



Quick Answer: Crawler vs Scraper vs API in 60 Seconds
If you only need the short version, here it is.
A crawler finds pages. It moves through a website, follows links, and builds a list of URLs.
A scraper extracts data from those pages. It pulls the fields you care about, like prices, product names, job titles, ratings, or reviews.
An API gives you structured data directly, if the source provides one and gives you access.
That is the technical difference. The practical difference is simpler:
- Use a crawler when you do not know where all the relevant pages are.
- Use a scraper when you know the pages and need specific data from them.
- Use an API when you want stable, structured access without dealing with page layouts.
Most real-world data systems do not pick just one. They combine all three. A crawler discovers pages, a scraper extracts the missing fields, and an API handles the clean structured data that is already available. That layered approach is the real answer in most production environments
Definition Table: Crawler, Scraper, and API Explained
Before getting into tradeoffs, it helps to separate these terms cleanly. They often get lumped together, but they do different jobs.
| Term | What It Does | Typical Output | Best Used When |
| Crawler | Discovers and navigates links across web pages | List of URLs or sitemaps | You need to find pages dynamically or map a domain |
| Scraper | Extracts data from specific pages or content | Raw or structured data, such as CSV or JSON | You know what to extract and where to get it from |
| API | Provides structured data from a service or platform | Clean JSON or XML responses | An official API exists for the data you need |
Think of it in pipeline terms.
A crawler is the scout. It finds the roads.
A scraper is the collector. It pulls useful information from each stop.
An API is the direct line. If the source exposes the data you need, you can bypass a lot of crawling and scraping complexity.
This is why treating these as interchangeable creates bad architecture decisions. They operate at different stages of the same data workflow
Web Crawler vs Web Scraper vs API: Key Differences
This is where the confusion usually starts.
At a high level, all three help you access web data. But they solve very different problems, and using the wrong one for the wrong job is exactly how teams end up with brittle pipelines, incomplete coverage, or avoidable engineering work.
Here is the cleanest way to compare them.
| Dimension | Web Crawler | Web Scraper | API |
| Primary role | Discover pages and URLs | Extract data from pages | Deliver structured data directly |
| Input | Seed URL or domain | Specific URL or known page structure | Authenticated request or endpoint call |
| Output | Page list or sitemap | Structured dataset | JSON or XML payload |
| Best for | Unknown site structures | Page-level data extraction | Official or real-time data access |
| Control over output | Low | High | Very high, but limited to exposed fields |
| Resilience to site changes | High | Medium to low | High, until the API changes or is deprecated |
| Typical maintenance burden | Medium | High | Low to medium |
The important point is not just what each tool does. It is what each one does poorly.
A crawler is good at discovery, but by itself it does not give you business-ready data.
A scraper is good at extraction, but it becomes fragile when the site layout changes.
An API is good at stability and structure, but it only gives you what the provider chooses to expose.
That is why serious systems stop treating this as a one-tool decision. They treat it as a design choice across layers:
- discovery
- extraction
- structured access
That shift matters. Teams do not usually fail because they picked a bad technology. They fail because they asked one method to do the work of all three
How AI and LLMs Changed the Rules in 2025-2026
The crawler-scraper-API model still holds. What changed is what happens after collection.
A few years ago, the job mostly ended once the data landed in a database or warehouse. In 2026, that is often just the middle of the workflow. The output now has to feed AI products, RAG systems, internal copilots, and training pipelines. That changes what “usable data” actually means.
Raw HTML is usually not enough anymore.
AI systems need cleaner structure, better formatting, and more consistent context. That is why newer stacks increasingly include AI-native extraction layers that convert messy web content into formats that LLM workflows can actually use, such as Markdown or chunked JSON. The refresh doc calls this out directly as a major architectural change in 2025-2026
Here is what changed in practical terms:
| Use Case | Old Approach | 2026 Approach |
| Building an AI training dataset | Crawler + scraper + manual cleanup | Crawler + AI-native extractor with Markdown output |
| Feeding a RAG system | Scraper + parser + chunker | Managed feed with LLM-ready chunked JSON |
| Enterprise price monitoring | Scraper + internal normalization | API + scraper + AI normalization layer |
| News sentiment tracking | Scraper + keyword filters + manual review | AI-native crawler with built-in entity extraction |
So the question is no longer just, “Should we use a crawler, scraper, or API?”
Now it is also, “Who handles the normalization layer?”
That matters because a pipeline can appear to work while still failing the downstream AI use case. The pages may be collected correctly, but if the output is inconsistent, noisy, or missing context, retrieval quality drops and model outputs degrade. That is where many teams fail quietly
Core Capabilities and Roles
Once the definitions are clear, the next step is to compare how each method behaves inside a real data pipeline.
This is where the differences start to matter operationally, not just conceptually.
| Capability | Crawler | Scraper | API |
| Primary Role | Discover URLs | Extract data from pages | Provide data directly |
| Input | Seed URL or domain | Specific URL or known page | Authenticated request |
| Output | Page list or sitemap | Structured dataset | JSON or XML payload |
| Best For | Unknown structures | Web content extraction | Official or real-time data |
| Speed | Medium to slow | Medium to fast | Fast, if well supported |
| Control over structure | Low | High | Very high |
| Resilience to change | High | Medium | High, until deprecated |
| Works with AI pipelines | With AI layer added | With normalization step | Natively structured |
On paper, that looks straightforward. In practice, each method optimizes for a different priority.
A crawler gives you coverage. It helps you find what exists.
A scraper gives you flexibility. It lets you pull exactly the fields you care about.
An API gives you stability. It is usually the cleanest option when it exposes the fields you need.
The tradeoff is that no single option gives you all three at once. API-only systems often miss fields. Scraper-only systems become maintenance-heavy. Crawler-only systems give you maps, not decision-ready data.
That is why the better question is not, “Which one is best?” It is, “Where does each one reduce risk in the pipeline?”
Indexing vs Extraction: What Is the Actual Difference?
This is one of the most common sources of confusion in web data projects.
Teams often use “crawling” and “scraping” as if they mean the same thing. They do not. They happen at different stages and solve different problems.
Indexing is about discovery.
You do not yet know:
- how many relevant pages exist
- where they live
- how the site is structured
So you use a crawler to follow links, traverse categories, and build a footprint of the site. The output is not business data. It is a list of pages.
Extraction starts after that.
Now you know which pages matter, so the job changes. You are no longer trying to map the site. You are trying to pull specific fields from the pages you have already found. That is what a scraper does. It turns product pages, job listings, reviews, or articles into structured records.
A simple mental model helps:
- Crawler = “Where is the data?”
- Scraper = “What is the data?”
- API = “Can I get it cleanly?”
Where teams go wrong is skipping that separation.
They try to scrape before they know the full URL universe, which leads to incomplete coverage. Or they crawl a site and assume that means they have extracted useful data, which they have not. Or they rely on an API and assume it covers the same fields visible in the interface, which is often false.
Once you separate indexing from extraction, architecture decisions get much easier. You stop treating the data project like a script and start treating it like a system
Constraints, Risks, and Compliance
This is where the clean definitions stop and the real-world friction begins.
Most teams can build a crawler, a scraper, or an API integration that works once. The harder problem is making it keep working when the website changes, the rate limits tighten, or legal and operational constraints start to matter.
That is why this section matters more than the definitions. This is where web data systems actually fail.
Schema Drift: The Hidden Tax on Every Scraper
Schema drift is one of the most underestimated costs in scraping.
It happens when a website changes its HTML structure just enough to break your extraction logic without throwing a visible error. A CSS class is renamed. A field moves into a different container. A product page gets a design refresh. Your job still runs, but the output is wrong or incomplete.
That is what makes schema drift dangerous. It fails quietly.
- Your pipeline runs.
- Your jobs complete.
- Your dashboard updates.
- But the data is wrong.
This is not a corner case. It is routine maintenance debt.
A team scraping dozens of competitor sites can expect recurring breakage every month. The refresh document estimates that a mid-sized ecommerce team scraping 50 competitor sites can see around 3 to 8 schema breaks per month, with each one taking 2 to 6 hours to diagnose and fix. That adds up to 10 to 30 hours of engineering time spent on maintenance instead of product work
The fix is not just “better selectors.” It is operational discipline:
- Set field-level null alerts
- Run daily ground-truth spot checks
- Store schema versions or hashes
- Prefer APIs for critical fast-changing fields when possible
- Move to a managed pipeline when maintenance becomes a recurring drag
Schema drift is not just a scraper issue. It is an operating model issue.
Rate Limiting and Traffic Controls
APIs usually make the limits explicit.
You know the request caps, the throttling rules, and often the retry behavior. That makes planning easier, even when the limits are restrictive.
Scrapers and crawlers are different. The limits are often implicit. Hit a site too hard, repeat the same request pattern too often, or ignore server behavior, and you can get throttled, blocked, or banned.
That difference matters. APIs tend to fail predictably. Scrapers fail unpredictably.
At scale, predictable failure is easier to design around. Unpredictable failure becomes an operational tax
robots.txt and Terms of Access
Every production-grade crawler should check robots.txt before it does anything else.
That is a baseline, not an optional courtesy.
It is also worth reviewing the site’s Terms of Service, because the practical risk is not just legal interpretation. It is continuity. Ignoring access rules increases the odds of IP bans, blocked traffic, and unstable data delivery.
The refresh doc correctly notes an important nuance: robots.txt is not the same thing as legal authorization, but ignoring it still increases risk significantly, and RFC 9309 formalizes how modern crawlers should interpret it
Scraping JavaScript-Heavy Sites
Modern sites often do not deliver the important data in the initial HTML response. They render it later with JavaScript. If you scrape the raw page source without rendering, you may get an empty shell instead of the actual content.
That changes the extraction problem.
To handle JavaScript-heavy sites, teams usually do one of three things:
- render the page with tools like Playwright or Puppeteer
- intercept backend network requests and capture the underlying API calls
- focus only on simpler static targets where possible
Each option comes with a tradeoff.
| Method | Effort | Reliability |
| API | Low | High |
| Scraper (static) | Medium | Medium |
| Scraper (JS-heavy) | High | Low to Medium |
That table captures the real tradeoff well: APIs reduce complexity, while scrapers increase flexibility. The more dynamic the site, the more expensive the scraping layer becomes to operate reliably
Data Freshness and Change Detection
Getting data once is easy. Keeping it current is where the real engineering work starts.
This is one of the most overlooked parts of any web data strategy. Teams spend a lot of time deciding how to collect data, then underestimate how quickly that data goes stale once the pipeline is live.
And that matters because freshness is not just a technical concern. It changes business value.
If you are monitoring competitor prices, stale data means slow reaction time. If you are tracking stock availability, stale data means missed alerts. If you are feeding downstream AI systems, stale data means lower trust in the output.
Your method of access, crawler, scraper, or API, directly affects how well you can handle change over time
Polling vs Push Models
Most scraping and crawling systems rely on polling.
That means revisiting the same pages at fixed intervals, every hour, every day, every week, and checking whether anything changed.
It works, but it is not efficient.
You spend a lot of infrastructure effort rechecking pages that may not have changed at all.
APIs can be better here, at least when the provider supports it. Many APIs offer push-style mechanisms like webhooks or event triggers. Instead of repeatedly checking for updates, the source tells you when something changes.
That reduces redundant traffic and lowers infrastructure load.
In simple terms:
- Polling is “keep checking”
- Push is “tell me when it changes”
The right model depends on the source, the update frequency, and the business value of freshness
Change Detection in Scrapers
Scraping systems usually need their own change-detection layer.
The common approach is diff-based monitoring:
- capture the current snapshot of a page
- compare it to the previous version
- isolate only the fields that changed
- trigger downstream actions when the changes matter
That is how teams support things like:
- real-time price tracking
- stock availability alerts
- new listing detection
- content update monitoring
This is where scraping moves from simple extraction to operational monitoring.
Without diffing, you are just collecting repeated snapshots.
With diffing, you are building a system that notices meaningful change
Delta Crawling for Efficiency
Full-site crawls are expensive. They are also wasteful when only a small percentage of pages change between runs.
That is why delta crawling matters.
Instead of recrawling everything, you store a last-seen signal for each page, usually a hash, timestamp, header value, or known change indicator, and then revisit only the pages that are new or likely to have changed.
That gives you three advantages:
- lower crawl cost
- faster refresh cycles
- less noise in downstream processing
In practice, delta crawling often uses:
- last-seen page hashes
- sitemap updates
- HTTP headers
- canonical signals
- internal prioritization rules
This is one of the highest-leverage improvements in any large-scale crawling setup because it improves freshness without forcing you to brute-force the whole domain every time
What This Means in Practice
Freshness is not just about how often you collect data. It is about how efficiently you detect meaningful change.
That leads to a better decision framework:
- Use APIs when real-time updates and push mechanisms are available
- Use scrapers with diffing when the UI exposes fields the API does not
- Use delta crawling when the page universe is large and only some pages change frequently
Teams that get this right do not just collect web data. They build systems that can tell the difference between noise and a real signal.
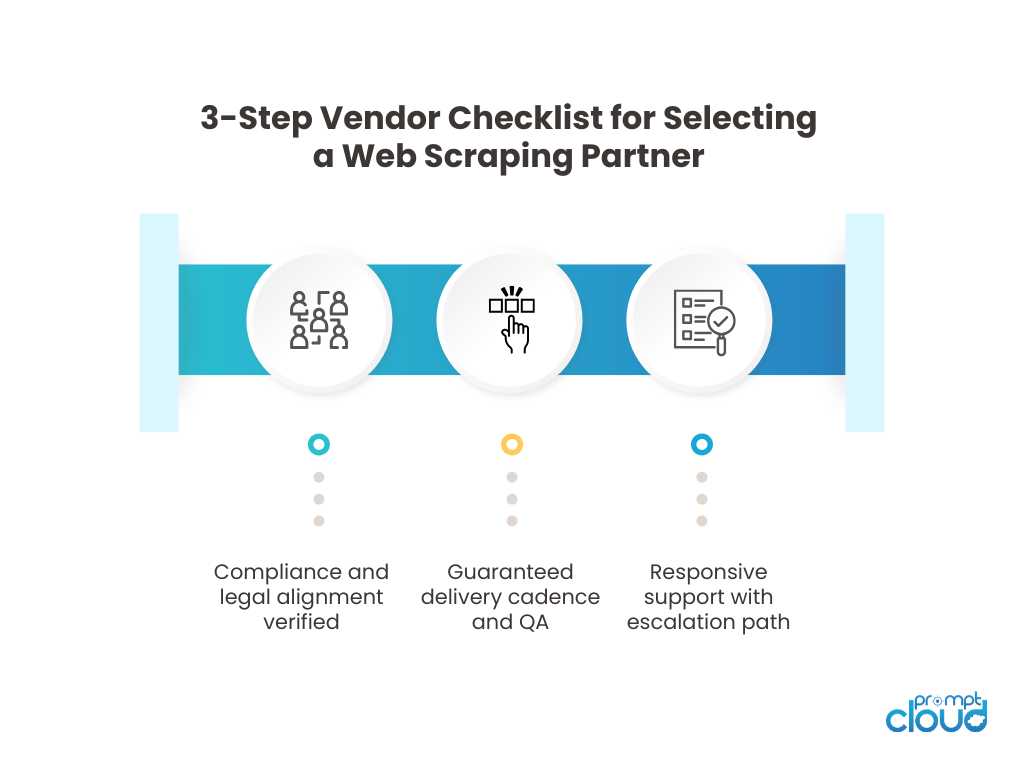
For teams requiring reliable, production-ready web data delivery, enterprise Data-as-a-Service for web data provides structured, SLA-backed datasets without managing scraping infrastructure, QA workflows, and change recovery internally.
No-Code and Low-Code Scraping Options in 2026
Not every web data project starts with an engineering team.
A lot of them start with an analyst, an ops manager, or a growth team trying to answer a simple question fast. That is why no-code and low-code scraping tools have become more common. They reduce setup friction and make small data collection tasks easier to launch.
But ease of setup is not the same as production readiness.
That is the real distinction that matters here.
No-code tools are useful when:
- the site structure is simple
- the extraction logic is straightforward
- the volume is limited
- the data does not change too aggressively
They become much less useful when:
- the site is JavaScript-heavy
- pagination gets complex
- schema drift is frequent
- anti-bot defenses start to matter
- refresh requirements become strict
That is why the real decision is not “Can this tool scrape the page?” It is “Can this setup keep working when the page changes, the scale increases, and the business starts depending on it?”
| Tool | Best For | Handles JS? | Scales to Enterprise? | Limitations |
| Apify | Pre-built scrapers and actor-based workflows for common sources | Yes | Partial | Costs can rise quickly, less control over custom schemas |
| Browse AI | Click-based scraping for simple recurring tasks | Limited | No | Struggles with dynamic sites and complex pagination |
| Octoparse | Visual workflows for analysts and ops teams | Limited | No | Not built for high-frequency or large-scale operations |
| Bardeen / n8n / Make | Workflow automation with light scraping support | Limited | No | Maintenance burden increases when page structures change |
| PromptCloud | Managed web data pipelines with QA, compliance, and SLAs | Yes | Yes | Best suited for teams that need guaranteed delivery, not lightweight hobby use |
When to Use No-Code vs Custom vs Managed
This is the cleaner way to think about the choice.
Use no-code when the site is simple, the volume is low, and the project is exploratory.
Use custom infrastructure when you need full control, complex extraction logic, and your team can absorb ongoing maintenance.
Use a managed service when the data is business-critical, the site environment is unstable, or the operational cost of keeping the pipeline alive is already higher than the subscription you are trying to avoid.
That last point is where a lot of teams miscalculate. They compare vendor cost to build cost. The more relevant comparison is vendor cost versus the full maintenance burden of running scraping infrastructure in production.
That includes:
- selector fixes
- QA checks
- retry handling
- anti-bot adaptation
- compliance reviews
- monitoring and alerts
Once those costs are real, “cheap DIY” usually stops being cheap.
SDKs, Tools, and Ecosystem Considerations
Once you move beyond one-off extraction, tooling starts to shape the entire operating model.
This is not just about which library can make requests or parse HTML. It is about how you manage retries, rendering, orchestration, queues, validation, and long-term maintenance. The ecosystem around the method you choose often matters as much as the method itself.
SDKs and Client Libraries
APIs usually have the cleanest developer experience.
Many official APIs provide SDKs for Python, JavaScript, Java, or other common languages. These often include:
- authentication helpers
- request signing
- pagination handling
- rate-limit support
- response parsing
That makes API integrations easier to build and easier to maintain, as long as the API actually exposes the data you need.
Scraping frameworks solve a different problem. They help manage extraction complexity when you are working directly with websites. Tools like Scrapy and Playwright support request queuing, retries, rendering, extraction logic, and middleware layers. They are not just parsers. They are workflow engines for web data collection.
Crawlers at scale need even more infrastructure around them. Once discovery becomes continuous, teams often need:
- distributed crawl scheduling
- URL deduplication
- frontier prioritization
- queue management
- storage layers for page states and hashes
That is why crawler tooling often expands into orchestration stacks rather than simple scripts
Common Tooling Patterns by Method
A practical way to think about the ecosystem is by what each method usually needs around it.
| Method | Typical Tools | What They Help With |
| API | Official SDKs, REST clients, auth libraries | Authentication, pagination, parsing, rate-limit handling |
| Scraper | Scrapy, Playwright, Puppeteer, BeautifulSoup | Extraction, rendering, retries, selectors, middleware |
| Crawler | Scrapy + Frontera, Apify SDK, Redis queues, message brokers | URL discovery, deduplication, prioritization, distributed scheduling |
The pattern is clear.
APIs are easiest when they fit.
Scrapers require stronger extraction logic and change handling.
Crawlers require stronger orchestration.
That is why the ecosystem choice is never neutral. A team using Playwright on a dynamic site is solving a very different problem from a team using an official product feed API.
Why Ecosystem Fit Matters
A lot of build decisions fail because teams compare methods in isolation.
But a scraper is not just a scraper. It comes with:
- browser automation choices
- retry logic
- queue design
- schema monitoring
- proxy or anti-bot strategy
An API integration is not just an endpoint call. It comes with:
- auth lifecycle management
- rate-limit planning
- version change risk
- field availability constraints
A crawler is not just “follow links.” It comes with:
- URL normalization
- duplicate suppression
- crawl politeness rules
- depth control
- freshness logic
That is why the surrounding ecosystem matters so much. The method you choose defines the maintenance burden you inherit.
Strategic Takeaway
- If the data source is stable, structured, and officially supported, the ecosystem around APIs usually gives you the fastest path to usable data.
- If the data lives only in the interface, the scraping ecosystem becomes your operating layer.
- If the page universe changes constantly, the crawling ecosystem becomes the backbone.
- The wrong tool choice is annoying. The wrong ecosystem choice becomes operational debt.
Quick Start Code Examples
The examples below show the practical difference between a scraper and a crawler-scraper setup. They are not production-ready systems, but they make the roles clearer.
Python: Basic Scraper with Scrapy
import scrapy
class ProductSpider(scrapy.Spider):
name = ‘products’
start_urls = [‘https://example.com/products’]
def parse(self, response):
for product in response.css(‘.product-card’):
yield {
‘name’: product.css(‘h2::text’).get(),
‘price’: product.css(‘.price::text’).get(),
‘stock’: product.css(‘.stock::text’).get(),
}
# Follow pagination
next_page = response.css(‘a.next::attr(href)’).get()
if next_page:
yield response.follow(next_page, self.parse)
This is a basic scraper. It assumes you already know where the relevant pages are and what fields you want. It is efficient when the page structure is stable, but it is also vulnerable to schema drift. If the site renames .product-card, .price, or .stock, the scraper may keep running while returning incomplete or empty data. That is exactly why field-level validation and monitoring matter.
JavaScript: Crawler + Scraper with Playwright for Dynamic Sites
const { chromium } = require(‘playwright’);
async function crawlAndScrape(seedUrl) {
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto(seedUrl);
// CRAWLER: discover all product page URLs
const links = await page.$$eval(‘a[href]’, anchors =>
anchors.map(a => a.href).filter(h => h.includes(‘/product/’))
);
// SCRAPER: extract data from each discovered page
const results = [];
for (const link of links) {
await page.goto(link);
await page.waitForSelector(‘.price’);
const price = await page.$eval(‘.price’, el => el.textContent.trim());
const stock = await page.$eval(‘.stock’, el => el.textContent.trim());
results.push({ url: link, price, stock });
}
await browser.close();
return results;
}
This example shows both layers working together. The crawler discovers product URLs first. The scraper then visits each one and extracts structured fields. Because Playwright renders JavaScript before extraction, this pattern is useful for modern ecommerce pages where the important data is not present in the initial HTML response.
What These Examples Show
The difference is straightforward:
- A scraper-only setup works when the pages are already known and the structure is predictable.
- A crawler + scraper setup is better when you need discovery as well as extraction.
- A browser-rendered workflow becomes necessary when the site loads content dynamically with JavaScript.
Decision Framework and Use Cases
This is where the comparison becomes useful.
Most teams do not struggle because they cannot define a crawler, a scraper, or an API. They struggle because they are trying to choose the right setup for a real operating constraint: missing fields, changing pages, limited engineering time, or the need for reliable refresh cycles.
That means the decision should start with the job, not the tool.
Decision Matrix
Here is the clearest way to decide what belongs in your stack.
| Scenario | Use Crawler | Use Scraper | Use API |
| You do not know where the data is | Yes | No | No |
| You need structured real-time data | No | Maybe | Yes |
| The website has no public API | Maybe | Yes | No |
| You want clean data with low effort | No | No | Yes |
| You need to track changes frequently | Maybe | Yes | Maybe, if webhooks are available |
| The site uses JavaScript heavily | Maybe | Yes, with rendering | Yes |
| You want to minimize legal and operational risk | No | Maybe | Yes |
| You are building an AI training dataset | Yes | Yes, with normalization | If available |
That table makes one thing clear. This is rarely a one-column answer. The right setup often depends on where the gaps are. APIs give structure. Scrapers fill missing fields. Crawlers give you coverage when the page universe itself is moving
A Better Way to Decide
A simpler way to think about it is to ask three questions in order:
1. Is there an API, and does it expose the fields you actually need?
If yes, start there. It will usually be the most stable and efficient option.
2. If there is no usable API, do you already know the relevant pages?
If yes, a scraper may be enough.
3. If you do not know all the relevant pages, or the site changes constantly, do you need discovery as well as extraction?
If yes, you need a crawler plus a scraper.
That order matters because it prevents teams from overbuilding. Many pipelines get harder than they need to be because the team starts with scraping before checking whether structured access already exists.
Sample Use Cases
This is what the decision looks like in practice.
| Use Case | Best Fit |
| Price monitoring across ecommerce sites | Scraper + change detection + null alerts |
| Job listings aggregation | Crawler + scraper combo |
| Product feed ingestion from a marketplace | API, if available, plus scraper for missing fields |
| SEO content mapping and site audit | Crawler |
| News sentiment tracking | Scraper or AI-native crawler |
| Ecommerce comparison tool | API + scraper hybrid |
| AI training dataset collection | Crawler + AI-native extractor with Markdown output |
| Competitor pricing intelligence | Scraper + delta crawling + schema monitoring |
These examples show the pattern clearly.
- If the goal is mapping, crawlers dominate.
- If the goal is field extraction, scrapers dominate.
- If the goal is stable structured delivery, APIs dominate.
- If the goal is production-grade coverage with freshness, hybrids win
What Teams Usually Get Wrong
There are three recurring mistakes here.
Mistake 1: Choosing the API because it feels cleaner
That works only if the API exposes the fields you need. In many real-world projects, it does not.
Mistake 2: Choosing scraping because it feels flexible
That works until the maintenance burden becomes constant.
Mistake 3: Ignoring discovery
That works only as long as the page set stays fixed. If new listings, new SKUs, or new locations appear regularly, the dataset starts decaying unless you crawl for discovery.
This is why the real decision is not “Which method is best?” It is “Which combination gives us the right tradeoff between coverage, freshness, reliability, and maintenance?”
Strategic Takeaway
A clean way to frame the decision is this:
- Choose APIs for structure and reliability
- Choose scrapers for coverage beyond the API
- Choose crawlers when you need continuous discovery
- Choose a hybrid architecture when the data is important enough that blind spots and breakage are not acceptable
That is the point where web data projects stop being scripts and start becoming systems.
Evaluating Managed Solutions?
See how enterprise Data-as-a-Service for web data compares across delivery reliability, QA coverage, refresh workflows, and operational ownership.
Implementation Checklist and Best Practices
Once the architecture is chosen, the next challenge is keeping the output usable.
This is where many web data projects start drifting. The crawler still runs. The scraper still returns records. The API still responds. But the system becomes less trustworthy over time because quality checks, validation logic, and governance guardrails were never built into the workflow.
That is why implementation discipline matters as much as collection logic.
Data Validation and Schema Integrity
If scraped or API-delivered data is going to drive pricing decisions, competitive monitoring, forecasting, or AI workflows, it cannot just be present. It has to be structurally reliable.
That means validating every record at the field level.
The basic checklist looks like this:
- validate required fields on every record
- flag missing or out-of-range values
- set null-rate thresholds for critical fields
- trigger alerts when field types shift silently
That last one matters more than it seems. A page change does not always break the entire record. Sometimes it only corrupts one field. A price becomes text instead of numeric. A stock field disappears. A timestamp changes format. If you do not validate the schema continuously, bad data passes through looking “complete enough” to trust.
The refresh version is right to call out null-rate thresholds here. If a required field crosses something like a 2% null rate, that is not noise. That is usually the earliest warning that the source changed and the pipeline is degrading
Sentiment and Review Data Accuracy
Review and sentiment pipelines need their own discipline because raw text alone is rarely analysis-ready.
If you are working with reviews, comments, or user-generated content, structure matters:
- group feedback by themes such as shipping, quality, pricing, or support
- normalize sources across marketplaces and platforms
- apply consistent sentiment logic across all inputs
- monitor anomalies when review volume or polarity shifts suddenly
This matters because sentiment systems often fail in a softer way than pricing systems. They do not always “break.” They slowly become inconsistent. And once the schema across sources becomes uneven, trend analysis becomes unreliable.
That is why normalization is not optional for review-driven use cases. It is the only way to make cross-source signals comparable
Legal and Compliance Guardrails
Collection logic is only one part of a production-grade web data system. Governance matters too.
At a minimum, a production implementation should:
- respect robots.txt and the platform’s terms of service
- avoid login-gated or paywalled content without explicit permission
- anonymize PII when working with user-generated content
- document what is being collected and why
- log user agents, request times, and response status codes for auditability
Teams often treat these as legal cleanup items for later. That is a mistake. They affect operations too. A lack of logging makes failures harder to diagnose. A lack of collection documentation increases internal risk. A lack of data-handling rules creates downstream problems once compliance teams get involved.
If the data matters enough to use in production, it matters enough to govern properly.
Practical Implementation Mindset
The pattern across all of this is simple.
Do not ask only:
- Can we collect the data?
Also ask:
- Can we trust the schema next month?
- Can we explain how the data was collected?
- Can we detect silent degradation early?
- Can we prove the output is still fit for decision-making?
That is the difference between a scraping setup and a production data pipeline.
Costs, Risk, and Practical Tradeoffs
Choosing between a crawler, scraper, or API is not just a technical decision. It is also a budgeting decision, a maintenance decision, and a risk decision.
This is where a lot of teams misjudge the tradeoff.
They compare build cost to vendor cost and stop there. That is too narrow. The real cost includes engineering time, infrastructure overhead, ongoing fixes, QA effort, compliance reviews, and the business impact of bad or stale data.
Cost Components to Model
A useful way to think about total cost is to break it into four buckets.
Infrastructure
- proxies and IP rotation
- headless browsers and renderers
- queueing, storage, and warehouse layers
- monitoring, logging, and alerting systems
Engineering
- initial build for crawlers and scrapers
- selector maintenance after site changes
- schema validation and QA workflows
- refresh logic, retries, and orchestration
Licenses and Access
- API subscription tiers
- overage pricing
- third-party tooling
- managed orchestration or data delivery contracts
Governance and Security
- compliance review
- source documentation
- audit logging
- internal approvals for business-critical use cases
This is why “we built it in-house” is often not the same as “it is cheaper.” The first version may be cheaper. The operating model usually is not
Cost Shape by Approach
Each method has a different cost profile.
| Approach | Typical Cost Profile | What Drives Cost | Hidden Costs to Plan For |
| Crawler | Medium upfront, medium ongoing | URL discovery, storage, deduplication | Crawl politeness rules, temporary bans, robots compliance |
| Scraper | Medium upfront, higher ongoing | Selector fixes, rendering, retries | Silent field shifts, QA, schema drift, change detection |
| API | Lower upfront, predictable ongoing | Tiered pricing, usage caps, auth lifecycle | Missing fields, coverage gaps, version changes |
| Managed Feed | Subscription, lower internal engineering | SLAs, QA, delivery formatting | Vendor dependence, contract constraints |
This table highlights the real pattern.
APIs usually look cheapest early because the build path is short.
Scrapers usually look flexible early but become more expensive over time because the maintenance curve is steeper.
Crawlers sit somewhere in the middle, especially when the page universe is large and discovery has to stay current.
Managed feeds often look expensive only when compared against initial build effort. When compared against the full maintenance burden of a working production stack, the economics often shift
Legal and Operational Risk
Cost is only one part of the decision. Risk matters too.
There are three recurring categories of risk here.
1. Terms and robots rules
Crawlers and scrapers need to respect source rules and access patterns. APIs encode access rules more directly, but they introduce dependence on a provider’s policy and product decisions.
2. Data quality risk
Page changes can silently break field mappings. That means the business risk is not always downtime. Sometimes it is bad data flowing through with no obvious failure signal.
3. Business continuity risk
APIs can deprecate versions or tighten rate limits. Crawlers can get blocked after traffic spikes. Scrapers can degrade after design changes. Vendors can change terms, pricing, or product scope.
This is why the best architecture is often not the one with the lowest initial effort. It is the one with the most acceptable failure mode.
Practical Budgeting Tips
A few principles improve cost efficiency fast:
- tie refresh frequency to business value
- monitor high-value fields more aggressively than low-value ones
- use delta crawling instead of full recrawls where possible
- store both raw and cleaned data so reprocessing stays possible
- start with one category or market before expanding the footprint
- budget for QA and maintenance from day one, not after the first break
That last point matters. If QA and monitoring are not in the plan, the cost model is incomplete.
Strategic Takeaway
The wrong question is:
- What is the cheapest way to get the data?
The better question is:
- What is the cheapest way to keep the data usable, fresh, and trustworthy over time?
That is the decision that separates experiments from production systems.
A Realistic Hybrid Architecture in Action
The clearest way to understand why teams end up combining crawlers, scrapers, and APIs is to look at a real operating scenario.
Imagine a retailer that needs to track price and availability across multiple marketplaces and competitor sites in different regions.
This is not a one-method problem.
The business requirement already tells you that:
- the page universe is large
- some data changes frequently
- some fields may be available via official feeds
- some important signals may only exist in the page interface
- the output needs to be reliable enough to trigger downstream action
That is exactly where hybrid architecture starts making sense
The Requirement
A realistic setup often looks like this:
- track price and stock for thousands of SKUs across multiple sites
- refresh high-value items in near real time
- detect changes quickly and notify downstream systems
- keep legal and compliance risk documented and controlled
None of those requirements is unusual. But together, they rule out simplistic setups.
The Chosen Architecture
A working hybrid model usually splits responsibility across layers.
1. Discovery with a crawler
Start with sitemaps, known listing hubs, and category pages. Use the crawler to maintain a URL frontier, prioritize important sections, and continuously discover new or changed pages.
2. Extraction with scrapers
For each relevant product page, extract the fields that matter: price, currency, stock status, SKU, timestamp, promo badges, or other page-level signals. If the site uses client-side rendering, add a rendering layer or intercept network calls.
3. Structured access through APIs where available
If a marketplace or platform exposes an official feed or product API, use it for the stable baseline fields. Then keep the scraper for the UI-level fields the API omits.
4. Change detection layer
Version each page or field set, compute diffs, and only trigger downstream actions when key values change. This keeps the signal high and avoids flooding the system with repetitive snapshots.
5. Quality assurance and governance
Validate field types on every record, run daily spot checks, maintain anomaly alerts, log request metadata, and keep a source register with review dates.
That combination is what makes the system resilient. It spreads risk instead of concentrating it in one brittle method
Why Hybrid Wins
The reason hybrid architectures keep showing up is simple. They solve the tradeoffs better than pure approaches.
Coverage and freshness
APIs give you official fields fast. Scrapers capture the fields the APIs do not expose. Crawlers make sure you discover new or orphaned pages.
Control and resilience
If an API tightens rate limits, the scraper can still preserve coverage for the highest-priority items. If a layout changes, the API may still provide stable baseline data while selectors get fixed.
Cost balance
You do not need the same refresh cadence everywhere. High-value targets can be monitored more frequently, while lower-value targets can be batched more efficiently. Hybrid design lets you optimize where it matters instead of overengineering the whole footprint.
What Results Look Like
When this architecture works well, the outcomes are operational, not theoretical.
- price deltas are detected quickly for priority SKUs
- stockout alerts reach downstream systems in time to matter
- QA reports show schema pass rates and anomaly trends
- business teams receive clean structured feeds, not raw page dumps
- audit trails exist for what was collected, when, and why
That is the real difference between a script and a production pipeline. A script fetches data. A hybrid architecture makes that data usable under real business constraints
Community and Industry Practices
Definitions and architecture diagrams are useful, but they only get you so far. If you want a realistic view of how crawlers, scrapers, and APIs work in the wild, it helps to look at the broader ecosystem.
What shows up repeatedly is this: real-world systems rarely stay pure. At scale, the lines between crawling, scraping, enrichment, and delivery start to blur. That is not because teams are confused. It is because production needs force hybrid behavior.
Open Crawls and Data Archives
One of the clearest examples is Common Crawl.
It is a large public web crawl initiative that continuously collects and publishes massive portions of the web for public use. Its relevance here is not just scale. It shows what crawling looks like when discovery itself becomes infrastructure. The output is not a ready-made business dataset. It is a large discovery and archival layer that other systems can build on top of.
That distinction matters. Common Crawl is a reminder that crawling is about coverage and indexing first. Extraction and downstream usefulness come later.
Frameworks and Libraries in Use
The tooling ecosystem also reflects how the methods converge in practice.
Scrapy is a good example. It is often described as a scraping framework, but in reality it handles both crawling and scraping in one orchestration model. It supports asynchronous requests, pipelines, middleware, and large-scale extraction workflows.
Apache Nutch is more crawler-centric. It is built for web-scale discovery and indexing tasks, with a modular architecture suited for large crawl systems.
StormCrawler pushes further into streaming and low-latency crawling patterns, showing how crawl infrastructure changes once freshness matters more than batch collection.
Playwright and Puppeteer represent another shift. They are not just “scraping tools.” They are browser automation layers that became essential because modern websites increasingly rely on JavaScript-heavy rendering.
And now there is a newer layer as well.
Tools like Firecrawl and Scrapfly represent the rise of AI-native extraction workflows. Their value is not just collection. It is converting messy web content into cleaner, model-friendly outputs that work better in AI and RAG pipelines.
That is the key pattern across the ecosystem: the market keeps building around the operational gaps that pure methods leave behind
Respecting robots.txt at Scale
Another place where industry practice matters is robots.txt.
At a small scale, teams often treat it as a courtesy file. At production scale, mature systems treat it as a baseline operational control.
A few practices show up repeatedly:
- fetch and cache robots.txt rather than requesting it constantly
- default conservatively when the file cannot be reliably read
- record the access state at crawl time for auditing and troubleshooting
- pair robots handling with broader source and compliance documentation
This matters because production-grade crawling is not just about whether a parser can read the rules. It is about whether the system behaves predictably when source behavior changes.
The refresh document correctly points out an important norm here: when robots.txt returns 5xx errors, mature systems often default to disallow until recovery rather than assuming access is safe. That is a strong operational signal. It shows that responsible crawling at scale is designed around risk containment, not just data acquisition
What These Industry Patterns Tell You
The ecosystem is telling the same story from multiple angles.
- Crawling becomes infrastructure when discovery matters continuously
- Scraping becomes orchestration when extraction has to survive page changes
- APIs stay attractive when structured access is available, but they rarely eliminate the need for everything else
- AI workflows are creating a new normalization layer between raw extraction and usable downstream data
That is why the most useful takeaway is not “which framework is best.” It is understanding that the tooling market itself has evolved to solve the weak spots of each method.
In other words, the industry has already moved past one-tool thinking.
Our View: What Actually Works in Practice
Here is the pattern we keep seeing.
Teams usually begin by looking for a single answer. They want the cleanest tool, the fastest setup, or the cheapest route to data. So they start with one method and expect it to cover the full job.
That works for a while.
Then the gaps show up.
An API looks ideal until it leaves out the fields that actually matter. A scraper looks flexible until the site changes and the maintenance burden starts eating engineering time. A crawler helps with discovery, but by itself it does not give the business the structured output it needs.
That is why one-method thinking rarely survives production.
What actually works in practice is a layered model.
Use APIs where they provide stable, structured access. Use scrapers where the page exposes signals the API does not. Use crawlers when discovery is part of the problem and the page universe keeps changing.
Then add the layers most teams underestimate:
- schema monitoring
- QA checks
- freshness logic
- governance
- fallback handling
Because that is the real job.
The job is not “collect data from the web once.”
The job is “keep high-value web data usable, current, and trustworthy over time.”
That is where most DIY systems start to strain. Not at the first extraction. At the point where:
- selectors drift
- anti-bot behavior changes
- refresh requirements tighten
- business teams start relying on the output
- leadership expects the feed to keep working without surprises
At that point, the architecture matters more than the script.
This is also why many teams eventually shift from asking, “Can we scrape this?” to asking, “Who should own the operational burden of keeping this alive?”
That is the inflection point.
If the data is low-volume, low-risk, and exploratory, internal tooling can make sense.
If the data is business-critical, multi-source, and expected to stay reliable under change, the operating model becomes the real decision. That is where managed data delivery starts to make economic sense, not because crawling or scraping are impossible to build, but because maintaining quality, freshness, and stability becomes the actual cost center
Ready to evaluate? Compare enterprise Data-as-a-Service for web data options →
Need reliable data without managing crawlers, scrapers, and APIs separately?
Get clean, structured web data delivered on your cadence from a managed pipeline built around your specific sources and schema.
• No contracts. • No credit card required. • No scraping infrastructure to maintain.
Explore More Here
- APIs often leave out key data points, so that real-time tracking becomes impossible. Scrapers break the moment a layout changes.
- To understand how web sentiment translates into action, this market sentiment breakdown shows how reviews and reactions become business signals.
Frequently Asked Questions
1. What is the difference between a crawler and a scraper?
A crawler moves through websites to discover and collect URLs. Its job is coverage and discovery.
A scraper works on those pages and extracts specific fields such as prices, titles, ratings, reviews, or job details. In simple terms, crawlers find pages, scrapers pull data from them.
2. Can I use a scraper on a site that already has an API?
Yes, but only when the API does not expose everything you need.
If the API already provides the right fields with the right freshness, it is usually the better starting point because it is cleaner and more stable. Scrapers make sense when the UI exposes data the API omits, such as promo badges, rendered prices, shelf position, or other page-level signals.
3. What is the best way to detect data changes?
The best approach depends on the source.
For crawlers and scrapers, diff-based monitoring is usually the practical choice. You compare the latest snapshot with the previous one and isolate only the fields that changed. For APIs, webhooks or modification timestamps can simplify this if the provider supports them.
If you are working at scale, delta crawling is usually the more efficient way to keep refresh costs under control.
4. How does robots.txt affect my data access?
robots.txt tells crawlers which parts of a site should or should not be accessed. It is a baseline operational control for responsible crawling.
It is not the same thing as legal authorization, but ignoring it increases the risk of throttling, IP blocks, and compliance issues. Mature crawling systems treat robots.txt as part of standard operating discipline, not as an optional extra.
5. When should I combine crawlers, scrapers, and APIs?
In most production environments.
Use a crawler when discovery matters, use a scraper when extraction is needed from the page, and use an API when structured access is available. The combination becomes especially useful when you need broad coverage, frequent refreshes, and resilience against gaps in any single method.
6. Is web scraping legal in 2026?
It depends on what you scrape, how you scrape, and where you operate.
Publicly available data is often treated differently from login-gated, copyrighted, or personal data. But legality is not the only issue. Terms of service, rate limits, robots rules, and data protection requirements all matter. If the project is business-critical or large-scale, legal review should be part of the operating model, not something added later.
7. What is schema drift in web scraping?
Schema drift happens when a website changes its structure and your extraction logic quietly stops working as expected.
The scraper may still run, but fields start returning nulls, wrong values, or incomplete records. That is what makes it dangerous. It often fails silently. The right defense is field-level validation, null-rate alerts, spot checks, and schema monitoring over time.
8. Can I build a data pipeline for AI training using crawlers and scrapers?
Yes, and many teams do.
But in 2026, the key issue is not just collecting the data. It is normalizing it into formats AI systems can use reliably. That is why AI-native extraction layers and LLM-ready outputs such as Markdown or chunked JSON are becoming more important. A crawler and scraper can collect the content, but a normalization layer is often what makes the pipeline usable for AI.
9. What is the difference between a scraping API and a data API?
A data API is provided by the source platform itself and gives you officially exposed structured fields.
A scraping API is usually a third-party service that helps you collect data from websites by handling things like rendering, proxies, or request infrastructure. One gives you source-approved structured access. The other helps you operate the scraping layer more efficiently. They solve different problems.
10. How often should I re-crawl a site?
It depends on how fast the source changes and how valuable freshness is to the business.
Price and stock tracking may need refreshes every 15 to 60 minutes for priority items. News or listings may need hourly monitoring. Static pages may only need weekly checks. The smarter model is not “crawl everything more often.” It is to use delta crawling, prioritization, and change detection so refresh effort matches business value.
We now have the full article in the correct outline order from the refresh doc. The only pieces left outside the body are the FAQ schema, Article schema, and publishing checklist from the refresh file.















