weakness.
We’ve turned down projects that looked exciting on paper but failed the ethics test. And we’re proud of that. It means our clients sleep better, and so do we.
The Business Advantage of Scraping Right
Here’s something most people don’t realize until they’ve been burned: cutting corners on compliance or data security doesn’t just carry risk, it costs opportunity.
Doing it right from the start may take a little more effort, a few more questions, and a little more time. But what you gain in return is something far more valuable than just speed.
You Earn Long-Term Trust, Not Just Short-Term Wins
Clients, partners, investors, they all want to know you’re building responsibly. That means data pipelines that are clean, secure, and compliant. Not just functional.
When you operate transparently and follow clear ethical boundaries, people remember. They refer you. They renew contracts. They invite you into bigger conversations.
At PromptCloud, we’ve seen firsthand how a responsible approach wins more than technical achievements ever could. Our longest client relationships are built on trust, not just performance.
You Unlock Access to Regulated Industries
Financial services, healthcare, insurance, education—these sectors all use data. But they’re also heavily regulated. If your scraping workflows aren’t airtight, you won’t even make it past their procurement gates.
On the other hand, when you can demonstrate that you follow data compliance standards, honor GDPR/CCPA restrictions, and have a clear audit trail, you become a rare kind of vendor: one they can say yes to.
That’s not just a compliance win—it’s a business growth engine.
Security-First Thinking Reduces Downtime and Fire Drills
Teams that ignore security tend to spend more time cleaning up messes—renegotiating after complaints, patching exposed servers, responding to PR issues, and updating contracts in a panic.
Teams that prioritize data security avoid most of those surprises altogether.
At PromptCloud, we’ve spent years building in security at every level—from access permissions to infrastructure design—so that when our clients scale, they don’t also scale risk. That’s saved everyone time, money, and a few sleepless nights.
You Build a Reputation That Attracts the Right Clients
There’s a difference between being known as “the fastest scraper” and being trusted as “the one who gets it right.”
If you’re trying to serve enterprises, multinational clients, or even tech-forward startups who care about reputation, compliance isn’t a friction point—it’s a selling point.
In a world that’s watching how data gets handled, being a company that plays by the rules doesn’t make you boring. It makes you valuable.
Responsible Scraping Isn’t Just Safer, It’s Smarter
Some see compliance as a constraint. We see it as a strategy.
It pushes you to think critically about your processes, automate responsibly, and build scrapers that don’t just survive—but last. It forces you to choose quality over shortcuts. And in this landscape, that’s how you win.
Because the fastest scraper isn’t always the most successful.
The one that stays trusted? That’s the scraper that wins in the long run.
Ethical and Responsible Scraping Is the Future
Web scraping has become an essential tool for modern businesses. From tracking prices to analyzing sentiment, it helps organizations move quickly and make smarter decisions. But that speed means very little if it comes at the cost of security, compliance, or ethics.
At its core, scraping is about trust. You’re collecting information that someone else made available—sometimes deliberately, sometimes not. And that comes with responsibility. When companies ignore the legal or ethical boundaries around data, they don’t just risk fines or lawsuits. They risk their credibility. Their client relationships. Their future.
We’ve reached a point where “getting the data” isn’t the hard part anymore. The real challenge is collecting it in a way that respects privacy, protects users, and stands up to scrutiny. That’s what separates short-term scrapers from companies built for the long run.
If you’re serious about web scraping as a strategy—not just a tactic—you need to treat data security and compliance as non-negotiables. It’s not about checking boxes or playing it safe. It’s about building something that lasts.
At PromptCloud, we believe that responsible scraping is the only kind that should exist. We’ve built our systems, our processes, and our client relationships on that principle. And we’re convinced that in the years to come, the businesses that do this the right way will be the ones that lead.
Because the future of data-driven growth doesn’t belong to the fastest—it belongs to the most trustworthy. Schedule a demo today!
FAQs:
1. Is it legal to scrape data from public websites?
Depends on who you ask and what you’re collecting. Some websites are okay with it. Others spell out in their terms that they don’t allow it at all. Most people think, “Hey, it’s online, so I can use it.” But that’s not always true. And if there’s user data involved, it gets messy fast. Honestly, it’s less about the act of scraping and more about what you’re doing with the data and whether anyone could be harmed by it. You’ve got to use judgment.
2. What counts as personal data when scraping websites?
It’s not just the obvious stuff. Sure—emails, names, phone numbers, that’s clear. But even something like a username, or a comment someone made on a forum, or data tied to a user session… that can count too. And the thing is, the line’s blurry. Something might not look personal at first glance, but when paired with other info? Suddenly it is. If it can be linked back to a person, even indirectly, it’s better to just treat it like personal data.
3. How do the best web scraping companies handle data compliance?
They don’t wing it. The good ones have a system—they double-check what’s being scraped, how it’s stored, and what risks come with it. If something doesn’t feel right, they push back. They ask more questions. Sometimes they even walk away from a job. It’s not about being paranoid—it’s just experience. You learn quickly in this space that it’s easier to say no up front than to explain yourself to a lawyer later.
4. What are the consequences of ignoring data security in scraping projects?
Best-case scenario? Nothing happens—until it does. And when it does, it’s usually all at once. A leak, a misstep, a partner raises a red flag, or someone finds out you stored something you shouldn’t have. Then you’re looking at clean-up mode. It could be internal chaos, could be external. Legal notices, loss of client trust, maybe even public fallout. These things rarely go quietly. It’s better to treat your scraping pipelines like real infrastructure and lock them down.
5. What should I look for in a secure and ethical web scraping partner?
Someone who tells you “no” once in a while. If a vendor always says yes—no matter what site, what data, or what you ask for—something’s off. You want a team that’s cautious. One that filters data instead of hoarding it. One that can show you exactly how and where they’re collecting from, and who can tell you why that matters. Bonus points if they seem genuinely uncomfortable when ethics are pushed aside. That’s usually the one you can trust.















