




Q&A sites like Quora are online socialization hubs for digital citizens worldwide to ask, answer, and discuss the most prominent issues, doubts, and topics. Extracting large-scale data from these online Q&A platforms can be useful to marketers and data scientists alike as it’s not only a multilingual Q&A website but also a social network in itself with many niche influencers. Let’s learn in detail on how to scrape Quora.
Use Cases of Quora Scraping
To emphasize why scraping Quora is of interest to marketers and businesses, let’s take a quick peek at 4 vital Quora stats:
- Quora is home to 300 million monthly active users.
- On average users spend 4+ minutes on Quora every day.
- From traffic volumes, it is the 80th most popular website in the world.
- Google search shows as many as 65 million results for Quora[dot]com.
#1: Sentiment analysis
You can scrape questions related to politics, brands, stock market etc. to perform sentiment analysis.
#2: NLP & machine learning
Most of the users on Quora are real users, who ask questions and answers on the platform in their day-to-day lingo. This could be very useful for training ML models, and natural language processing (NLP).
#3: Intelligent influencer marketing
Quora allows you to run ads but you can also target influencers in a particular niche to promote your brand. Scraping questions, user profiles etc from a specific niche would enable you to partner with the right influencers who have real authority to promote your brands.
#4: Lead generation & content marketing
Questions asked by users can help you identify if they are your target leads. For instance, if you’re an IT services company then people who ask questions like “How much it cost to develop an e-commerce website?” are your potential leads. Insights gained from scraping Quora Q&As can also be your gateway to a stellar content marketing strategy.
How to Scrape Quora Q&A
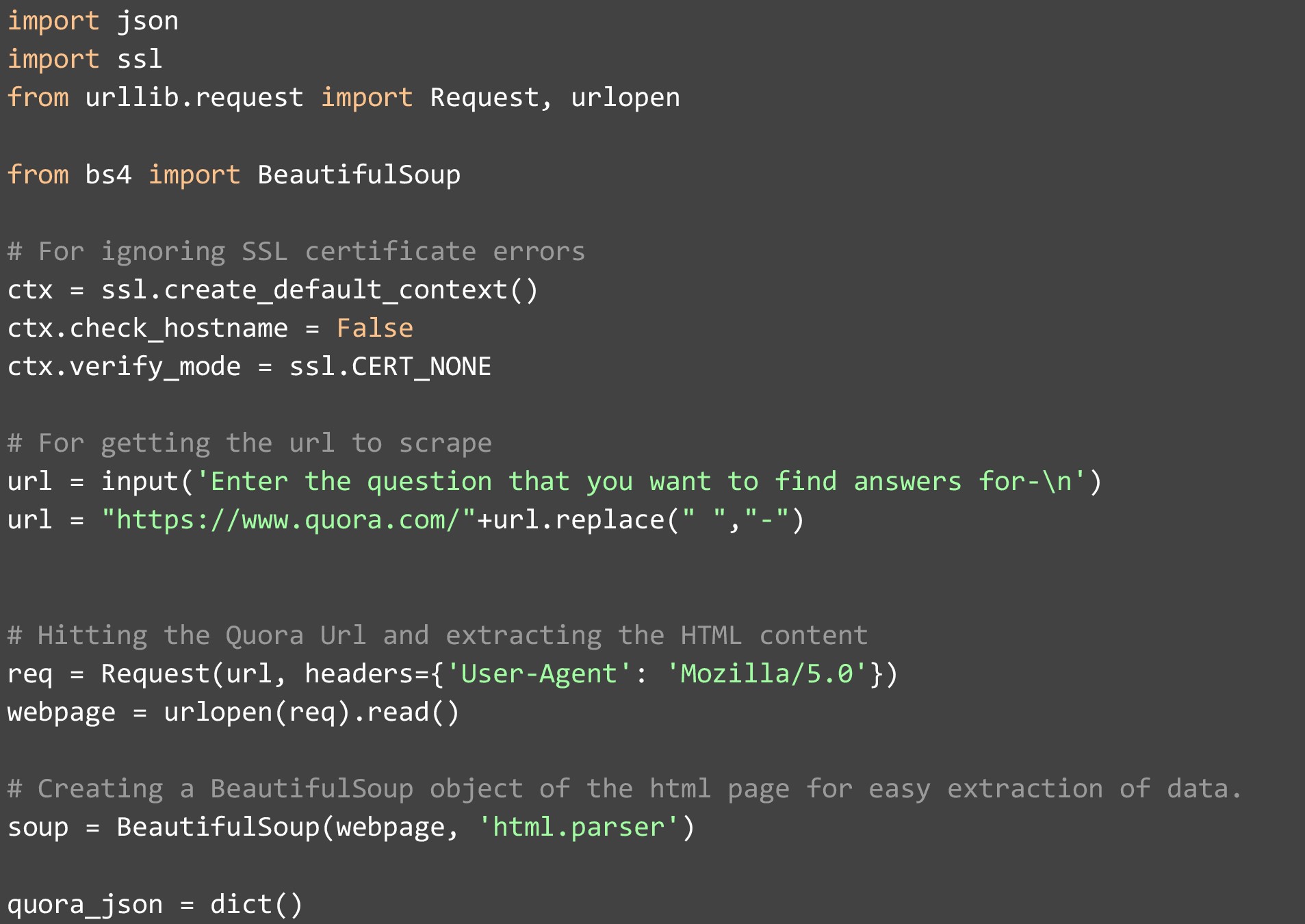
We shall be using Python3.7 and the BeautifulSoup library to crawl Quora data and save it in a JSON file. Using this code, you would be able to scrape and extract Quora answers and questions easily. The only other thing that you will need is a decent text editor. We have used PyCharm, which is a full-blown IDE, but you can also use Atom since it comes with multiple plugins and is more lightweight. Hope this helps you understand how to scrape Quora in detail.
So to start with the code, we begin by importing the libraries that we will be needing, both internal and external. Once done, we need to make sure that we set the SSL certificate’s verify-mode to “CERT_NONE”, and check hostname to False, to avoid getting SSL certificate errors when we start scraping data. Once this is done, our setup is complete, and we can accept a question from the user. For this demo, we supplied the following value when this question was asked.

We create the Quora URL using this question. This string manipulation is required since Quora formats its URLs in this manner.
Once we have created the URL, we use the inbuilt Request function from urllib to hit the webpage and make sure that we add Firefox in the header, so that the website is not able to track that we are accessing it from a piece of code. This part is important since most websites block scrapers and if you miss the header. Your IP will likely be blocked, and further actions can be initiated against you.
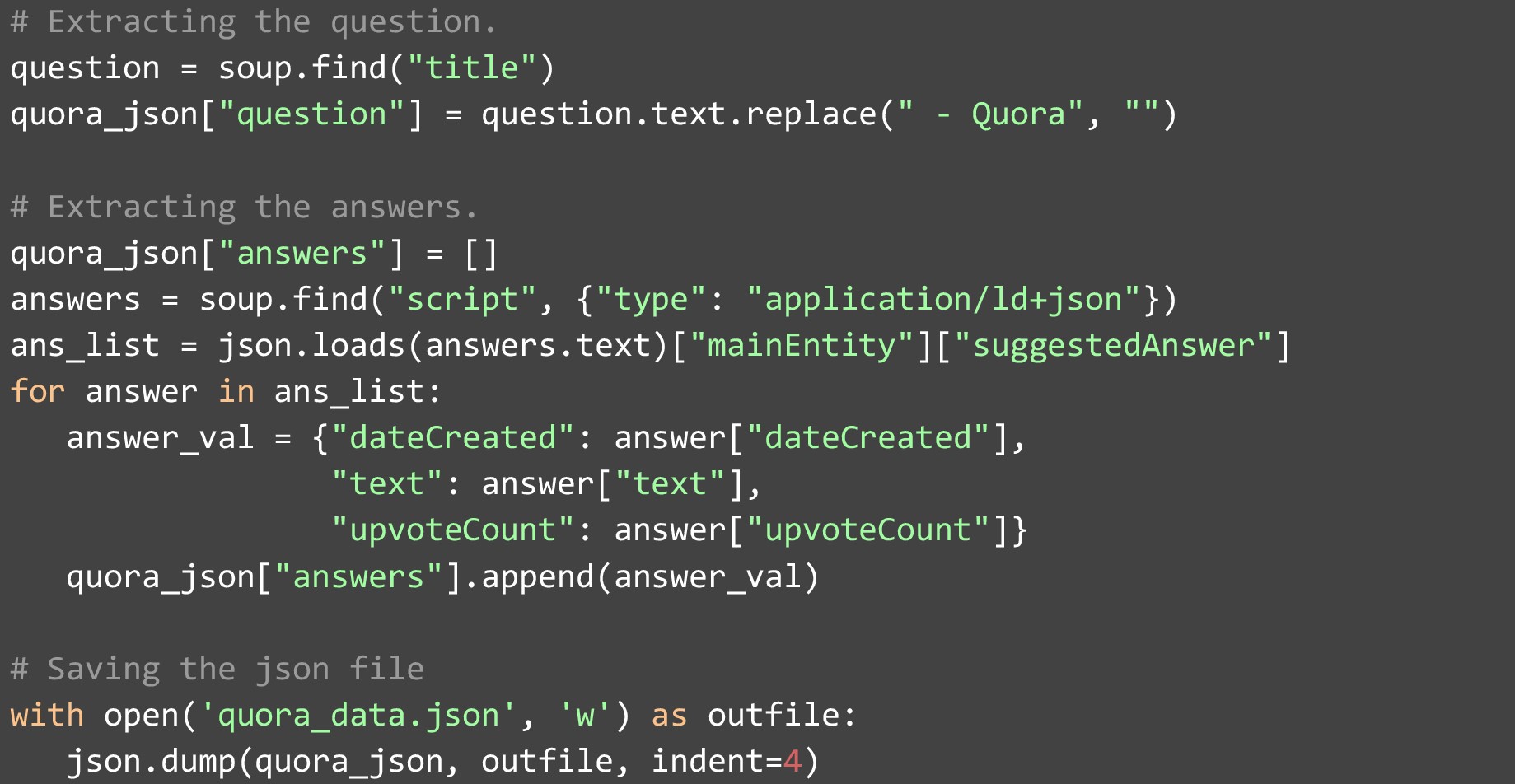
After we have obtained the webpage in HTML format and stored it in a variable. We need to convert it to a BeautifulSoup object so that it is easier to parse and extract data from. Then extract the question on the webpage from the first “title” tag on the page. We need to remove “ – Quora” from it since all titles come with the following string. Scraping the answer is slightly more complicated. You need to extract the JSON stored in the element of type “script” having the value for “type” as “application/ld+json”. Once you have obtained this JSON, you shall find a list of answers with multiple fields. While few fields are given for each answer. We have extracted the most important ones:
- The date on which the answer was written
- The answer itself
- The number of upvotes that it received
Once the data extraction is completed, we can append it to a list of answers and save the final list in a JSON file.
Understanding The Output
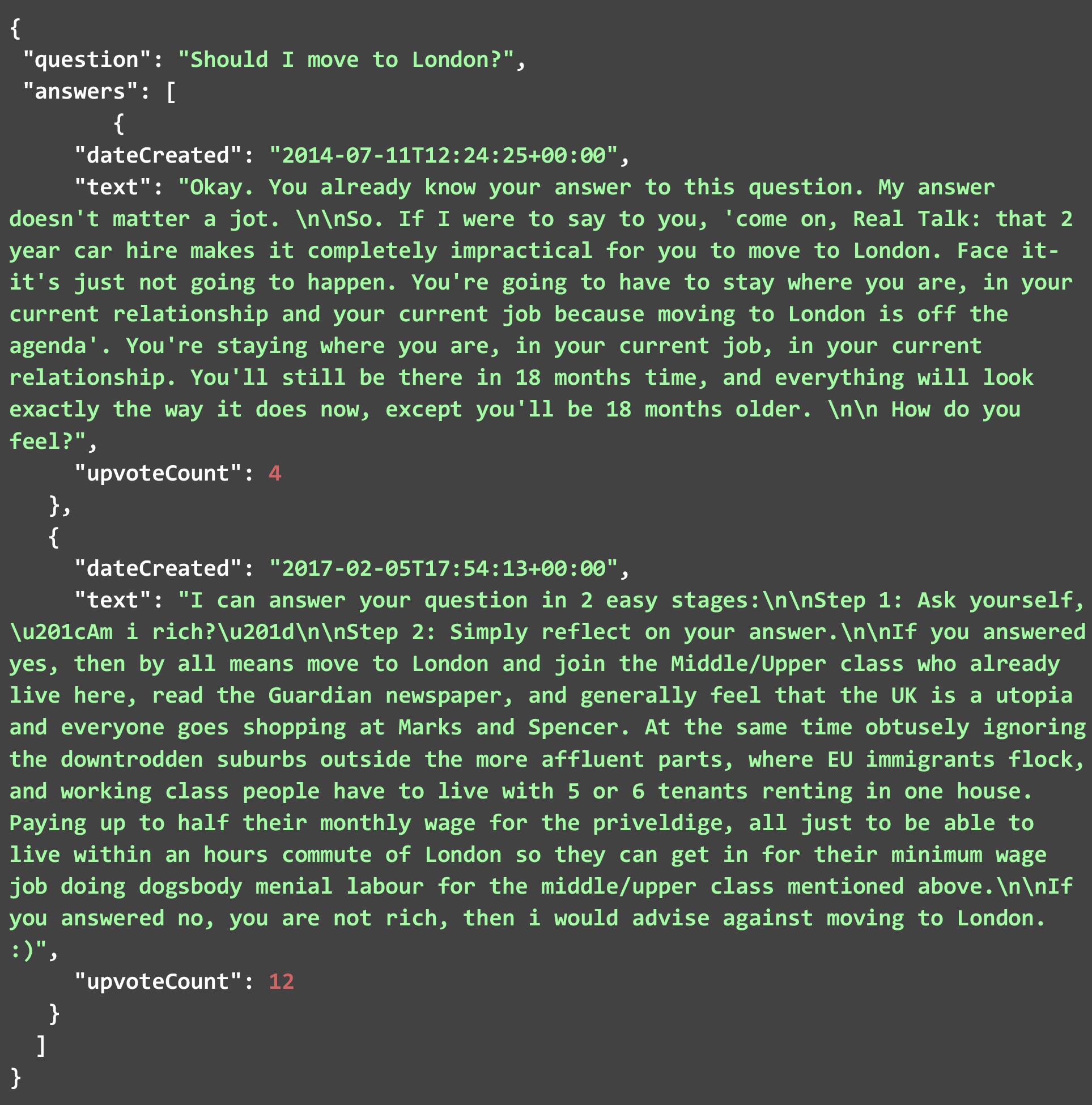
The JSON file given below contains some of the answers that were scraped from the HTML page when we ran the code with the question mentioned in the last section. As you can see, the JSON has two fields, the question, and the answers. Each answer consists of the three parameters that we mentioned earlier. While the number of answers scraped for this particular question were many. We have only shown a few of them below. Feel free to run the code yourself and check all the answers to this question, or any other.
Limitations Of Scraping Content From Quora
While this might look like a perfect solution to finding the answers to any question on Quora. Like every other piece of DIY code, it comes with multiple limitations. One important aspect is that not every question you type will exist in Quora. You will have your code break every time you type a question that does not exist. At the same time, you might need to type your question multiple times to find which version exists. A better implementation would be to find the question that matches the one you entered closest.
Another aspect to consider is one related to the qualms of scraping Quora data and how you choose to use it. You need to make sure that you go through the robot.txt file and scrape data, and use it accordingly. Any commercial use of this code can lead you to legal issues. And using the data collected for anything other than research purposes may also cause problems.
In Summary
Social media is a goldmine for user-generated data. Scraping Quora Q&As is like gaining access to the pain points of your customers, the likes/dislikes/interests of your audience. Using an intelligent scraping tool takes away all your pains associated with scraping Quora data. Once you’ve extracted your data you can run neural networks-powered ML algorithms and gain business-critical insights.















