Technologies We Use
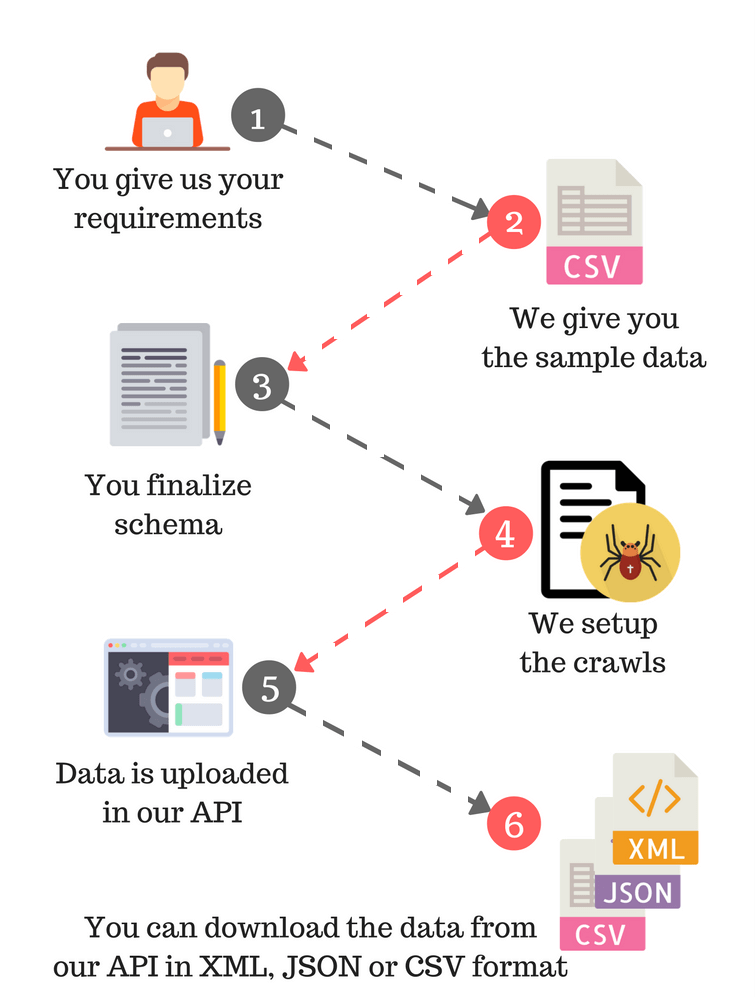
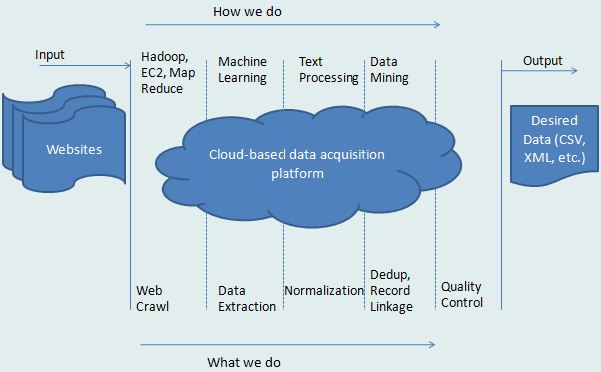
Our service has been designed taking into account the various use cases and the non-uniform formats on the web. It deep crawls the web and uses certain machine learning components for extraction. Client specific normalization too can be added to the pipeline.
Built on Open-Source
It all started with open source technologies, and PromptCloud has gradually built on top of these technologies thus designing its own state-of-the-art crawler that can take care of scale and failovers.
What Our Clients Say
With PromptCloud, it became evident that focus on quality and timeliness were paramount. They have helped us grow our business without compromises.

Dani Ariss
Managing Director and Founder, Dandan
The team at PromptCloud has done an excellent job in providing me with a custom set of scraping data from multiple websites. I would have no hesitation in recommending them.

Aaron Burraston
Proprietor, Agentkit
PromptCloud was by far best data provider we have worked with. They really understand the domain space, and have worked very diligently to meet our requirements in record time.

Pasha Riger
CTO, Miner Labs