




The technology revolution has transformed the world significantly over the last 15 years. Information Technology has connected the world and enabled sharing, storing and accessing information on the internet like never before. This has created an ocean of structured as well as unstructured data available on the web. With the help of right data scraping tools, you can unravel amazing insights which can aid important business decision and strategic moves. This ocean of information, or Big Data as we call it, is simplified by categorizing it into 4 dimensions, commonly known as the 4 pillars of big data or 4 Vs of big data.
The 4 Vs of Big Data Decoded
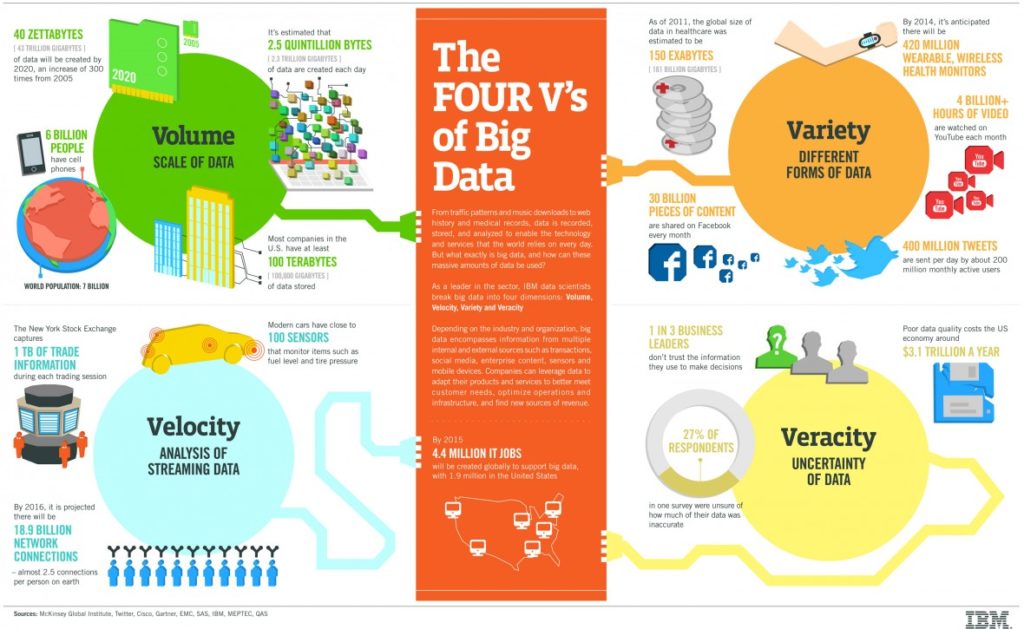
The 4 Vs of BIG Data stands for Volume, Variety, Velocity and Veracity. Let us discuss each of one of these in detail.
1. Data Volume
As the name suggests, the main characteristic of big data is its huge volume collected through various sources. We are used to measuring data in gigabytes or terabytes. However, big data volume created so far is in Zettabytes, which is equivalent to a trillion gigabytes. 1 zettabyte is equivalent to approximately 3 million galaxies of stars. This will give you an idea of a colossal volume of data being available for business research and analysis.
Take any sector and you can comprehend that it is flooded with data. Travel, education, entertainment, health, banking, shopping–you name it and you have it. Almost every industry today is reaping or trying to reap the benefits of big data. Data is collected from diverse sources which include business transactions, social media, sensors, surfing history, etc.
With every passing day, data is growing exponentially. According to experts, the amount of big data in the world is likely to get doubled in every two years. As the volume of the data is growing at the speed of light, traditional database technology will not suffice the need for efficient data management limited to storage and analysis. The need of the hour will be a large scale adoption of data management tools like Hadoop and MongoDB. These tools use distributed systems to facilitate storage and analysis of this enormous big data across various databases. This information explosion has opened new doors of opportunities in the modern age.
2. Data Variety
Big data is collected and created in a variety of formats and sources. It includes structured data as well as unstructured data like text, multimedia, social media, business reports, etc.
- 1. Structured data such as bank records, demographic data, inventory databases, business data, product data feeds have a defined structure and can be stored and analyzed using traditional data management and analysis methods.
- 2. Unstructured data includes captured like images, tweets or Facebook status updates, instant messenger conversations, blogs, videos uploads, voice recordings, sensor data. These types of data do not have any defined pattern. Unstructured data is most of the time reflection of human thoughts, emotions and feelings which sometimes would be difficult to be expressed using exact words.
As the saying goes, “A picture paints a thousand words”, one image or video which is shared on social networking sites and applauded by millions of users can help in deriving some crucial inferences. Hence, it is the need of the hour to understand the non-verbal clues of unstructured data.
One of the main objectives of big data is to collect all this unstructured data and analyze it using the appropriate technology. Data crawling, also known as web crawling, is a popular technology used for systematically browsing the web pages. There are algorithms designed to reach the maximum depth of a page and extract useful data worth analyzing.
Variety of data definitely helps to get insights from different set of samples, users and demographics. It helps to bring different perspective to the same information. It also allows analyzing and understanding the impact of different form and sources of data collection from a ‘larger picture’ point of view.
For instance, in order to understand the performance of a brand, traditional surveys are the primary channel of data collection. However, you can obtain real time feedback through various other forms like Facebook activity, product review blogs, and updates posted by customers on merchant and marketplace, in lot lesser time. Variety of data definitely gives a clearer perspective to your business decision-making process.
3. Data Velocity
In today’s fast-paced world, speed is one of the key drivers for success in your business as time is equivalent to money. In such scenarios, it becomes vital to collect and analyze a vast amount of disparate data swiftly, in order to make well-informed decisions in real-time. Think about it, low velocity of even high quality of data may hinder the decision making of a business.
The general definition of velocity is ‘speed in a specific direction’. In 4 Vs of big data, velocity is the speed or frequency at which data is collected in various forms and from different sources. The frequency of specific data collected via various sources defines the velocity of that data. In other terms, Data Velocity it is data in motion to be captured and explored. It ranges from batch updates to periodic to real-time flow of the data.
You can relate data velocity with the amount of trade information captured during each trading session in a stock exchange. Imagine a video or an image going viral in the blink of an eye to reach millions of users across the world. Big data technology allows you to process the real-time data, sometimes without even capturing in a database.
Streams of data are processed and databases are updated in real-time, using parallel processing of live streams of data. Data streaming helps extract valuable insights from incessant and rapid flow of data records. A streaming application like Amazon Web Services Kinesis is an example of an application that handles the velocity of data.
The higher the frequency of data collection in your big data platform in a stipulated time period, the more likely it will enable you to make an accurate decision at the right time.
4. Data Veracity
The fascinating trio of volume, variety, and velocity of data brings along a mixed bag of information. It is quite possible that such huge data may have some uncertainty associated with it. You will need to filter out clean and relevant data from the big data. In order to make accurate decisions, the data you have used as an input should be appropriately compiled, confirmed, validated, and made uniform.
There are various reasons for data contamination, like data entry errors or typos (mostly in structured data), wrong references or links, junk data, pseudo data, etc. The enormous volume, wide variety, and high velocity, in conjunction with high-end technology, hold no significance if the data collected or reported is incorrect. Hence, data trustworthiness (in other words, quality of data) holds utmost importance in the big data world.
In automated data collection, analysis, report generation, and decision-making process, it is inevitable to have a foolproof system in place to avoid any lapses. Even the most minor of slippage at any stage in the big data extraction process can cause an immense blunder. It is always advisable that you have two different methods and sources to validate credibility and consistency of the data, to avoid any bias.
It is not only about accuracy post data collection but also about determining right source and form of the data. Required amount or size of the extracted data, and the right method of analysis, all play a vital role in procuring required results. It will definitely allow you to position yourself in the market as a reliable authority and help to you to attain greater heights of success.
Thoughts on 4 V’s of Big Data
These 4 Vs of big data are four pillars lending stability to the giant structure of big data and adding precious 5th “V, that is, Data Value, to the insights procured for smart decision making. Web scraping service, like PromptCloud helps enterprises meet their quality data requirements by providing data scraping solution to them.
How will you be utilizing these 4 Vs of big data in the near future? Do write in to us and let us know your thoughts.
Frequently Asked Questions
What are the 4 V’s of big data?
Big Data is characterized by four key dimensions known as the 4 Vs of big data: Volume, Velocity, Variety, and Veracity. Understanding these dimensions helps in grasping the complexity and potential of Big Data in various applications.
- Volume: This refers to the sheer amount of data generated and stored. In the context of Big Data, volume signifies the vast quantities of data produced by businesses, machines, individuals, and technology every second. The challenge and opportunity lie in the ability to store, process, and analyze these massive datasets to extract valuable insights.
- Velocity: Velocity denotes the speed at which new data is generated and the pace at which it moves. In today’s digital world, data flows at an unprecedented speed from various sources like social media feeds, mobile devices, and Internet of Things (IoT) sensors. The ability to process and analyze data in real-time or near-real-time allows organizations to make timely decisions.
- Variety: This aspect highlights the different types of data available, from structured data like databases to unstructured data such as text, images, and videos. The variety in Big Data encompasses diverse formats and sources, including emails, social media posts, and business transactions. Handling this variety involves extracting insights from all types of data, irrespective of their format or source.
- Veracity: Veracity concerns the quality and reliability of data. Given the vast amounts of data collected, ensuring that the data is accurate, meaningful, and trustworthy is crucial. Veracity challenges include inconsistencies, incompleteness, and biases in data, which can affect the insights derived from Big Data analysis.
Together, the 4 V’s of Big Data represent the challenges and opportunities inherent in dealing with large-scale, complex datasets. Addressing these dimensions effectively is essential for leveraging Big Data to its full potential, enabling better decision-making and strategic advantages for businesses and organizations.
What are the 5 V’s of big data?

Image Source: https://www.scaler.com/
The 5 V’s of Big Data describe the key characteristics that make big data analytics a complex and insightful field. The original four V’s are Volume, Velocity, Variety, and Veracity, and they have been expanded to include a fifth V, Value:
- Volume: The vast amounts of data generated every minute from various sources, including social media platforms, business transactions, and IoT devices. The challenge lies in how to store, manage, and extract meaningful insights from these large datasets.
- Velocity: The speed at which new data is produced and the rate at which it must be processed. Velocity refers to the need for real-time or near-real-time processing and analysis to make timely decisions.
- Variety: The different forms of data, from structured data in databases to unstructured text, images, videos, and more. This diversity requires effective methods to capture, store, and analyze data across formats.
- Veracity: The reliability and accuracy of data. With the immense volume and variety of data, ensuring high-quality, clean, and trustworthy data is essential for meaningful analytics.
- Value: The most critical V, which focuses on turning big data into valuable insights that can drive decision-making and strategic initiatives. Value emphasizes the importance of extracting actionable and impactful information from the complex datasets characterized by the other four V’s.
Together, the 5 V’s of Big Data outline the framework for understanding the complexities of managing and leveraging large datasets. Addressing these five dimensions enables organizations to harness the power of big data analytics, driving innovation and gaining competitive advantages.
What are the 4 V’s of data and why they are impacting Fintech?
The 4 Vs of big data—Volume, Velocity, Variety, and Veracity—are critical characteristics that describe the challenges and opportunities of managing large datasets. Their influence is particularly profound in the FinTech industry, transforming how financial services are delivered and consumed. Here’s how each V impacts FinTech:
- Volume: The massive amounts of data generated by transactions, user interactions, and third-party services provide FinTech companies with a goldmine of information. Analyzing this data allows for the identification of trends, customer behavior patterns, and opportunities for new financial products or services. Volume enables FinTech firms to leverage data analytics for personalized customer experiences, risk assessment, and predictive modeling.
- Velocity: In the fast-paced world of finance, the speed at which data is generated and processed is crucial. Real-time processing of financial transactions, market data, and consumer behavior allows FinTech companies to offer timely, contextually relevant services. This includes real-time fraud detection, dynamic pricing of assets, and instant payment processing, which are essential for maintaining competitiveness and customer satisfaction in the digital age.
- Variety: Financial data comes in numerous forms—structured data from traditional databases, unstructured data from social media, text from news articles, and more. This diversity necessitates advanced data integration and analysis techniques. FinTech companies use this variety to gain a comprehensive understanding of market dynamics and consumer needs, informing the development of innovative financial products that cater to a broad spectrum of customers.
- Veracity: The accuracy and reliability of data are paramount in FinTech. Decisions regarding credit scoring, fraud detection, and investment strategies depend on high-quality data. Veracity challenges FinTech companies to establish robust data management and verification processes, ensuring that the data guiding financial decisions and customer interactions is trustworthy.
Impact on FinTech: The 4 V’s significantly influence the FinTech industry by driving innovation, enabling personalized financial solutions, and ensuring the integrity and efficiency of financial services. By effectively managing and leveraging the 4 Vs of big data, FinTech companies can enhance decision-making, optimize operations, and deliver superior customer experiences. This ability to harness the power of big data is what sets leading FinTech firms apart, allowing them to redefine the landscape of financial services.















