



Table of Contents
show
How to Use Web Scraper Chrome Extension to Extract Data
Web scraping is becoming a vital ingredient in business and marketing planning regardless of the industry. There are several ways to crawl the web for useful data depending on your requirements and budget. Did you know that your favorite web browser could also act as a great web scraping tool?
You can install the Web Scraper extension from the chrome web store to make it an easy-to-use data scraping tool. The best part is, that you can stay in the comfort zone of your browser while the scraping happens. This doesn’t demand many technical skills, which makes it a good option when you need to do some quick data scraping. Let’s get started with the tutorial on how to use the web scraper chrome extension to extract data.
About the Web Scraper Chrome Extension
Web Scraper is a web data extractor extension for chrome browsers made exclusively for web data scraping. You can set up a plan (sitemap) on how to navigate a website and specify the data to be extracted. The scraper will traverse the website according to the setup and extract the relevant data. It lets you export the extracted data to CSV. Multiple pages can be scraped using the tool, making it even more powerful. It can even extract data from dynamic pages that use Javascript and Ajax.
What You Need
- Google Chrome browser
- A working internet connection
A. Installation and setup
- Web scraper chrome extension by using the link.
- For web scraper chrome extension download click on “Add”
Once this is done, you are ready to start scraping any website using your chrome browser. You just need to learn how to perform the scraping, which we are about to explain.
B. The Method
After installation, open the Google Chrome developer tools by pressing F12. (You can alternatively right-click on the screen and select inspect element). In the developer tools, you will find a new tab named ‘Web scraper’ as shown in the screenshot below.
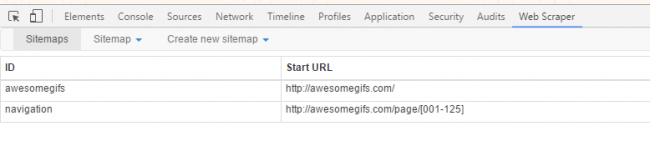
Now let’s see how to use this on a live web page. We will use a site called www.awesomegifs.com for this tutorial. This site contains gif images and we will crawl these image URLs using our web scraper.
Step 1: Creating a Sitemap
- Go to https://www.awesomegifs.com/
- Open developer tools by right-clicking anywhere on the screen and then selecting inspect
- Click on the web scraper tab in developer tools
- Click on ‘create new sitemap’ and then select ‘create sitemap’
- Give the sitemap a name and enter the URL of the site in the start URL field.
- Click on ‘Create Sitemap’
To crawl multiple pages from a website, we need to understand the pagination structure of that site. You can easily do that by clicking the ‘Next’ button a few times from the homepage. Doing this on Awesomegifs.com revealed that the pages are structured as https://awesomegifs.com/page/1/, https://awesomegifs.com/page/2/, and so on. To switch to a different page, you only have to change the number at the end of this URL. Now, we need the scraper to do this automatically.
To do this, create a new sitemap with the start URL as https://awesomegifs.com/page/[001-125]. The scraper will now open the URL repeatedly while incrementing the final value each time. This means the scraper will open pages starting from 1 to 125 and crawl the elements that we require from each page.
Step 2: Scraping Elements
Every time the scraper opens a page from the site, we need to extract some elements. In this case, it’s the gif image URLs. First, you have to find the CSS selector matching the images. You can find the CSS selector by looking at the source file of the web page (CTRL+U). An easier way is to use the selector tool to click and select any element on the screen. Click on the Sitemap that you just created, and click on ‘Add new selector’.
In the selector id field, give the selector a name. In the type field, you can select the type of data that you want to be extracted. Click on the select button and select any element on the web page that you want to be extracted. When you are done selecting, click on ‘Done selecting’. It’s easy as clicking on an icon with the mouse. You can check the ‘multiple’ checkbox to indicate that the element you want can be present multiple times on the page and that you want each instance of it to be scrapped.
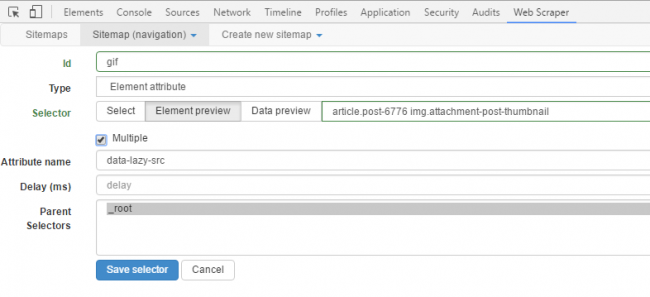
Now you can save the selector if everything looks good. To start the scraping process, just click on the sitemap tab and select ‘Scrape’. A new window will pop up which will visit each page in the loop and crawl the required data. If you want to stop the data scraping process in between, just close this window and you will have the data that was extracted till then.
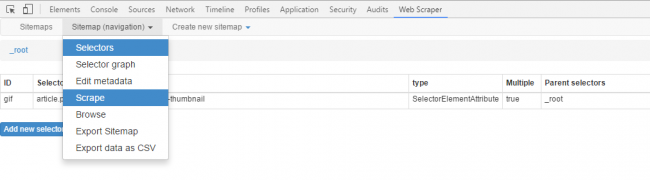
Once you stop scraping, go to the sitemap tab to browse the extracted data or export it to a CSV file. The only downside of such data extraction software is that you have to manually perform the scraping every time since it doesn’t have many automation features built in.
If you want to crawl data on a large scale, it is better to go with a data scraping service instead of such free web scraper chrome extension data extraction tools like these. In the second part of this series, we will show you how to make a MySQL database using the extracted data. Stay tuned for that!
Frequently Asked Questions (FAQs)
How do I use Google Chrome Web scraper?
Using a web scraper in Google Chrome typically involves utilizing browser extensions designed for scraping tasks. These extensions can simplify the process of extracting data from websites without needing to write any code. Here’s a general guide on how to use a basic web scraping extension in Google Chrome. While specific features might vary depending on the extension you choose, the overall process remains similar.
Step 1: Choose and Install a Web Scraping Extension
- Find a Web Scraper Extension: Open the Google Chrome Web Store and search for web scraping extensions. Some popular options include Web Scraper (web-scraper.io) and Data Miner.
- Install the Extension: Choose an extension that suits your needs, click on “Add to Chrome”, and then click “Add extension” in the popup to install it.
Step 2: Open the Target Website
- Navigate to the website you want to scrape in Google Chrome. Make sure the content you want to scrape is visible on the page.
Step 3: Launch the Web Scraper
- Click on the extension icon in the Chrome toolbar to open its interface. If it’s your first time using the extension, there might be a tutorial or introduction. It’s beneficial to go through this to understand the tool’s features.
Step 4: Create a New Sitemap
- A sitemap within web scraping context is essentially a plan that tells the scraper what pages to scrape and what data to collect.
- Depending on the extension, you’ll either select “Create new sitemap” or a similar option. You may need to give it a name and optionally the starting URL (the page you’re currently on).
Step 5: Select Data to Scrape
- You’ll then enter the selection phase, where you can click on elements of the webpage you want to scrape. This could include text, links, images, etc.
- As you select elements, the extension might offer options to refine your selection, ensuring you’re capturing the right data. You can specify if you’re collecting text, URLs, or other attributes.
Step 6: Define Data and Patterns
- For complex pages or to capture multiple items (like a list of products), you might need to define patterns or use the tool’s pattern detection to ensure it recognizes similar elements across the page or multiple pages.
Step 7: Run the Scraper
- Once you’ve defined what data to scrape and where to find it, run the scraper. The extension will navigate the pages and collect the data according to your sitemap.
Step 8: Export the Data
- After the scraper completes its task, you can usually export the collected data in various formats, such as CSV or Excel, for further analysis or use.
Does Google have a web scraper?
Google’s core technologies, including its search engine, do involve sophisticated web crawling and indexing mechanisms that collect information from web pages to build and update its search index. However, these technologies are proprietary and serve Google’s primary function of web indexing for search, not as a standalone web scraping service for user-directed data extraction.
People often confuse Google’s search capabilities with web scraping, but the purposes and methodologies are distinct:
- Google Search Engine: It crawls the web to index content and make it searchable for users. It’s not designed for extracting and downloading specific data from websites into structured formats for users.
- Web Scraping Tools: These are designed to extract specific data from web pages and websites, allowing users to save the data in structured formats such as CSV, Excel, or JSON for analysis, reporting, or other uses.
For individuals or businesses looking to scrape web data, there are numerous third-party tools and services available, ranging from simple browser extensions to sophisticated web scraping platforms. These tools allow users to select specific data points on web pages and extract this information systematically. Some popular tools include BeautifulSoup and Scrapy (for Python), Puppeteer (for Node.js), and various browser-based scraping extensions.
While Google does not offer a web scraping tool, it provides APIs such as the Google Sheets API or Google Custom Search JSON API, which can be used to integrate search results or manipulate Google Sheets programmatically for various automated tasks. These APIs, while not scraping tools in the traditional sense, can sometimes serve similar purposes by allowing structured access to data for integration into applications, albeit within Google’s terms of service and usage limits.
Does Google ban web scraping?
Google, like many other website operators, has measures in place to protect its services from automated access, including web scraping, that violates its terms of service or negatively impacts its infrastructure. Google’s primary objective in these measures is to ensure the integrity and availability of its services for all users, as well as to protect the copyrighted content it hosts.
Google’s Stance on Scraping:
Google’s Terms of Service do not explicitly mention “web scraping,” but they include clauses that prohibit automated access to their services without permission. For example, the terms may restrict the use of robots, spiders, or scraping tools to access or extract data from their services. The intention here is to prevent excessive use of resources, protect against spam and abuse, and ensure the security and privacy of its users’ data.
Detection and Enforcement:
Google employs various detection mechanisms to identify and block behavior it deems abusive or against its terms of service. This includes:
- Rate Limiting: Implementing rate limits on how many requests an IP address can make in a certain timeframe.
- CAPTCHAs: Presenting challenges to verify whether the user is human.
- Blocking IP Addresses: Temporarily or permanently banning IP addresses that exhibit suspicious behavior.
Consequences of Violation:
If Google detects unauthorized scraping activity, it might temporarily block the offending IP addresses from accessing its services. In more severe cases, or if the scraping causes significant strain on Google’s infrastructure or involves the extraction of sensitive or protected data, legal action could be taken.
Ethical and Legal Considerations:
While scraping public data for personal use or research might seem harmless, doing so without permission on a scale that impacts service availability or violates copyright laws can have legal repercussions. It’s essential to:
- Review and adhere to the terms of service of the website.
- Ensure that your data collection methods do not harm the website’s service or access protected or private data without consent.
- Consider the ethical implications of collecting and using scraped data, especially personal information.
What is web scraper extension?
A web scraper extension is a browser add-on designed to simplify the process of extracting data from web pages. These extensions are particularly useful for individuals and professionals who need to collect information from the internet without writing custom code for web scraping. Here’s a closer look at what web scraper extensions do, how they work, and their typical features:
Functionality
- Automated Data Extraction: Web scraper extensions automate the process of collecting data from websites. Users can select specific data they wish to extract, such as product details, prices, contact information, or any textual content displayed on a webpage.
- Point-and-Click Interface: Most of these extensions provide a user-friendly interface that allows users to select the data they want to scrape simply by clicking on the elements within the web page.
- Data Organization: The extracted data can be compiled into structured formats like CSV, Excel, or JSON, making it easy to analyze, share, or import into other applications.
- Pagination Handling: Advanced scraper extensions can navigate through pagination, allowing for the extraction of data from multiple pages of search results or listings automatically.
How They Work
- Installation: Users first add the extension to their browser from the browser’s extension store or marketplace.
- Configuration: Upon navigating to a target web page, the user activates the extension and selects the data they wish to extract. This often involves defining a “sitemap” or plan that outlines which pages to visit and what data to collect.
- Data Selection: The user typically enters a point-and-click mode where they can select specific page elements from which data should be extracted. The extension may offer options to refine the selection to ensure accuracy.
- Running the Scraper: With the data points and pages defined, the user instructs the extension to start scraping. The tool then automatically visits the pages and extracts the specified data.
- Exporting Data: Once the scraping process is complete, the user can export the collected data into a preferred format for further use.
What is the best Chrome extension for scraping?
Selecting the “best” Chrome extension for web scraping largely depends on your specific needs, such as the complexity of the data you wish to extract, your technical expertise, and whether you prefer a free or paid tool. However, as of my last update, here are some widely recommended web scraping extensions for Chrome, each known for their unique strengths:
Web Scraper (Web Scraper IO)
- Features: Offers a sitemap-based approach to plan and execute your scraping, allowing you to navigate through websites and select data to be scraped with a visual interface.
- Pros: User-friendly, capable of handling multi-page scraping and sitemaps, and provides data export in CSV format.
- Cons: May require a learning curve to fully utilize its sitemap feature. Doesn’t handle dynamic content as efficiently as some other tools.
- Best For: Users looking for a free, versatile tool for comprehensive web scraping projects that involve navigating through multiple pages or websites.
Data Miner
- Features: Boasts a large library of pre-made scraping recipes created by the community, which you can use to scrape common websites without setting up your own scraping patterns.
- Pros: Easy to use with a point-and-click interface, extensive recipe library for popular sites, and good customer support.
- Cons: The most powerful features and larger recipe executions require a paid subscription.
- Best For: Non-technical users and professionals who need to scrape data from popular platforms without delving into the intricacies of web scraping.
ParseHub
- Features: A powerful tool that can handle websites with JavaScript, AJAX, cookies, and redirects, using machine learning technology to navigate and extract data.
- Pros: Intuitive interface, capable of dealing with complex and dynamic websites, offers cloud-based services for running scrapes.
- Cons: Free version has limitations on the number of pages you can scrape; full features require a paid subscription.
- Best For: Users with complex scraping needs, including scraping dynamic content and requiring scheduled scrapes.
Octoparse
- Features: Provides both a cloud-based solution and a desktop application, with a focus on scraping complex websites and offering built-in workflows for common scraping tasks.
- Pros: No coding required, handles both static and dynamic websites, and offers data export in various formats.
- Cons: While there’s a free version, more advanced features and higher usage limits are behind a paywall.
- Best For: Businesses and individuals who need a robust, professional-grade scraping solution for intensive data extraction projects.
Choosing the Right Extension
When selecting a web scraping extension, consider:
- Ease of Use: If you’re not technically inclined, look for an extension with a user-friendly interface and good documentation or support.
- Functionality: Ensure the extension can handle the specific requirements of your project, such as scraping dynamic content or managing complex navigation patterns.
- Cost: Evaluate whether the free features are sufficient for your needs or if you’re willing to pay for advanced capabilities.
Remember, when using any web scraping tool, it’s important to respect the target website’s terms of service and adhere to ethical and legal guidelines regarding data collection and use.
How does the Web Scraper Chrome Extension handle pagination on websites that dynamically load more content as the user scrolls?
The Web Scraper Chrome Extension addresses pagination on websites with dynamic content loading, such as infinite scrolling, by allowing users to create selectors that simulate the action of scrolling or navigating through pagination links. This functionality enables the extension to interact with the website as a user would, ensuring that all content, even that which loads dynamically as the user scrolls, can be captured and extracted.
Can the Web Scraper Chrome Extension be used to scrape data from websites that require user login before accessing certain content?
For websites requiring user login, the Web Scraper Chrome Extension offers a workaround by allowing the user to manually navigate to the website and log in through their browser before initiating the scraping process. Once logged in, the extension can access and scrape data from pages that require authentication. However, users must ensure they have the necessary permissions to scrape data from these secured areas to comply with the website’s terms of service and legal considerations.
What are the limitations of the Web Scraper Chrome Extension in terms of the volume of data it can efficiently handle without performance issues?
Regarding performance and data volume limitations, the Web Scraper Chrome Extension is designed to efficiently handle a considerable amount of data. However, the performance might be impacted as the volume of data increases or when scraping very complex websites. The extension runs in the browser and relies on the user’s computer resources, which means that very large scraping tasks could slow down the browser or lead to memory issues. For extensive scraping needs, it might be beneficial to consider server-based scraping solutions that are designed to handle large volumes of data more robustly.















